
源码分析基于 bitcask 的 rosedb 存储引擎 Compaction GC 合并垃圾回收的实现
使用 bitcask 模型实现的 kv 存储引擎不会直接原理删除数据,而是通过 compaction gc 合并垃圾回收的方式来释放空间。 社区基于 bitcask 的 rosedb 和 nutsdb 当然也这么设计的。
rosedb 在删除数据时,先在 logfile 日志里写一条带 delete 标记的数据,然后在内存索引里剔除数据。更新数据写到 logfile 里,然后在索引中更新文件位置。 不断的更新和删除操作下,当 logfile 的垃圾数据占比超过 GC 阈值时,则会被垃圾回收器处理。
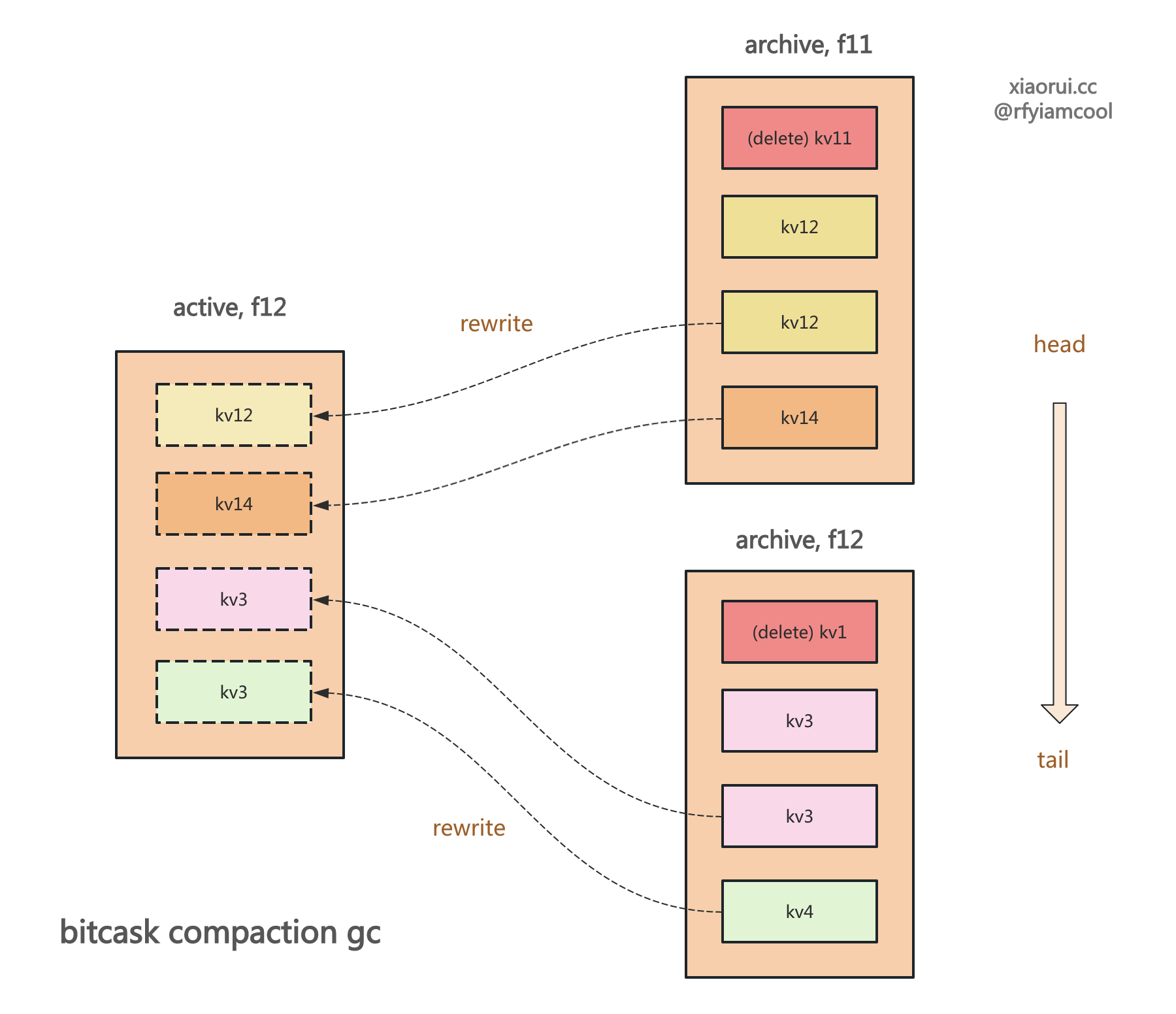
其实基于 lsm tree 的存储引擎,则是通过 compaction 合并来整理存储空间。而基于 B+Tree 实现的存储引擎,通过释放和申请 page 页的方式排列数据,所以不需要 compaction 合并操作。
golang bitcask rosedb 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-bitcask-rosedb
rosedb 的垃圾回收入口
rosedb 会周期性地触发垃圾回收,默认为 8 个小时。其内部会为每个 datatype 类型都启动一个 GC 垃圾回收线程。每个 gc 垃圾回收线程只会对绑定的 datatype 处理。由于 rosedb 里不同的 dataType 类型有不同的 active logfile 和 archive logfile 集合,所以可按照 dataType 粒度进行并行垃圾回收,dataType 内部没有采用并发操作,而是对满足阈值 logfile 文件一个个来处理。
由于 logfile 内部和文件之间都没实现数据排序,所以不能像 rocksdb 和 badgerDB 这类 lsm tree 引擎那样,支持 key range 粒度的并发合并。当然,就算 logfile 不排序,也可以直接可以对多个 logfile 做并发垃圾回收操作。但由于 bitcask 本就不适合存储大数据,所有没啥大数据,采用 dataType 粒度并行垃圾回收足矣。

手动触发垃圾回收
func (db *RoseDB) RunLogFileGC(dataType DataType, fid int, gcRatio float64) error {
// gcState 大于 0,说明正在执行 gc 垃圾回收
if atomic.LoadInt32(&db.gcState) > 0 {
return ErrGCRunning
}
// 传递数据类型、logfile 的 ID 和垃圾回收率.
return db.doRunGC(dataType, fid, gcRatio)
}
定时触发垃圾回收
// 默认 gc 的时间间隔为 8 个小时,每 8 个小时进行尝试 gc 垃圾回收.
var LogFileGCInterval: time.Hour * 8,
// 垃圾文件的空间占比, 被删除的数据空间 / 总空间
var LogFileGCRatio: 0.5,
// 每个 logfile 最大的空间占用, 默认为 512 MB.
var LogFileSizeThreshold: 512 << 20,
