
腾讯的老哥在社区中开源了 golang lockfree 的库,本人看到该库的设计很有意思,就参与该项目的开发改进,已经是该项目的 contributor 了. 该库使用 golang 开发,相比社区中其他 golang lockfree 来说,api 更友好,性能更好,其提供了各种的休眠阻塞策略,避免过度的 spin 引发 cpu 开销升高。
项目地址: https://github.com/bruceshao/lockfree
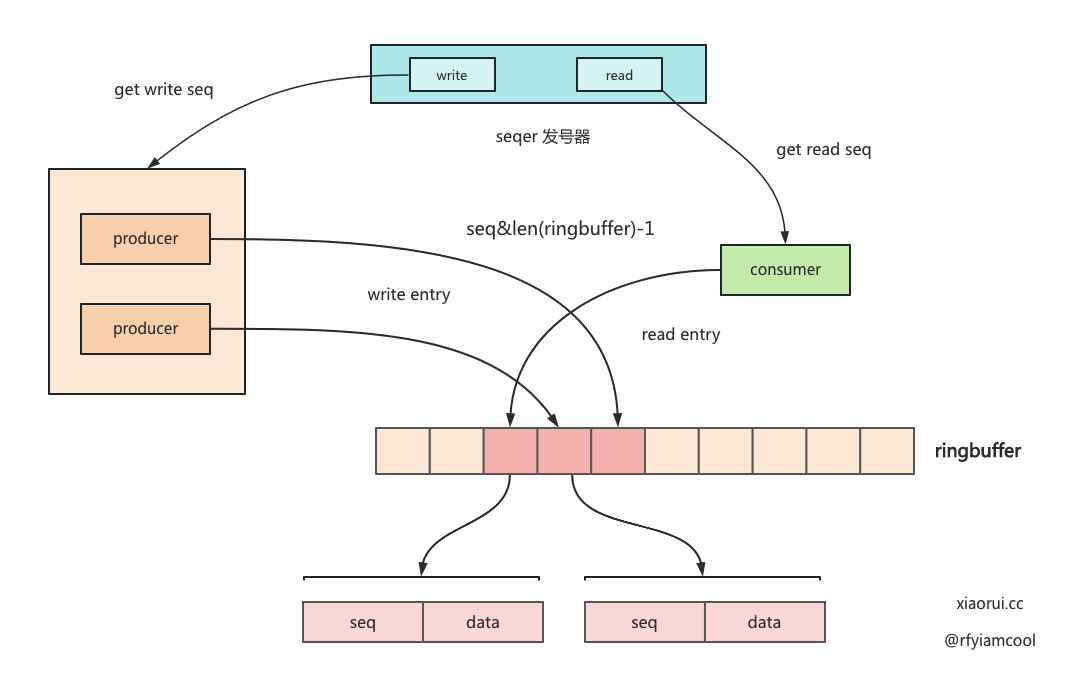
lockfree queue 的基本原理还是好理解的,设计上借鉴参考了无锁队列的标杆 java disruptor,另外在代码中很多性能的优化点也是参照了 java disruptor。
lockfree queue 无锁的设计大概流程是这样,首先需要一个原子递增的发号器。生产者写数据时,先拿到一个 seq 序号,通过位运算找到 ringbuffer 的位置,如何 ringbuffer 还有空余空间,只需写到 ringbuffer 对应位置即可,如果空间已满,则需要等待。而读取数据只需判断对应结构的 seq 跟 consumer seq 是否一致即可。
什么场景下需要使用 lockfree 无锁队列?
就 go lockfree 和 disruptor 的设计来说,首先对性能很敏感,另外 consumer 为计算密集型或非阻塞操作,比如你使用 disruptor 队列做通知队列,consumer 收到事件后,进行 http 请求操作,这显然是无法体现 lockfree 队列的性能。反而因为 consumer 消费过慢,引发 producer 和 consumer 的 spin 自旋开销。
我的理解,性能敏感且 consumer 处理的足够快的场景可以使用 lockfree 无锁队列。
lockfree vs channel 的性能表现
如下所述.
