
这两天针对Influxdb有些不爽,主要还是体现在的他性能方面。下面的内容是我这两天总结,应该对大家有些帮助,那么需要说明的是,我用influxdb做时序数据库的应用场景很小,也就是一百多个爬虫节点和数据抽取平台的,加起来不到150个节点的。 当然还没有在线上跑,这段时间一直在做关于metric方面的测试,influxdb已经达到了我的对于业务的各种需求,逻辑存储,各种时间段数据的计算,及前端的展现。 我个人对于grafana的页面不是太关注,因为自己写起来,也就那回事。 只是没有grafana那么绚丽而已。 不扯淡了,开始正题… …
Influxdb已经有了lru缓存,不需要咱们自己在做一个数据缓存了,如果你的内存够大,完全可以把Lru的内存设置大点, 我是16g的内存,默认是200m ,我调节到4G,性能优势相当的明显。 下面是我在函数执行前加了一组timeit统计,第一次没有缓存前是5s左右,第二次访问的时候,直接命中缓存。
used 5.55562400818 used 5.56077003479 used 5.54552102089 used 5.56958198547 used 5.5698800087 used 5.56984591484 used 5.58757805824 used 5.58937096596 used 5.59354400635 used 0.0429439544678 used 0.0356860160828 used 0.0792279243469 used 0.0626089572906 used 0.109939098358 used 0.108834028244 used 0.105827093124 used 0.130222082138 used 0.129088878632 used 0.157034873962 used 0.0657110214233
Influxdb是支持udp协议的,有些类似graphite的接受模式。也可以直接把给graphite server的sender指向给Influxdb,collectd也可以这么搞。因为Influxdb为了更大程度的让自己牛逼起来,做了针对别人收集系统的格式解析,他倒是省事呀。
数据库的引擎默认的rocksdb就行,别在折腾用leveldb了,速度确实和官方的介绍一样,比leveldb要快。一些论坛说hyperleveldb更加的厉害,相比leveldb增加了并行和压缩调整吞吐量,说实话,我切换了引擎测试了下,真的不咋地。 write-buffer-size这是的buffer的值,也可以适当的配置大一点。
Influxdb在并发的情况,他自己会实现一组batch的批量刷新策略。
# http://xiaorui.cc bind-address = "0.0.0.0" reporting-disabled = false [logging] level = "info" file = "/opt/influxdb/shared/log.txt" # stdout to log to standard out, or syslog facility [admin] port = 8083 # binding is disabled if the port isn't set [api] port = 8086 # binding is disabled if the port isn't set read-timeout = "5s" [input_plugins] # Configure the graphite api [input_plugins.graphite] enabled = false # address = "0.0.0.0" # If not set, is actually set to bind-address. # port = 2003 # database = "" # store graphite data in this database # udp_enabled = true # enable udp interface on the same port as the tcp interface # Configure the collectd api [input_plugins.collectd] enabled = false # address = "0.0.0.0" # If not set, is actually set to bind-address. # port = 25826 # database = "" # types.db can be found in a collectd installation or on github: # https://github.com/collectd/collectd/blob/master/src/types.db # typesdb = "/usr/share/collectd/types.db" # The path to the collectd types.db file # Configure the udp api [input_plugins.udp] enabled = false # port = 4444 # database = "" # Configure multiple udp apis each can write to separate db. Just # repeat the following section to enable multiple udp apis on # different ports. [[input_plugins.udp_servers]] # array of tables enabled = false # port = 5551 # database = "db1" [raft] port = 8090 dir = "/opt/influxdb/shared/data/raft" debug = false [storage] dir = "/opt/influxdb/shared/data/db" write-buffer-size = 20000 default-engine = "rocksdb" max-open-shards = 0 point-batch-size = 500 write-batch-size = 8000000 retention-sweep-period = "30m" [storage.engines.leveldb] max-open-files = 1000 lru-cache-size = "200m" [storage.engines.rocksdb] max-open-files = 1000 lru-cache-size = "4000m" [storage.engines.hyperleveldb] max-open-files = 1000 lru-cache-size = "200m" [storage.engines.lmdb] map-size = "100g" [cluster] protobuf_port = 8099 protobuf_timeout = "2s" # the write timeout on the protobuf conn any duration parseable by time.ParseDuration protobuf_heartbeat = "200ms" # the heartbeat interval between the servers. must be parseable by time.ParseDuration protobuf_min_backoff = "1s" # the minimum backoff after a failed heartbeat attempt protobuf_max_backoff = "10s" # the maxmimum backoff after a failed heartbeat attempt write-buffer-size = 1000 max-response-buffer-size = 100 concurrent-shard-query-limit = 10 [wal] dir = "/opt/influxdb/shared/data/wal" flush-after = 1000 # the number of writes after which wal will be flushed, 0 for flushing on every write bookmark-after = 1000 # the number of writes after which a bookmark will be created index-after = 1000 requests-per-logfile = 10000
那么我们再来看Influxdb的文件存储的目录结构。
/opt/influxdb/shared/data/db/shard_db_v2
├── 00001
│ ├── 000008.log
│ ├── 000010.sst
│ ├── CURRENT
│ ├── IDENTITY
│ ├── LOCK
│ ├── LOG
│ ├── MANIFEST-000006
│ └── type
└── 00002
├── 004058.sst
├── 004795.sst
├── 004796.sst
├── 005139.sst
├── 005709.sst
├── 005812.sst
├── 005813.sst
├── 005815.sst
├── 005853.sst
├── 005861.sst
├── 005864.sst
├── 006300.sst
├── 006301.sst
├── 006306.sst
├── 006347.sst
├── 006348.sst
├── 006459.sst
├── 006460.sst
├── 006461.sst
├── 006462.sst
├── 006463.sst
├── 006469.sst
├── 006471.sst
├── 006558.sst
├── 006559.sst
├── 006565.sst