func (db *RoseDB) handleLogFileGC() {
// 如果 gc 的 interval 为 0,则退出
if db.opts.LogFileGCInterval <= 0 {
return
}
// 绑定信号
quitSig := make(chan os.Signal, 1)
signal.Notify(quitSig, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
// 创建一个用来 gc 垃圾回收的 ticker 定时器
ticker := time.NewTicker(db.opts.LogFileGCInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 当 gcState 大于 0, gc 正在垃圾回收中.
if atomic.LoadInt32(&db.gcState) > 0 {
logger.Warn("log file gc is running, skip it")
break
}
// 为每个 dataType 都启动 gc 垃圾回收器。
for dType := String; dType < logFileTypeNum; dType++ {
go func(dataType DataType) {
err := db.doRunGC(dataType, -1, db.opts.LogFileGCRatio)
if err != nil {
logger.Errorf("log file gc err, dataType: [%v], err: [%v]", dataType, err)
}
}(dType)
}
case <-quitSig:
return
}
}
}
rosedb 合并和垃圾回收的核心逻辑
由于 doRunGC 垃圾回收的代码有些冗长,这里把代码做下拆分。
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
// 原子更新 gcState 值,1 为正在进行垃圾回收,0 为空闲中.
atomic.AddInt32(&db.gcState, 1)
defer atomic.AddInt32(&db.gcState, -1)
maybeRewriteStrs := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// ...
return nil
}
maybeRewriteList := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// ...
return nil
}
maybeRewriteHash := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// ...
return nil
}
maybeRewriteSets := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// ...
return nil
}
maybeRewriteZSet := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// ...
return nil
}
// 根据传入的 dataType 获取对应的当前活跃的 logfile.
