
hashicorp 的 go-memdb 是一个功能丰富且强大的内存型 KV 数据库,支持数据的读写和迭代,还支持 MVCC 多版本、事务、多样索引(单索引和联合索引)、watch 监听等等。 go-memdb 使用 radix tree 来存储数据对象和索引结构,由于 radixtree 是有序的,所以 go-memdb 支持迭代。
社区中不少开源项目都有使用 go-memdb 构建数据对象,通过事务 MVCC 实现一致性读视图,通过索引功能实现对数据对象的索引。
事务
go-memdb 的事务实现原理相对简单,读读事务之间不阻塞,写写事务之间阻塞,读写事务之间不阻塞可并发,但同一时间只能有一个可写的事务。写事务在提交后,被阻塞的写事务才能进行。go-memdb 跟其他 kv 存储引擎一样,属于乐观事务,只有在提交时候才做写操作,由于写写阻塞,写事务会加锁,所以这里无需实现事务的冲突检测。
索引
go-memdb 的索引是个很实用的功能,可以对一个 struct 结构建立多个维度的索引,之后可以通过各个维度进行查询。
举个例子来说明 go-memdb 索引功能,比如需要构建一个内部缓存,保存的结构体有 id,name,age,address 等几个字段,这里需要通过 id、name、age、address 等字段分别获取符合条件的对象,还需要通过 name 和 address 组合条件获取符合条件的对象。当然这个需求可以使用 sqlite memory 模式,但 sqlite 有些重,需要构建成 sql 语句。
https://github.com/hashicorp/go-memdb
go-memdb 使用方法
下面为 hashicorp go-memdb 的用法,起流程是先创建 dbschema,再使用定义的 dbschema 构建 memdb,后面就可以开事务进行增删改查操作了。
type Person struct {
Email string
Name string
Age int
}
// 实例化 db scheme 对象.
schema := &memdb.DBSchema{
Tables: map[string]*memdb.TableSchema{
"person": &memdb.TableSchema{
Name: "person", // 需要跟 table 值一致.
Indexes: map[string]*memdb.IndexSchema{
// 主键索引
"id": &memdb.IndexSchema{
Name: "id",
Unique: true, // 主键的值必须唯一
Indexer: &memdb.StringFieldIndex{Field: "Email"}, // email 作为 id 主键,id 字段不能为联合索引字段.
},
"age": &memdb.IndexSchema{
Name: "age",
Unique: false, // 不需要唯一
Indexer: &memdb.IntFieldIndex{Field: "Age"}, // age 作为索引值.
},
},
},
},
}
// 根据 dbschema 配置来创建 memdb 数据库对象
db, err := memdb.NewMemDB(schema)
if err != nil {
panic(err)
}
// 创建可读可写的事务
txn := db.Txn(true)
people := []*Person{
&Person{"joe@aol.com", "Joe", 30},
&Person{"lucy@aol.com", "Lucy", 35},
&Person{"tariq@aol.com", "Tariq", 21},
&Person{"dorothy@aol.com", "Dorothy", 53},
}
for _, p := range people {
// 事务中执行插入操作.
if err := txn.Insert("person", p); err != nil {
panic(err)
}
}
// 事务提交,完成写操作.
txn.Commit()
// 创建只读事务.
txn = db.Txn(false)
defer txn.Abort()
/ 根据主键 id 来获取数据.
raw, err := txn.First("person", "id", "joe@aol.com")
if err != nil {
panic(err)
}
fmt.Printf("Hello %s!\n", raw.(*Person).Name)
// 返回可以遍历数据的迭代器.
it, err := txn.Get("person", "id")
if err != nil {
panic(err)
}
fmt.Println("All the people:")
for obj := it.Next(); obj != nil; obj = it.Next() {
p := obj.(*Person)
fmt.Printf(" %s\n", p.Name)
}
// 相当于 seek 操作.
it, err = txn.LowerBound("person", "age", 25)
if err != nil {
panic(err)
}
// 从 age 25 开始迭代表里,直到 age 35 中断迭代器.
