
昨天跟你朋友聊了下他们的日志收集及实时的触发报警,当然需要说明的是他们的环境不大,一个小创业公司,开发和运维的环境也相对的简单干练… … 他们没有用到elk这样的日志收集方案,是直接修改了在python logging模块上加了层kafka的输出。 然后他们在消费kafka写到hdfs里面,顺便做了个报警。 报警也是有些逻辑的,不是简简单单的看到Error就报警, 是在一定时间内收集到多少数目达到了先前的阈值后才报警。 有时候日志问题可能是链条性质的,举个例子 , A 导致了B,B导致了C 。 当我们看到A的错误的时候,就把B和C的错误都统统的过滤掉。
关于日志报警的优化,我以前写过相关的文章,有兴趣的朋友可以找找,明确的解释了 那些过滤和汇总的实现。
其实以前在乐视的时候把一堆关于热门视频计算节点的logging都加了层redis输出… 但是会碰到一个问题就是,如果因为某种问题导致python疯狂的向redis写入数据,会造成redis的卡顿,因为是根别的业务混布的,又因为我的其他的管理平台也用这台redis….. 所以时不时的会有些影响… 不扯淡了,kafka在mq的功能和性能上要比redis强的,毕竟redis不只是消息队列.
通过在O(1)的磁盘数据结构上提供消息持久化,对于即使数以TB的消息存储也能够保持长时间的稳定性能。在商用机器上可以提供每秒数十万条的消息,redis的测试结果一般是在2w左右就有些吃力了….
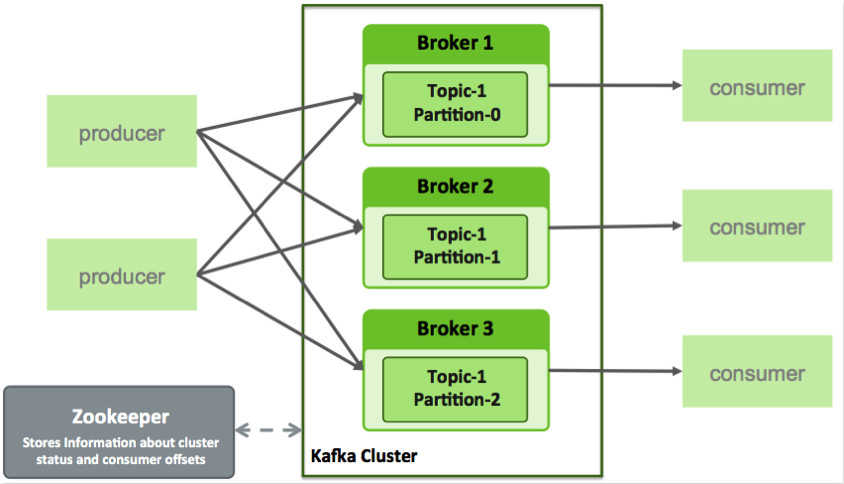
支持在Kafaka服务器集群上进行messages分片,并在把messages在消费集群的机器上分配的同时维护每个分片的顺序信息。kafka配合zookeeper特么很容易实现分布式,他有topic的概念,可以把点击事件的日志推倒topic1,nginx日志推倒topic2 等。 每个topic对应的物理的parition分组,kafka把parition大文件切成一个个的小文件,这样容易做日志的过期删除。
安装很是简单…
$ git clone https://github.com/taykey/python-kafka-logging/
$ sudo apt-get install python-virtualenv
$ virtualenv python-kafka-logging-ve
$ python-kafka-logging-ve/bin/pip install -r requirements.txt
我们看看他的实现逻辑,没啥东西,只是个干净的功能类而已。
from kafka.client import KafkaClient
from kafka.producer import SimpleProducer, KeyedProducer
import logging
import traceback
import sys
class KafkaLoggingHandler(logging.Handler):
def __init__(self, hosts_list, topic, key=None):
logging.Handler.__init__(self)
self.kafka_client = KafkaClient(hosts_list)
self.key = key
self.kafka_topic_name = topic
if not key:
self.producer = SimpleProducer(self.kafka_client)
else:
self.producer = KeyedProducer(self.kafka_client)
def emit(self, record):
# drop kafka logging to avoid infinite recursion
if record.name == 'kafka':
return
try:
# use default formatting
msg = self.format(record)
# produce message
if not self.key:
self.producer.send_messages(self.kafka_topic_name, msg)
else:
self.producer.send(self.kafka_topic_name, self.key, msg)
except (KeyboardInterrupt, SystemExit):
raise
except:
self.handleError(record)
def close(self):
self.producer.stop()
logging.Handler.close(self)
这是logging.conf的配置
[loggers]
keys=root
[handlers]
keys=consoleHandler,fileHandler,kafkaHandler
[formatters]
keys=simpleFormatter,logstashFormatter
[logger_root]
level=DEBUG
handlers=consoleHandler,fileHandler,kafkaHandler
formatter=simpleFormatter
[handler_fileHandler]
class=logging.handlers.WatchedFileHandler
level=DEBUG
formatter=simpleFormatter
args=('logs/app.log', 'a')
[handler_kafkaHandler]
class=python-kafka-logging.KafkaHandler.KafkaLoggingHandler
level=DEBUG
formatter=logstashFormatter
args=("kafka-srv1:port, kafka-srv2:port, kafka-srv3:port", "topic_name")
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=simpleFormatter
args=(sys.stdout,)
[formatter_simpleFormatter]
format=%(asctime)s - %(levelname)s - %(name)s - %(message)s
[formatter_logstashFormatter]
class=logstash_formatter.LogstashFormatter
format={"extra": {"appName": "myPythonApp", "environment": "AWS-Test"}}



哥 你太nb了