activeLogFile := db.getActiveLogFile(dataType)
// rosedb 是懒惰式实例化 activeLogFile 的,如果 rosedb 启动后一直无写入,那么就无需实例化活跃的 logfile.
if activeLogFile == nil {
return nil
}
// 保证数据安全,把 discards 的数据进行同步落盘.
if err := db.discards[dataType].sync(); err != nil {
return err
}
// 获取符合垃圾回收阈值的 logfile 的 id 列表.
ccl, err := db.discards[dataType].getCCL(activeLogFile.Fid, gcRatio)
if err != nil {
return err
}
// 遍历 file id 列表
for _, fid := range ccl {
// 如果是手动触发的垃圾回收,需要校验传入的 fid 是否合法.
// 还有如果不匹配, 则忽略.
if specifiedFid >= 0 && uint32(specifiedFid) != fid {
continue
}
// 从归档集合里获取 fid 和 dataType 对应的 logfile 对象
archivedFile := db.getArchivedLogFile(dataType, fid)
if archivedFile == nil {
continue
}
// 初始值当时为 0,从头部开始扫描 logfile.
var offset int64
for {
// 拿到 offset 位置的 entry,起流程是先获取 header,再通过 key 和 value size 拿到 kv 数据.
ent, size, err := archivedFile.ReadLogEntry(offset)
if err != nil {
// 读完了,则终端循环
if err == io.EOF || err == logfile.ErrEndOfEntry {
break
}
return err
}
// 累加 offset 偏移量.
var off = offset
offset += size
// 如果该 entry 已被标记删除,则忽略.
if ent.Type == logfile.TypeDelete {
continue
}
// 如果该 entry 过期了,则忽略.
ts := time.Now().Unix()
if ent.ExpiredAt != 0 && ent.ExpiredAt <= ts {
continue
}
// doRunGC 方法内部定义了多个匿名方法,这里会根据 dataType 的类型调用不同的处理方法.
var rewriteErr error
switch dataType {
case String:
rewriteErr = maybeRewriteStrs(archivedFile.Fid, off, ent)
case List:
rewriteErr = maybeRewriteList(archivedFile.Fid, off, ent)
case Hash:
rewriteErr = maybeRewriteHash(archivedFile.Fid, off, ent)
case Set:
rewriteErr = maybeRewriteSets(archivedFile.Fid, off, ent)
case ZSet:
rewriteErr = maybeRewriteZSet(archivedFile.Fid, off, ent)
}
if rewriteErr != nil {
return rewriteErr
}
}
// 删除旧的logfile,该旧的 logfile 已被合并回收了,则可以删除旧的 logfile.
db.mu.Lock()
delete(db.archivedLogFiles[dataType], fid)
_ = archivedFile.Delete()
db.mu.Unlock()
// 既然 logfile 都被删除了,自然要干掉关联的 discard 统计信息.
db.discards[dataType].clear(fid)
}
return nil
}
getCCL 获取需要被合并和垃圾回收的 logfile 列表
下图为 discard 在 rosedb 里的数据排列布局。rosedb 启动时会为每个 dateType 类型分配一个 discard 控制器,每次更新和删除数据时,需要把 entry 传递给 discard 记录删除的空间大小,discard 记录了每个 logfile 文件删除了多少数据。当需要进行垃圾回收时,依赖 discard 记录的删除数据计算出垃圾回收的比率。

getCCL 用来获取需要被垃圾回收的 logfile 列表,其内部是这样实现的。遍历获取该 discard 里的所有 logfile 的数据,计算当前 logfile 文件删除空间在总空间的占用比率,公式为 curRatio = float64(discard) / float64(total),然后对这些超过垃圾回收阈值的 logfile 进行正排序,老的 logfile 在数组的前面。
func (d *discard) getCCL(activeFid uint32, ratio float64) ([]uint32, error) {
var offset int64
var ccl []uint32
// 加锁, 放锁
d.Lock()
defer d.Unlock()
for {
// 获取 offset 偏移量对应的 discard 记录.
buf := make([]byte, discardRecordSize)
_, err := d.file.Read(buf, offset)
if err != nil {
// 如果读到尾了,再中断退出.