for obj := it.Next(); obj != nil; obj = it.Next() {
p := obj.(*Person)
if p.Age > 35 {
break
}
fmt.Printf(" %s is aged %d\n", p.Name, p.Age)
}
hashicorp go-memdb 源码分析
hashicorp 的数据及索引是使用 radixtree 来实现的。
memdb 的初始化
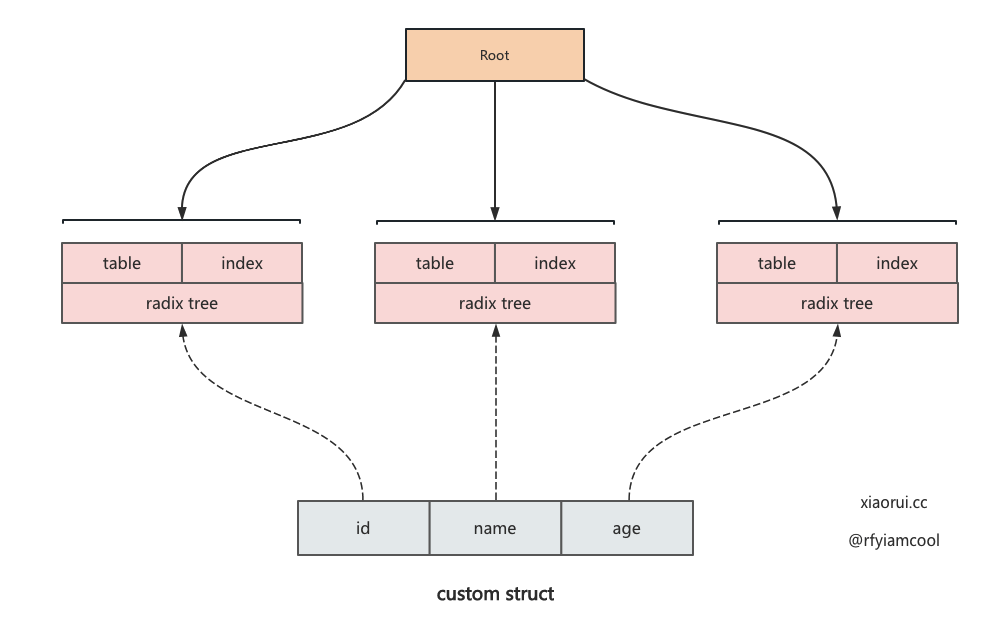
根据传入的 db schema 来实例化 memdb,内部会先对 schema 进行校验,接着会为每个 table 的 index 实例化一个 radix tree 索引结构。
type MemDB struct {
schema *DBSchema
root unsafe.Pointer // *iradix.Tree underneath
primary bool
// There can only be a single writer at once
writer sync.Mutex
}
// NewMemDB creates a new MemDB with the given schema.
func NewMemDB(schema *DBSchema) (*MemDB, error) {
// 校验传入的结构
if err := schema.Validate(); err != nil {
return nil, err
}
// 创建 memdb
db := &MemDB{
schema: schema,
root: unsafe.Pointer(iradix.New()),
primary: true,
}
// 初始化表和索引.
if err := db.initialize(); err != nil {
return nil, err
}
return db, nil
}
格式校验
实例化 memdb 需要对 dbschema 进行格式校验,这里需要注意的是 id 作为主键索引字段,必须要有,且只能是单字段索引模式,另外需要开启 unique 唯一键,毕竟都是主键了,不然是符合数据唯一特性。
type DBSchema struct {
// Tables is the set of tables within this database. The key is the
// table name and must match the Name in TableSchema.
Tables map[string]*TableSchema
}
// Validate validates the schema.
func (s *DBSchema) Validate() error {
if s == nil {
return fmt.Errorf("schema is nil")
}
if len(s.Tables) == 0 {
return fmt.Errorf("schema has no tables defined")
}
for name, table := range s.Tables {
// map key 需要跟 table 的 name 一致.
if name != table.Name {
return fmt.Errorf("table name mis-match for '%s'", name)
}
if err := table.Validate(); err != nil {
return fmt.Errorf("table %q: %s", name, err)
}
}
return nil
}
// 描述表的索引
type TableSchema struct {
Name string
Indexes map[string]*IndexSchema
}
// Validate is used to validate the table schema
func (s *TableSchema) Validate() error {
// 不能为空
if s.Name == "" {
return fmt.Errorf("missing table name")
}
// 索引不能为空,最少有一个主键索引.
