
前言:
我们在实现服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等。其中哈希算法是最为常用的算法.
典型的应用场景是: 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服务。
常用的算法是对hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的 hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,但是如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计 算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算。对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)。那么,如何设 计一个负载均衡策略,使得受到影响的请求尽可能的少呢?
在Memcached、Key-Value Store、Bittorrent DHT、LVS中都采用了Consistent Hashing算法,可以说Consistent Hashing 是分布式系统负载均衡的首选算法。
关于Consistent Hashing的原理,大家可以看看下面的图,也就理解大半了。
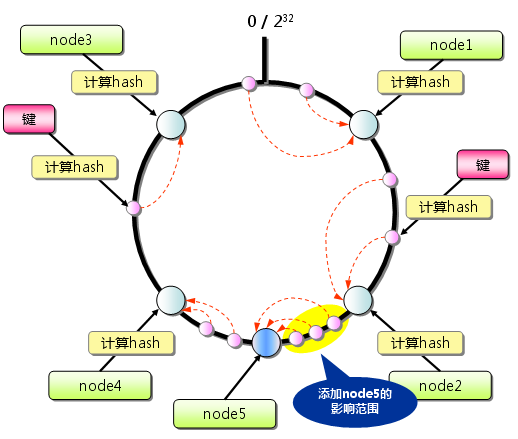
Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
关于一致性hash,已经有了python的实现 。
import md5
class HashRing(object):
def __init__(self, nodes=None, replicas=3):
"""Manages a hash ring.
`nodes` is a list of objects that have a proper __str__ representation.
`replicas` indicates how many virtual points should be used pr. node,
replicas are required to improve the distribution.
"""
self.replicas = replicas
self.ring = dict()
self._sorted_keys = []
if nodes:
for node in nodes:
self.add_node(node)
def add_node(self, node):
"""Adds a `node` to the hash ring (including a number of replicas).
"""
for i in xrange(0, self.replicas):
key = self.gen_key('%s:%s' % (node, i))
self.ring[key] = node
self._sorted_keys.append(key)
self._sorted_keys.sort()
def remove_node(self, node):
"""Removes `node` from the hash ring and its replicas.
"""
for i in xrange(0, self.replicas):
key = self.gen_key('%s:%s' % (node, i))
del self.ring[key]
self._sorted_keys.remove(key)
def get_node(self, string_key):
"""Given a string key a corresponding node in the hash ring is returned.
If the hash ring is empty, `None` is returned.
"""
return self.get_node_pos(string_key)[0]
def get_node_pos(self, string_key):
"""Given a string key a corresponding node in the hash ring is returned
along with it's position in the ring.
If the hash ring is empty, (`None`, `None`) is returned.
"""
if not self.ring:
return None, None
key = self.gen_key(string_key)
nodes = self._sorted_keys
for i in xrange(0, len(nodes)):
node = nodes[i]
if key <= node:
return self.ring[node], i
return self.ring[nodes[0]], 0
def get_nodes(self, string_key):
"""Given a string key it returns the nodes as a generator that can hold the key.
The generator is never ending and iterates through the ring
starting at the correct position.
"""
if not self.ring:
yield None, None
node, pos = self.get_node_pos(string_key)
for key in self._sorted_keys[pos:]:
yield self.ring[key]
while True:
for key in self._sorted_keys:
yield self.ring[key]
def gen_key(self, key):
"""Given a string key it returns a long value,
this long value represents a place on the hash ring.
md5 is currently used because it mixes well.
"""
m = md5.new()
m.update(key)
return long(m.hexdigest(), 16)
如果你想更方便的实现一致性hash,那就用hash_ring 。这个库已经在我们的分布式爬虫系统中用到了,用来判断爬虫抓取到的新的url,是否真的可用。
原文: http://blog.xiaorui.cc/
In [1]: from hash_ring import *
In [2]: memcache_servers = ['192.168.0.246:11212',
...: '192.168.0.247:11212',
...: '192.168.0.249:11212']
In [3]:
In [3]: ring = HashRing(memcache_servers)
In [4]: server = ring.get_node('my_key')
In [5]:
In [5]: server
Out[5]: '192.168.0.247:11212'
In [6]:
In [6]:
In [6]:
In [6]: server
Out[6]: '192.168.0.247:11212'
In [7]: server = ring.get_node('my_keysdfsdf')
In [8]: server
Out[8]: '192.168.0.249:11212'
有了一致性hash,你可以最小程度的减轻因为增加或者是减少服务器带来的大量的缓存MISS 。