├── 006566.sst
├── 006712.sst
├── 006713.sst
├── 006729.sst
├── 006730.sst
├── 006781.sst
├── 006825.sst
├── 006830.sst
├── 006887.sst
├── 006888.sst
├── 006941.sst
├── 006942.sst
├── 006947.sst
├── 006987.sst
对于select查询语句的优化,尽量不要一次性的把一段时间的value都取出来,我个人经验是,你自己经过influxdb计算后,再返回前端能更好点。
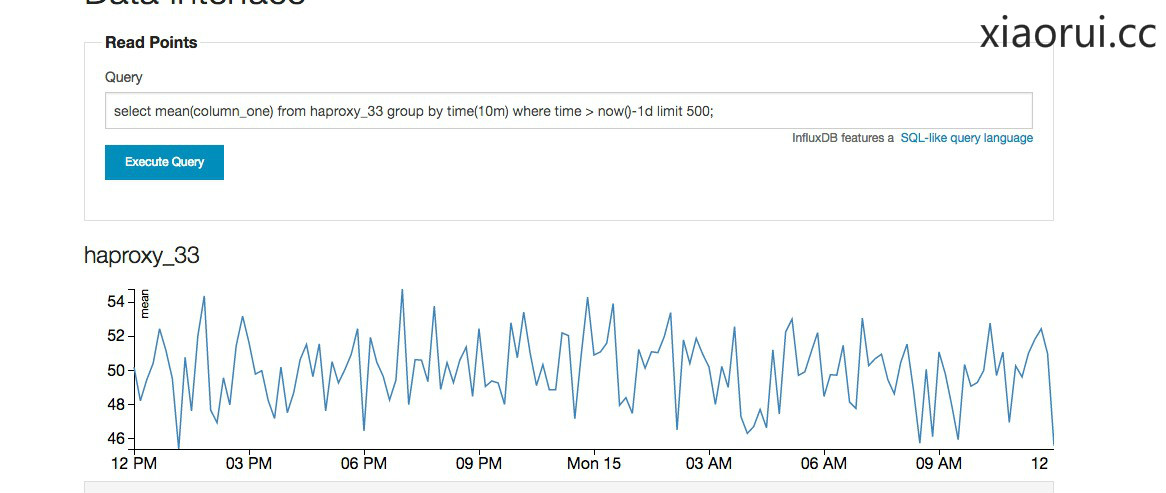
下面这个语句是,查询haproxy_33代理的数据,按照10m合并计算,计算的策略是用mean,也就是平均值的函数,后面紧接着时间间隔和limit 500 。
一句话,尽量找计算,如果有可以,一定要加时间限制或者是limit的限制。
select mean(column_one) from haproxy_33 group by time(10m) where time > now()-1d limit 500;
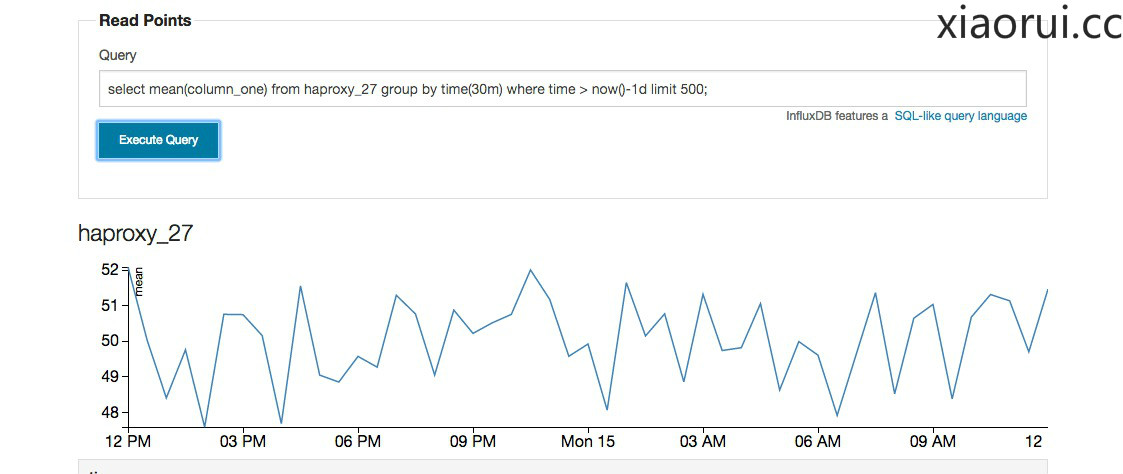
group by time(30m)
group by time(10m)
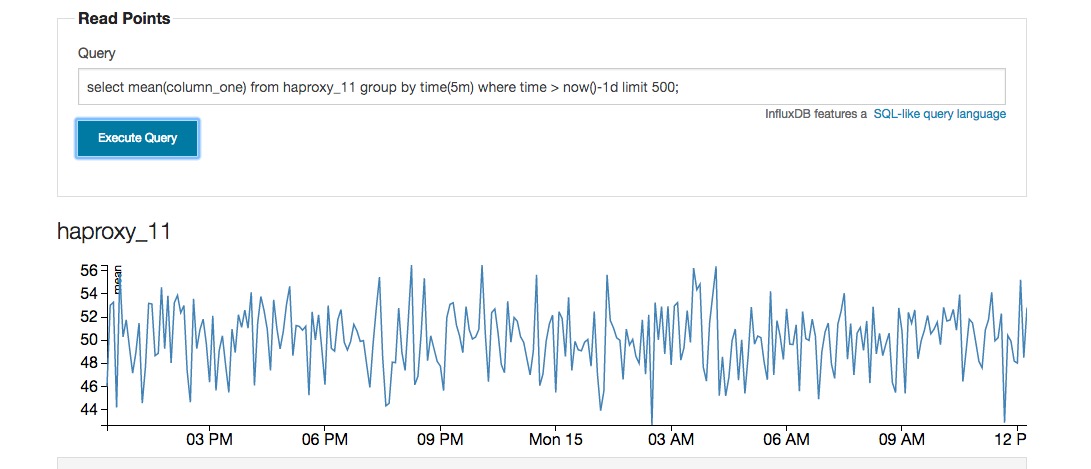
group by time(5m)
Q&A:
1. influxdb是否可以限制内存大小的使用限制.
据我所知是不行,配置文件没有关于内存限制配置参数,提交过issue,得到的答案也没听懂. 大家可以尝试用docker,cgroup限制内存. 当然在外层进行控制不太合理.
https://groups.google.com/forum/#!topic/influxdb/jURMcIM5xBs
2. 有朋友说,他的insert插入数据的速度过慢.
尝试使用他的批量接口,性能提升很是明显,influxdb集群的环境下QPS可以到近1W.


鼓励点击不怕 adsense 被封吗
(^o^)/~ ,封了更好. 反正也没几个钱.
你好,我在单机上测试插入性能,用http接口每秒只能写入400+次,由于无法完全使用批量插入,所以这性能有点接受不能,请问这是正常的吗?
不是批量的操作也应该可以干到最少1K,当你写入的时候influxdb server出现什么明显的波动? 排查下,应该能找到一些原因。
我也对Influxdb的读写性能做了测试,结果还是符合需求的,只是内存测试的时候发现它直到渐渐把空余内存吃光了才会主动释放一些内存。看文中提到设置lru大小什么的,请问能设置influxdb使用内存的上限吗?
请问0.9是不是lru设置去掉了?
没有吧…
最近用的一个场景每秒1000条写入。写入的性能是很不错了,查询时候就不行了,非常慢。对当日的数据查询,group by time(1m) 怎么也得有个10秒才能返回。
查询性能是很让人伤心。。。
官方貌似说 : 副本数量 × 分片数量 = 集群数量,我看你副本数量是2,但是你的集群是3?是因为这问题吗?http://influxdb.com/docs/v0.8/advanced_topics/sharding_and_storage.html#databases-and-shard-spacesThe replicationFactor setting tells the InfluxDB cluster how many servers should have a copy of each shard in the given shard space. Finally, split tells the cluster how many shards to create for a given interval of time. Data for that interval will be distributed across the shards. This setting is how you achieve write scalability. You may want to have replicationFactor * split == number of servers. That will ensure that every server in the cluster will be hot for writes at any given time.
哈哈,看样子是这个问题。 我对influxdb的集群理解不深
我现在是通过zabbix 的api 从zaxbbix 把一些数据 抓取出来写入 influxdb ,然后前端由 grafana,暂时,influxdb 集群 是不是和es 一样没有中心节点,有这方面的介绍吗?
应该是,但是集群貌似有出一些奇怪的问题 ,正常情况下还是很美好的。replication-factor = 2seed-servers = [“node1:8090”, “node2:8090”, “node3:8090”]