if len(s.Indexes) == 0 {
return fmt.Errorf("missing table indexes for '%s'", s.Name)
}
// 如果没有 id 主键则报错.
if _, ok := s.Indexes["id"]; !ok {
return fmt.Errorf("must have id index")
}
// id 主键索引需要开启 unique 唯一.
if !s.Indexes["id"].Unique {
return fmt.Errorf("id index must be unique")
}
// 主键索引只能一个字段.
if _, ok := s.Indexes["id"].Indexer.(SingleIndexer); !ok {
return fmt.Errorf("id index must be a SingleIndexer")
}
for name, index := range s.Indexes {
if name != index.Name {
return fmt.Errorf("index name mis-match for '%s'", name)
}
// indexer 只能是 singeIndexer 和 multiIndexer 两种索引类型.
if err := index.Validate(); err != nil {
return fmt.Errorf("index %q: %s", name, err)
}
}
return nil
}
initialize 初始化 memdb 对象
initialize 用来初始化 memdb,遍历 memdb.DBSchema 结构,每个 table 的 index 都是一个 radixtree 基数树.
每个 table 的每个 index 都有独立的 radix tree 索引接口.
func (db *MemDB) initialize() error {
root := db.getRoot()
for tName, tableSchema := range db.schema.Tables {
for iName := range tableSchema.Indexes {
// 每个 table 的每个 index 都有独立的 radix tree 索引接口.
index := iradix.New()
path := indexPath(tName, iName)
root, _, _ = root.Insert(path, index)
}
}
db.root = unsafe.Pointer(root)
return nil
}
func indexPath(table, index string) []byte {
return []byte(table + "." + index)
}
Indexer 接口的设计实现
go-memdb 内部实现了两种 indexer 接口,分别为单索引 SingleIndexer 和 组合多索引 MultiIndexer。SingleIndexer 是给一个字段建立索引,而 MultiIndexer 可以像 mysql 那样建立联合索引,多个字段联合起来做为一个索引键。

SingleIndexer 实现了多种数据结构的 SingleIndexer 索引,可覆盖绝大多数场景的索引需求。
下面是 StringFieldIndex 的源码实现。
StringFieldIndex 用来为 string 类型创建索引键,它实现了 SingleIndexer 的 FromObject 方法。 FromObject 会根据 reflect 反射库获取指定的 field 的 value。
type StringFieldIndex struct {
Field string
Lowercase bool
}
func (s *StringFieldIndex) FromObject(obj interface{}) (bool, []byte, error) {
v := reflect.ValueOf(obj)
v = reflect.Indirect(v) // Dereference the pointer if any
fv := v.FieldByName(s.Field)
isPtr := fv.Kind() == reflect.Ptr
fv = reflect.Indirect(fv)
if !isPtr && !fv.IsValid() {
return false, nil,
fmt.Errorf("field '%s' for %#v is invalid %v ", s.Field, obj, isPtr)
}
if isPtr && !fv.IsValid() {
val := ""
return false, []byte(val), nil
}
// 空字符串不能做索引.
val := fv.String()
if val == "" {
return false, nil, nil
}
// 格式化
if s.Lowercase {
val = strings.ToLower(val)
}
// Add the null character as a terminator
val += "\x00"
return true, []byte(val), nil
}
下面是 IntFieldIndex 的实现,IntFieldIndex 用来为整型数字创建索引键。
type IntFieldIndex struct {
Field string
}
func (i *IntFieldIndex) FromObject(obj interface{}) (bool, []byte, error) {
v := reflect.ValueOf(obj)
v = reflect.Indirect(v) // Dereference the pointer if any
fv := v.FieldByName(i.Field)
if !fv.IsValid() {
return false, nil,
fmt.Errorf("field '%s' for %#v is invalid", i.Field, obj)
}
// Check the type
k := fv.Kind()
// 校验数字类型,且返回数字的字节数。
size, ok := IsIntType(k)
if !ok {
return false, nil, fmt.Errorf("field %q is of type %v; want an int", i.Field, k)
}
// 获取数字,然后进行 tlv 编码,其实这里直接用 varint 就可以了。
val := fv.Int()
buf := encodeInt(val, size)
return true, buf, nil
}
go-memdb 的其他索引的实现就不说了,大同小异,具体实现原理直接看代码即可。
🚀 🚀 🚀 索引的小结:
go-memdb 里一个 table 的每个 index 都跟 obj 对象绑定,比如这里有个结构体 struct {id,a,b,c string},这四个字段都建立的索引,插入该对象时,需要这四个字段分别跟这个对象建立索引。这里的设计跟 mysql 不一样,像 mysql 是分主键索引和辅助索引的,主键索引的 key 为唯一 id,而辅助索引 key 为索引值,value 为 主键的 id。
go-memdb 也有主键索引的概念,但跟 mysql 不是一个概念. 在写数据时,先尝试从该 table 的 id 索引里获取旧数据对象,然后遍历该 table schema 的索引配置集合,先使用旧数据的值,再添加新值进去。读数据时,找到 table 对象的索引对象,通过值直接获取 obj 对象。
创建事务 txn
创建事务,当 write 为 true 时,则需要加锁。只读事务则不需要锁。go-memdb 里写写事务之间是阻塞的,读读事务之间可并发,读和写事务之间也可并发,但要同一时间只能有一个写事务。
func (db *MemDB) Txn(write bool) *Txn {
// 如果事务中有写操作,则需要传递 true.
