
为什么会用AC自动机? 如果你想知道一篇文章有没有你要过滤的敏感词,怎么办? 不可能用正则一个个的匹配吧? 敏感词超过300个之后,用Trie来构建模式树 (字典树)的速度优势相当的明显… …
Hello Boys , 文章的原文转自 http://xiaorui.cc http://xiaorui.cc/?p=1649
特别说下,trie图也是一种DFA,可以由trie树为基础构造出来,对于插入的每个模式串,其插入过程中使用的最后一个节点都作为DFA的一个终止节点。
如果要求一个母串包含哪些模式串,以用母串作为DFA的输入,在DFA 上行走,走到终止节点,就意味着匹配了相应的模式串。
ps: AC自动机是Trie的一种实现,也就是说AC自动机是构造Trie图的DFA的一种方法。还有别的构造DFA的方法…
不扯淡了,我们后端都是python写的,python的ahocorasick模块跟我们的业务不太匹配,问题是这样的 ! 如果你的服务是用来做敏感词匹配,也就是说所有文章里面只要含有一个关键词,那就说明匹配了。 但是我们的业务是文章中的所有能匹配到的关键词都一一的抽取出来。 我想有些朋友可能还不太明白,那么我举个例子, 如果我的关键词里面有宝马和马,那么用python的ahocorasick库只会得到宝马,而不会得到马。 问题是处在马这个字节是在宝马的链条里面的。 如何避开这个问题,我们也懒得自己重写了,已经有人给出了解决的模块。 已经测试完成,并上线使用了。
安装简单,直接pip install esmre
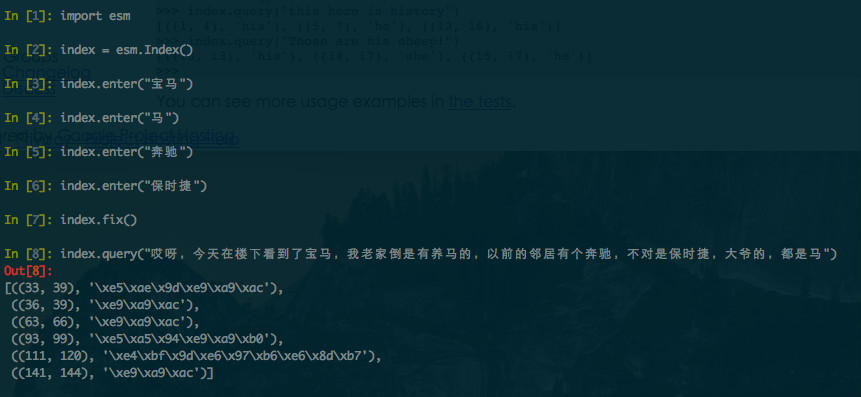
import esm
index = esm.Index()
index.enter("宝马")
index.enter("马")
index.enter("奔驰")
index.enter("保时捷")
index.fix()
index.query("哎呀,今天在楼下看到了宝马,我老家倒是有养马的,以前的邻居有个奔驰,不对是保时捷,大爷的,都是马")
再来一个完整的例子. 后续有时间我会把ac自动机的服务集成到rpc服务里面,然后用docker打包。
#coding:utf-8
import esm
index = esm.Index()
with open('keyword.config','r') as f:
for i in f.readlines():
index.enter(i.strip())
index.fix()
str = """
head&shoulders海飞丝Hershey‘s
Loreal欧莱雅LUX2
力士
L’OREALMagic2
美即
MysteryCity
谜城
NO.1BABY2
RESIN
SANXIAO
SHISEIDO FINE TOILETRY2
SKII美之匙
Tao yu tang2
淘雨堂
whoo倍加洁
卡尔林奈
娇韻诗
德国帮宝适
Perfect puff2
See Young2
落健
高夫
"""
data = index.query(str)
print data
测了几天,性能还是可以的,500KB的文章,6000多个关键词,消耗的时间在0.002左右,相比ahocorasick一点都不差的。 观察了下,esmre是没有发现内存异常泄露等问题。

[2015-06-12 23:34:01,043] INFO extractor "Get keywords takes 0.0003 seconds" [2015-06-12 23:34:01,069] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:01,178] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:02,372] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:02,386] INFO extractor "Get keywords takes 0.0012 seconds" [2015-06-12 23:34:02,631] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:03,656] INFO extractor "Get keywords takes 0.0021 seconds" [2015-06-12 23:34:03,744] INFO extractor "Get keywords takes 0.0001 seconds" [2015-06-12 23:34:03,785] INFO extractor "Get keywords takes 0.0001 seconds" [2015-06-12 23:34:03,910] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:04,031] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:05,004] INFO extractor "Get keywords takes 0.0035 seconds" [2015-06-12 23:34:05,579] INFO extractor "Get keywords takes 0.0055 seconds" [2015-06-12 23:34:05,602] INFO extractor "Get keywords takes 0.0005 seconds" [2015-06-12 23:34:05,662] INFO extractor "Get keywords takes 0.0010 seconds" [2015-06-12 23:34:06,125] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:06,299] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:06,404] INFO extractor "Get keywords takes 0.0003 seconds" [2015-06-12 23:34:07,396] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:07,595] INFO extractor "Get keywords takes 0.0004 seconds" [2015-06-12 23:34:08,725] INFO extractor "Get keywords takes 0.0015 seconds" [2015-06-12 23:34:09,504] INFO extractor "Get keywords takes 0.0004 seconds" [2015-06-12 23:34:09,515] INFO extractor "Get keywords takes 0.0005 seconds" [2015-06-12 23:34:10,650] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:11,206] INFO extractor "Get keywords takes 0.0003 seconds" [2015-06-12 23:34:12,298] INFO extractor "Get keywords takes 0.0002 seconds" [2015-06-12 23:34:12,319] INFO extractor "Get keywords takes 0.0001 seconds" [2015-06-12 23:34:13,547] INFO extractor "Get keywords takes 0.0006 seconds" [2015-06-12 23:34:13,853] INFO extractor "Get keywords takes 0.0005 seconds"