if err == io.EOF || err == logfile.ErrEndOfEntry {
break
}
return nil, err
}
// 累加偏移量
offset += discardRecordSize
// 解码读取 fid, total 和 discard 三个字段.
fid := binary.LittleEndian.Uint32(buf[:4])
total := binary.LittleEndian.Uint32(buf[4:8])
discard := binary.LittleEndian.Uint32(buf[8:12])
var curRatio float64
if total != 0 && discard != 0 {
// 计算出删除空间在总空间的占用比率
curRatio = float64(discard) / float64(total)
}
// 需要忽略活跃 logfile, 如当前的 logfile 的删除数据占比超过了垃圾回收 ratio 阈值,
// 则添加到 ccl 集合里.
if curRatio >= ratio && fid != activeFid {
ccl = append(ccl, fid)
}
}
// 进行正序排序,老的 logfile 在数组的前面.
sort.Slice(ccl, func(i, j int) bool {
return ccl[i] < ccl[j]
})
return ccl, nil
}
string 结构的 GC 垃圾回收实现
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
// ...
maybeRewriteStrs := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// 加锁, 放锁
db.strIndex.mu.Lock()
defer db.strIndex.mu.Unlock()
// 获取 key 关联的 radix node
indexVal := db.strIndex.idxTree.Get(ent.Key)
if indexVal == nil {
return nil
}
node, _ := indexVal.(*indexNode)
// 如果在内存索引中有该记录,且 fid 和 offset 都是一样的,那么则需要把该数据写到当前的活跃的 logfile 日志文件里.
if node != nil && node.fid == fid && node.offset == offset {
// 进行重写,把该 entry 到日志文件里
valuePos, err := db.writeLogEntry(ent, String)
if err != nil {
return err
}
// 更新内存的索引值,使用新的 valuePos 来关联 key.
if err = db.updateIndexTree(db.strIndex.idxTree, ent, valuePos, false, String); err != nil {
return err
}
}
return nil
}
// ...
}
list 列表的 GC 垃圾回收实现
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
// ...
maybeRewriteList := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// 加锁,解锁
db.listIndex.mu.Lock()
defer db.listIndex.mu.Unlock()
var listKey = ent.Key
// 解码为 list key
if ent.Type != logfile.TypeListMeta {
// logfile entry 的 key 其实是 seq + key 组合编码, 这里需要提取出 key
listKey, _ = db.decodeListKey(ent.Key)
}
if db.listIndex.trees[string(listKey)] == nil {
return nil
}
// 获取 list key 的 radixTree 索引对象
idxTree := db.listIndex.trees[string(listKey)]
// 在索引里获取 seq + key 的索引的 node 对象
indexVal := idxTree.Get(ent.Key)
if indexVal == nil {
// 为空则说明已被删除,直接返回 nil 即可,调用方忽略该 entry.
return nil
}
node, _ := indexVal.(*indexNode)
// 索引中有该值,且 fid 和 offset 跟传入的一致,则说明 entry 有效,需要重写到当前活跃的 logfile 日志文件里.
if node != nil && node.fid == fid && node.offset == offset {
valuePos, err := db.writeLogEntry(ent, List)
if err != nil {
return err
}
if err = db.updateIndexTree(idxTree, ent, valuePos, false, List); err != nil {
return err
}
}
return nil
}
// ...
}
hash 字典的 GC 垃圾回收实现
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
// ...
maybeRewriteHash := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// 加锁,放锁
db.hashIndex.mu.Lock()
defer db.hashIndex.mu.Unlock()
// 从 key 中解码出 key 及 field.
key, field := db.decodeKey(ent.Key)
// 为空,说明该 hash key 被删除,无需重写了.
if db.hashIndex.trees[string(key)] == nil {
return nil
}
// 获取 hash key 对应的 radixTree 基数树索引对象
idxTree := db.hashIndex.trees[string(key)]
// 获取 field 的索引的 node 节点
indexVal := idxTree.Get(field)
if indexVal == nil {
// 已被删除
return nil
}
node, _ := indexVal.(*indexNode)
// 索引中有该值,且 fid 和 offset 跟传入的一致,则说明 entry 有效,需要重写到当前活跃的 logfile 日志文件里.