if write {
// 加锁
db.writer.Lock()
}
// 创建 txn 结构
txn := &Txn{
db: db,
write: write,
// 获取顶部的 radix tree
rootTxn: db.getRoot().Txn(),
}
return txn
}
插入数据
func (txn *Txn) Insert(table string, obj interface{}) error {
// 只有在事务中开启写操作,才能写数据.
if !txn.write {
return fmt.Errorf("cannot insert in read-only transaction")
}
// 获取表的索引结构
tableSchema, ok := txn.db.schema.Tables[table]
if !ok {
return fmt.Errorf("invalid table '%s'", table)
}
// 通过 id 字段获取 IndexSchema
idSchema := tableSchema.Indexes[id]
idIndexer := idSchema.Indexer.(SingleIndexer)
// 通过反射机制从 obj 获取 id 的 val 值
ok, idVal, err := idIndexer.FromObject(obj)
if err != nil {
return fmt.Errorf("failed to build primary index: %v", err)
}
if !ok {
return fmt.Errorf("object missing primary index")
}
// txn 存储了各个 table-index 有快照的 radix tree,根据 id 获取旧的 radix tree,如果没有则创建.
idTxn := txn.writableIndex(table, id)
// 获取已存在的旧值,是否需要更新.
existing, update := idTxn.Get(idVal)
// 遍历传入 table 的索引结构.
for name, indexSchema := range tableSchema.Indexes {
indexTxn := txn.writableIndex(table, name)
var (
ok bool
vals [][]byte
err error
)
// 获取索引的值
switch indexer := indexSchema.Indexer.(type) {
case SingleIndexer:
var val []byte
ok, val, err = indexer.FromObject(obj)
vals = [][]byte{val}
case MultiIndexer:
ok, vals, err = indexer.FromObject(obj)
}
if err != nil {
return fmt.Errorf("failed to build index '%s': %v", name, err)
}
if ok && !indexSchema.Unique {
for i := range vals {
vals[i] = append(vals[i], idVal...)
}
}
// 如果需要更新操作,那么就先把以前的数据给干掉,后面在插入.
if update {
var (
okExist bool
valsExist [][]byte
err error
)
// 先获取旧值
switch indexer := indexSchema.Indexer.(type) {
case SingleIndexer:
var valExist []byte
okExist, valExist, err = indexer.FromObject(existing)
valsExist = [][]byte{valExist}
case MultiIndexer:
okExist, valsExist, err = indexer.FromObject(existing)
}
if err != nil {
return fmt.Errorf("failed to build index '%s': %v", name, err)
}
// 删除旧值
if okExist {
// 遍历所有的旧值.
for i, valExist := range valsExist {
// 如果不需要去重,则把数据追加到 valExist 集合里,带后面删除旧值.
if !indexSchema.Unique {
valExist = append(valExist, idVal...)