- 在goroutine数量比较小时,lockfree 和 channel 性能差别不明显;
- 当goroutine打到一定数量(大于1000)后,lockfree无论从时间还是 QR 都远远超过chan;
一句话,大多数场景不需要 lockfree 无锁队列,除非追求机制的性能体验。平时用 golang channel 足矣了,如果 golang channel 出现并发的性能瓶颈,其实也可以变通下,切分多个 channel 来分担 mutex 锁竞争冲突,以提高 channel 的读写并行吞吐。
lockfree 如何使用 ?
该库的使用很简单。先实例化 lockfree 队列对象,然后就可并发写,读则是注册一个回调方法,lockfree consumer 消费数后会回调注册的方法。
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
"github.com/bruceshao/lockfree"
)
var (
goSize = 10000
sizePerGo = 10000
total = goSize * sizePerGo
)
func main() {
// lockfree计时
now := time.Now()
// 创建事件处理器
handler := &eventHandler[uint64]{
signal: make(chan struct{}, 0),
now: now,
}
// 创建消费端串行处理的Lockfree
lf := lockfree.NewLockfree[uint64](
1024*1024,
handler,
lockfree.NewSleepBlockStrategy(time.Millisecond),
)
// 启动Lockfree
if err := lf.Start(); err != nil {
panic(err)
}
// 获取生产者对象
producer := lf.Producer()
// 并发写入
var wg sync.WaitGroup
wg.Add(goSize)
for i := 0; i < goSize; i++ {
go func(start int) {
for j := 0; j < sizePerGo; j++ {
err := producer.Write(uint64(start*sizePerGo + j + 1))
if err != nil {
panic(err)
}
}
wg.Done()
}(i)
}
// wait for producer
wg.Wait()
fmt.Printf("producer has been writed, write count: %v, time cost: %v \n", total, time.Since(now).String())
// wait for consumer
handler.wait()
// 关闭Lockfree
lf.Close()
}
type eventHandler[T uint64] struct {
signal chan struct{}
gcounter uint64
now time.Time
}
func (h *eventHandler[T]) OnEvent(v uint64) {
cur := atomic.AddUint64(&h.gcounter, 1)
if cur == uint64(total) {
fmt.Printf("eventHandler has been consumed already, read count: %v, time cose: %v\n", total, time.Since(h.now))
close(h.signal)
return
}
if cur%10000000 == 0 {
fmt.Printf("eventHandler consume %v\n", cur)
}
}
func (h *eventHandler[T]) wait() {
<-h.signal
}
go lockfree 源码分析
实例化 lockfree 对象
type Lockfree[T any] struct {
writer *Producer[T]
consumer *consumer[T]
status int32
}
func NewLockfree[T any](capacity int, handler EventHandler[T], blocks blockStrategy) *Lockfree[T] {
// 重新计算正确的容量
capacity = minSuitableCap(capacity)
// 发号器
seqer := newSequencer(capacity)
// 实例化 ringbuffer,队列是环形数组
rbuf := newRingBuffer[T](capacity)
// 实例化定义消费者
cmer := newConsumer[T](rbuf, handler, seqer, blocks)
// 实例化生产者
writer := newProducer[T](seqer, rbuf, blocks)
return &Lockfree[T]{
writer: writer,
consumer: cmer,
status: READY,
}
}
启动 lockfree
Start() 用来启动 lockfree,对于 consumer 来说会启动一个消费协程消费 ringbuffer 队列中的数据,而对于 producer 来说,只是把 status 只为 running 即可。
func (d *Lockfree[T]) Start() error {
// 保证并发安全
if atomic.CompareAndSwapInt32(&d.status, READY, RUNNING) {
// 启动消费者
if err := d.consumer.start(); err != nil {
// 启动失败,重置 status