if node != nil && node.fid == fid && node.offset == offset {
// 写入 entry
valuePos, err := db.writeLogEntry(ent, Hash)
if err != nil {
return err
}
// 更新索引
entry := &logfile.LogEntry{Key: field, Value: ent.Value}
_, size := logfile.EncodeEntry(ent)
valuePos.entrySize = size
if err = db.updateIndexTree(idxTree, entry, valuePos, false, Hash); err != nil {
return err
}
}
return nil
}
}
Set 集合的 GC 垃圾回收实现
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
maybeRewriteSets := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// 加锁,放锁
db.setIndex.mu.Lock()
defer db.setIndex.mu.Unlock()
if db.setIndex.trees[string(ent.Key)] == nil {
return nil
}
// 获取 set key 对应的索引对象
idxTree := db.setIndex.trees[string(ent.Key)]
if err := db.setIndex.murhash.Write(ent.Value); err != nil {
logger.Fatalf("fail to write murmur hash: %v", err)
}
// 计算 member 的哈希值
sum := db.setIndex.murhash.EncodeSum128()
db.setIndex.murhash.Reset()
// 在索引中查询该 mmeber 哈希值的数据,如为空则说明被删除.
indexVal := idxTree.Get(sum)
if indexVal == nil {
return nil
}
node, _ := indexVal.(*indexNode)
// 索引中有该值,且 fid 和 offset 跟传入的一致,则说明 entry 有效,需要重写到当前活跃的 logfile 日志文件里.
if node != nil && node.fid == fid && node.offset == offset {
// rewrite entry
valuePos, err := db.writeLogEntry(ent, Set)
if err != nil {
return err
}
// update index
entry := &logfile.LogEntry{Key: sum, Value: ent.Value}
_, size := logfile.EncodeEntry(ent)
valuePos.entrySize = size
if err = db.updateIndexTree(idxTree, entry, valuePos, false, Set); err != nil {
return err
}
}
return nil
}
// ...
}
zset (sorted set 有序集合) 的 GC 垃圾回收实现
func (db *RoseDB) doRunGC(dataType DataType, specifiedFid int, gcRatio float64) error {
// ...
maybeRewriteZSet := func(fid uint32, offset int64, ent *logfile.LogEntry) error {
// 放锁, 加锁
db.zsetIndex.mu.Lock()
defer db.zsetIndex.mu.Unlock()
// 从 entry key 中解码获取 key.
key, _ := db.decodeKey(ent.Key)
// 判空,如果为空,说明该 zset 被删除了,自然无需被重写了.
if db.zsetIndex.trees[string(key)] == nil {
return nil
}
// 获取 zset key 关联的 radixTree 索引对象
idxTree := db.zsetIndex.trees[string(key)]
// 计算获取 member 的哈希值
if err := db.zsetIndex.murhash.Write(ent.Value); err != nil {
}
sum := db.zsetIndex.murhash.EncodeSum128()
db.zsetIndex.murhash.Reset()
// 索引中获取 member 哈希值的索引节点数据.
indexVal := idxTree.Get(sum)
if indexVal == nil {
return nil
}
node, _ := indexVal.(*indexNode)
// 索引中有该值,且 fid 和 offset 跟传入的一致,则说明 entry 有效,需要重写到当前活跃的 logfile 日志文件里.
if node != nil && node.fid == fid && node.offset == offset {
valuePos, err := db.writeLogEntry(ent, ZSet)
if err != nil {
return err
}
entry := &logfile.LogEntry{Key: sum, Value: ent.Value}
_, size := logfile.EncodeEntry(ent)
valuePos.entrySize = size
if err = db.updateIndexTree(idxTree, entry, valuePos, false, ZSet); err != nil {
return err
}
}
return nil
}
// ...
}
总结
使用 bitcask 模型实现的 kv 存储引擎不会直接原理删除数据,而是通过 compaction gc 合并垃圾回收的方式来释放空间。 社区基于 bitcask 的 rosedb 和 nutsdb 当然也这么设计的。
rosedb 在删除数据时,先在 logfile 日志里写一条带 delete 标记的数据,然后在内存索引里剔除数据。更新数据写到 logfile 里,然后在索引中更新文件位置。 不断的更新和删除操作下,当 logfile 的垃圾数据占比超过 GC 阈值时,则会被垃圾回收器处理。