}
// 如果不相等,自然需要删除旧数据.
if i >= len(vals) || !bytes.Equal(valExist, vals[i]) {
indexTxn.Delete(valExist)
}
}
}
}
// 把索引和值插入到 radix tree 里.
for _, val := range vals {
indexTxn.Insert(val, obj)
}
}
// 如果 changes 不为空,则添加 change 到 txn.changes 结构里.
if txn.changes != nil {
txn.changes = append(txn.changes, Change{
Table: table,
Before: existing, // might be nil on a create
After: obj,
primaryKey: idVal,
})
}
return nil
}
writableIndex 获取写索引快照
func (txn *Txn) writableIndex(table, index string) *iradix.Txn {
// 为空则实例化
if txn.modified == nil {
txn.modified = make(map[tableIndex]*iradix.Txn)
}
// 寻找已存在的 radix.Txn
key := tableIndex{table, index}
exist, ok := txn.modified[key]
if ok {
// 返回已存在的 radix.Txn
return exist
}
// 创建 table index 相关的 tree,然后通过 txn() 获取快照
path := indexPath(table, index)
raw, _ := txn.rootTxn.Get(path)
indexTxn := raw.(*iradix.Tree).Txn()
// 把 indexTxn 赋值到 modified 修改集合里.
txn.modified[key] = indexTxn
return indexTxn
}
读取数据
// 获取第一个值
func (txn *Txn) First(table, index string, args ...interface{}) (interface{}, error) {
// 通过表和索引获取数.
_, val, err := txn.FirstWatch(table, index, args...)
return val, err
}
func (txn *Txn) FirstWatch(table, index string, args ...interface{}) (<-chan struct{}, interface{}, error) {
// 获取 table 和 index 的 索引结构.
indexSchema, val, err := txn.getIndexValue(table, index, args...)
if err != nil {
return nil, nil, err
}
// 从 txn.modified 修改集合中获取 radix tree 索引快照.
indexTxn := txn.readableIndex(table, indexSchema.Name)
// 获取值,当无值时返回 watch 对象,调用层可以阻塞等.
if indexSchema.Unique && val != nil && indexSchema.Name == index {
watch, obj, ok := indexTxn.GetWatch(val)
if !ok {
return watch, nil, nil
}
return watch, obj, nil
}
// 构建 iterator 迭代器, 在 radixtree 里加入监听器,获取第一个 iterator 第一个值.
iter := indexTxn.Root().Iterator()
watch := iter.SeekPrefixWatch(val)
_, value, _ := iter.Next()
return watch, value, nil
}
删除数据
func (txn *Txn) Delete(table string, obj interface{}) error {
// 事务不可写,直接报错
if !txn.write {
return fmt.Errorf("cannot delete in read-only transaction")
}
// 获取 table 的 schema
tableSchema, ok := txn.db.schema.Tables[table]
if !ok {
return fmt.Errorf("invalid table '%s'", table)
}
// 通过主键 id 获取索引
idSchema := tableSchema.Indexes[id]
idIndexer := idSchema.Indexer.(SingleIndexer)
// 获取 obj 的 id 值
ok, idVal, err := idIndexer.FromObject(obj)
if err != nil {
return fmt.Errorf("failed to build primary index: %v", err)
}
if !ok {
return fmt.Errorf("object missing primary index")
}
// 获取索引快照
idTxn := txn.writableIndex(table, id)
existing, ok := idTxn.Get(idVal)
if !ok {
// 如果 id 索引没有,那么就假定其他索引也没有.
return ErrNotFound
}
// 在所有索引集合中删除相关数据
for name, indexSchema := range tableSchema.Indexes {
// 根据 table 和 index 获取对应的索引快照.
indexTxn := txn.writableIndex(table, name)
var (
ok bool
vals [][]byte
err error
)
// 根据已存在的对象 existing 里获取对应索引的 val.
switch indexer := indexSchema.Indexer.(type) {
case SingleIndexer:
var val []byte
ok, val, err = indexer.FromObject(existing)
vals = [][]byte{val}
case MultiIndexer:
ok, vals, err = indexer.FromObject(existing)
}
if err != nil {
return fmt.Errorf("failed to build index '%s': %v", name, err)
}
if ok {
for _, val := range vals {
// 如果不要求唯一性,则添加到 val 里.
if !indexSchema.Unique {
val = append(val, idVal...)