atomic.CompareAndSwapInt32(&d.status, RUNNING, READY)
return err
}
// 启动生产者
if err := d.writer.start(); err != nil {
// 恢复现场
atomic.CompareAndSwapInt32(&d.status, RUNNING, READY)
return err
}
return nil
}
return fmt.Errorf(StartErrorFormat, "Disruptor")
}
发号器
lockfree queue 通常都需要一个原子发号器的,其实就是递增的 uint64。lockfree 库里为了避免并发下带来的伪共享问题,使用填充的方式让 uint64 独占缓存行 cache line。
type sequencer struct {
wc *cursor
rc uint64 // 读取游标,因为该值仅会被一个g修改,所以不需要使用cursor
capacity uint64
}
type cursor struct {
// cache line 填充,这里适配了 64 和 128 字节的缓存行。
p1, p2, p3, p4, p5, p6, p7 uint64
v uint64
p9, p10, p11, p12, p13, p14, p15 uint64
}
func newSequencer(capacity int) *sequencer {
return &sequencer{
wc: newCursor(),
rc: 1,
capacity: uint64(capacity),
}
}
// nextRead 获取下个要读取的位置
// 使用原子操作解决data race问题
func (s *sequencer) nextRead() uint64 {
return atomic.LoadUint64(&s.rc)
}
func (s *sequencer) readIncrement() uint64 {
return atomic.AddUint64(&s.rc, 1)
}
生产者
初始化 producer 对象
type Producer[T any] struct {
seqer *sequencer
rbuf *ringBuffer[T]
blocks blockStrategy
capacity uint64
status int32
}
func newProducer[T any](seqer *sequencer, rbuf *ringBuffer[T], blocks blockStrategy) *Producer[T] {
return &Producer[T]{
seqer: seqer,
rbuf: rbuf,
blocks: blocks,
capacity: rbuf.cap(),
status: READY,
}
}
func (q *Producer[T]) start() error {
if atomic.CompareAndSwapInt32(&q.status, READY, RUNNING) {
return nil
}
return fmt.Errorf(StartErrorFormat, "Producer")
}
写数据
先获取写的 seq 序号,判断 ringbuffer 是否可写,如可写,直接写入到对应的 ringbuffer 位置即可,不可写则需要自旋判断,直到可写为止。
func (q *Producer[T]) Write(v T) error {
if q.closed() {
return ClosedError
}
// 获取写的位置
next := q.seqer.wc.increment()
for {
r := atomic.LoadUint64(&q.seqer.rc) - 1
// 判断 ringbuffer 是否已满,consumer 的 seq + ringbuffer 长度为判断条件.
if next <= r+q.capacity {
// 可以写入数据,将数据写入到指定位置
q.rbuf.write(next-1, v)
// 释放,防止消费端阻塞
q.blocks.release()
return nil
}
// 队列已满,则暂时让出 cpu 资源,等待 runtime 下次调度,如果 consumer 消费不及时,那么这里会引发自旋问题。
runtime.Gosched()
// 再次判断是否已关闭
if q.closed() {
return ClosedError
}
}
}
如果消费者处理速度慢一些,那么队列会无空闲位置,也就是已满。那么生产者无法 write,内部会触发 runtime.Gosched 退让资源和切出调度,如果一段时间内未消费,生产者必然会因为这个 spin 操作引发 cpu 开销飙高。
所以,上面一直有说 lockfree / disruptor 的使用场景,消费者要足够的快。
runtime.Gosched 是暂停当前的 G,然后把该 G 放到队列尾部,重新切 g0 选择新的 G 进行调度。这个设计很好,社区中一些开源库有使用 atomic cas 实现的锁,当无法 cas 时,会执行 gosched 切换调度。
但就 lockfree 场景来说,如果 consumer 消费的不够快,那么 producer write 失败后会一直频繁的 gosched。这时候 runq 只有 producer,runtime goready 调度起来后又无法写,这个操作一直循环下来会使 cpu 飙高满载。
所以我这边又做了进一步的调整,写入时可以选择是否 sleep 休眠一下。经过压测得出 sleep 开销如下。
- 10us 的空闲时间,cpu开销在 3% 左右;
- 5us 的空间实现,cpu 开销在 10% 左右。
- < 5us 的空间实现,cpu 开销接近 100%。
// WriteSleep 当 ringbuffer 已满时,先 cpu pause 则 sched 让出资源,最后进行 sleep 休眠,以此避免频繁 spin 引发的 cpu 开销。