}
// 在相关索引里删除值.
indexTxn.Delete(val)
}
}
}
if txn.changes != nil {
txn.changes = append(txn.changes, Change{
Table: table,
Before: existing,
After: nil, // Now nil indicates deletion
primaryKey: idVal,
})
}
return nil
}
事务提交及中断
go-memdb 的事务是乐观事务,只有在提交时才真正的写,事务进行中的写操作都是在一个新的 tree 里操作,这些 tree 放到 modified 集合里。为了实现一致性读视图,读取的时候自然也会从 modified 集合里读取。
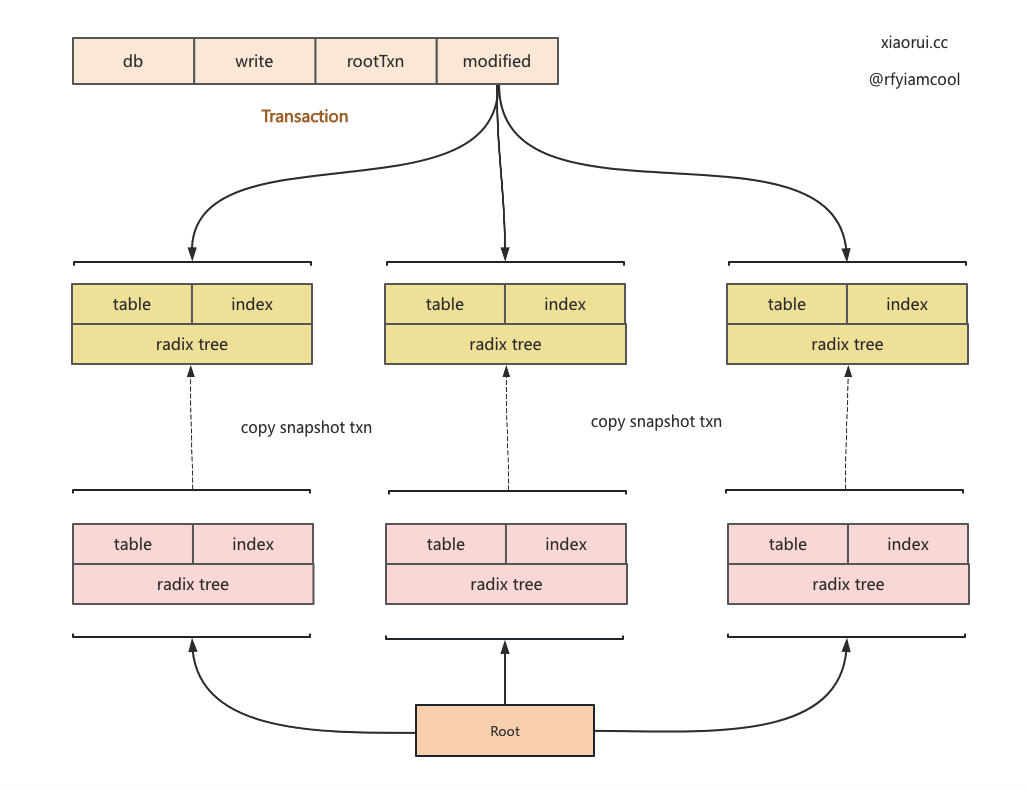
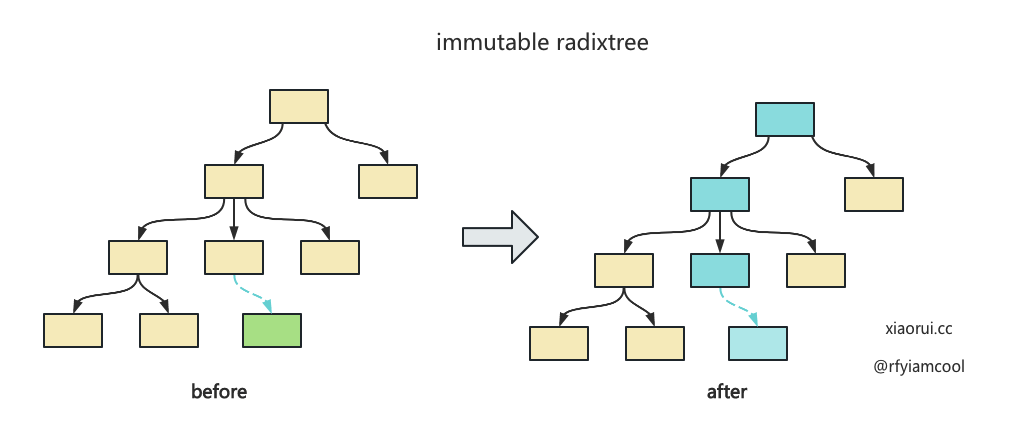
go-memdb 的写操作是对 radixtree 进行 copy on write 操作,写数据时从 root 里获取 radix tree 快照对象,然后在新的快照对象上修改,其实就是构建一条新的 node 关系,然后替换 root 根。如下图所示,当新增和修改绿色 node 时,需要把 node 往上直到 root 那一串的 node 复制出来,然后修改 node 之间的关系,最后更新进去。
熟悉 boltdb 源码的朋友会发现,hashicorp immutable radixtree 跟 boltdb b+tree 的设计很像,数据的写操作不是在原地更新 in place,也是使用 cow 的机制,就是说每次更新使用新的 root page 关联。
撤销中断事务
Abort 用来实现撤销事务。
func (txn *Txn) Abort() {
// 如果是读操作,直接返回.
if !txn.write {
return
}
// 如果已经中断或者已提交,则直接跳出.
if txn.rootTxn == nil {
return
}
// 清理事务
txn.rootTxn = nil
txn.modified = nil
txn.changes = nil
// 释放写锁,事务开始时加的锁,中断自然需要释放锁.
txn.db.writer.Unlock()
}
提交事务
Commit 用来实现事务提交。
func (txn *Txn) Commit() {
// 读事务直接返回即可.
if !txn.write {
return
}
// 如果已经中断或者已提交,则直接跳出.
if txn.rootTxn == nil {
return
}
// 遍历 txn 的 modified 集合, 在 rootTxn 里插入修改的数据.
for key, subTxn := range txn.modified {
path := indexPath(key.Table, key.Index)
final := subTxn.CommitOnly()
// 在 root 里插入修改过的 radix tree
txn.rootTxn.Insert(path, final)
}
newRoot := txn.rootTxn.CommitOnly()
atomic.StorePointer(&txn.db.root, unsafe.Pointer(newRoot))
// 进行 trigger notifications 提交.
for _, subTxn := range txn.modified {
subTxn.Notify()
}
txn.rootTxn.Notify()
// 清理事务
txn.rootTxn = nil
txn.modified = nil
// 释放写锁
txn.db.writer.Unlock()
// 按照先进后出的方式,调用 after 的方法,txn.Defer 用来注册回调方法.
for i := len(txn.after); i > 0; i-- {
fn := txn.after[i-1]
fn()
}
}
总结
go-memdb 的实现设计很不错,其源码质量也不错,值得一看。
hashicorp 的 go-memdb 是一个功能丰富且强大的内存型 KV 数据库,支持数据的读写和迭代,还支持 MVCC 多版本、事务、多样索引(单索引和联合索引)、watch 监听等等。 go-memdb 使用 radix tree 来存储数据对象和索引结构,由于 radixtree 是有序的,所以 go-memdb 支持迭代。
社区中不少开源项目都有使用 go-memdb 构建数据对象,通过事务 MVCC 实现一致性读视图,通过索引功能实现对数据对象的索引。
事务
go-memdb 的事务实现相对简单,读读事务之间不阻塞,写写事务之间阻塞,读写事务之间不阻塞可并发,但同一时间只能有一个可写的事务。写事务在提交后,被阻塞的写事务才能进行。go-memdb 跟其他 kv 存储引擎一样,属于乐观事务,只有在提交时候才做写操作,由于写写阻塞,写事务会加锁,所以这里无需实现事务的冲突检测。
索引
go-memdb 的索引是个很实用的功能,可以对一个 struct 结构建立多个维度的索引,之后可以通过各个维度进行查询。
举个例子来说明 go-memdb 索引功能,比如需要构建一个内部缓存,保存的结构体有 id,name,age,address 等几个字段,这里需要通过 id、name、age、address 等字段分别获取符合条件的对象,还需要通过 name 和 address 组合条件获取符合条件的对象。当然这个需求可以使用 sqlite memory 模式,但 sqlite 有些重,需要构建成 sql 语句。