func (q *Producer[T]) WriteSleep(v T, dur time.Duration) error {
return q.write(v, dur)
}
func (q *Producer[T]) write(v T, dur time.Duration) error {
if q.closed() {
return ClosedError
}
next := q.seqer.wc.increment()
var i = 0
for {
// 判断是否可以写入
r := atomic.LoadUint64(&q.seqer.rc) - 1
if next <= r+q.capacity {
// 可以写入数据,将数据写入到指定位置
q.rbuf.write(next-1, v)
// 释放,防止消费端阻塞
q.blocks.release()
return nil
}
if i < spin {
procyield(30)
} else if i < spin+passiveSpin {
runtime.Gosched()
} else {
time.Sleep(dur)
i = 0
}
i++
// 再次判断是否已关闭
if q.closed() {
return ClosedError
}
}
}
😁 关于 lockfree write 写失败 spin 引发的 cpu 过高问题,已经给作者提价 pull request (pr),但作者还没给合并,说要考虑用户的选择再考虑下。我表示不理解。
https://github.com/bruceshao/lockfree/pull/15
consumer 消费者
初始化 consumer
type consumer[T any] struct {
status int32 // 运行状态
rbuf *ringBuffer[T]
seqer *sequencer
blocks blockStrategy
hdl EventHandler[T]
}
func newConsumer[T any](rbuf *ringBuffer[T], hdl EventHandler[T], sequer *sequencer, blocks blockStrategy) *consumer[T] {
return &consumer[T]{
rbuf: rbuf,
seqer: sequer,
hdl: hdl,
blocks: blocks,
status: READY,
}
}
func (c *consumer[T]) start() error {
// 保证单例
if atomic.CompareAndSwapInt32(&c.status, READY, RUNNING) {
go c.handle()
return nil
}
return fmt.Errorf(StartErrorFormat, "Consumer")
}
consumer 消费数据
func (c *consumer[T]) handle() {
// 获取 read 的 位置
rc := c.seqer.nextRead()
for {
if c.closed() {
return
}
var i = 0
for {
if c.closed() {
return
}
// 位置的对象是否可读,可读获取对象的数据.
if v, exist := c.rbuf.contains(rc - 1); exist {
// 既然可读了,则递增 read 位置,下次轮询新位置.
rc = c.seqer.readIncrement()
// 调用注册的回调方法,把数据传递过去.
c.hdl.OnEvent(v)
i = 0
break
}
// 当无数据可读时, 可按照策略进行阻塞等待.
// 当轮询小于 4 次时, 每次执行 30 次 cpu pause
if i < spin {
procyield(30)
} else if i < spin+passiveSpin {
// 空闲阻塞策略,当轮询在 4-6 次时, 每次执行 runtime sched 让出调度资源
runtime.Gosched()
} else {
// 自定义阻塞策略
c.blocks.block()
// 重置为 0
i = 0
}
i++
}
}
}
判断 ringbuffer 某个 seq 是否可读 ?
lockfree 开始的设计使用 bitmap 判断 ringbuffer 各个位置的数据情况,后来改成在每个 entry 对象里存放了 producer 写入的 seq。这样判断位置是否可读只需判断 entry.seq 是否一致即可。
func (r *ringBuffer[T]) contains(c uint64) (T, bool) {
x := &r.buf[c&r.capMask]
if atomic.LoadUint64(&x.c) == c+1 {
v := x.val
return v, true
}
return r.tDefault, false
}
总结
lockfree queue 的设计还是很简单,首先需要一个原子递增的发号器,生产者并发写下,先拿到一个 seq 序号,然后 ringbuffer 不满下,只需写到 ringbuffer 对应位置即可。而读取数据只需判断对应结构的 seq 跟 consumer seq 是否一致即可。
至于 lockfree 的性能表现,如下所述.
- 在goroutine数量比较小时,lockfree和chan性能差别不明显;
- 当goroutine打到一定数量(大于1000)后,lockfree无论从时间还是QR都远远超过chan;
一句话,大多数场景不需要 lockfree 无锁队列,除非追求机制的性能体验。平时用 golang channel 足矣了,如果 golang channel 出现并发的性能瓶颈,其实也可以变通下,切分多个 channel 来分担 mutex 锁竞争冲突,以提高 channel 的读写并行吞吐。

