
leader election 选举的例子
这是一个使用 clinet-go leader election 库进行选举的例子, 单从使用来说没什么难度.
首先实例化一个 resourcelock.LeaseLock 对象, 需要定义锁的名字, 命名空间及唯一identity. 然后调用 leaderelection 的 RunOrDie 接口进行选举.
重点介绍下 leaderelection.LeaderElectionConfig 字段含义:
- LeaseDuration: 锁的时长, 通过该值判断是否超时, 超时则认定丢失锁
- RenewDeadline: 续约时长, 每次 lease ttl 的时长
- retryPeriod: 周期进行重试抢锁的时长
- Callbacks, 注册的自定义方法
- OnStartedLeading: 作为 leader 启动时进行回调
- OnStoppedLeading: 关闭时进行回调
- OnNewLeader: 转换为 leader 时进行回调
package main
import (
"context"
"flag"
"os"
"time"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
clientset "k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/leaderelection"
"k8s.io/client-go/tools/leaderelection/resourcelock"
"k8s.io/klog"
)
var (
client *clientset.Clientset
)
func getNewLock(lockname, podname, namespace string) *resourcelock.LeaseLock {
return &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{
Name: lockname,
Namespace: namespace,
},
Client: client.CoordinationV1(),
LockConfig: resourcelock.ResourceLockConfig{
Identity: podname,
},
}
}
func doStuff() {
for {
klog.Info("request xiaorui.cc")
time.Sleep(5 * time.Second)
}
}
func runLeaderElection(lock *resourcelock.LeaseLock, ctx context.Context, id string) {
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
Lock: lock,
ReleaseOnCancel: true,
LeaseDuration: 15 * time.Second,
RenewDeadline: 10 * time.Second,
RetryPeriod: 2 * time.Second,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(c context.Context) {
doStuff()
},
OnStoppedLeading: func() {
klog.Info("no longer the leader, staying inactive.")
},
OnNewLeader: func(current_id string) {
if current_id == id {
klog.Info("still the leader!")
return
}
klog.Info("new leader is %s", current_id)
},
},
})
}
func main() {
var (
leaseLockName string
leaseLockNamespace string
podName = os.Getenv("POD_NAME")
)
flag.StringVar(&leaseLockName, "lease-name", "", "Name of lease lock")
flag.StringVar(&leaseLockNamespace, "lease-namespace", "default", "Name of lease lock namespace")
flag.Parse()
if leaseLockName == "" {
klog.Fatal("missing lease-name flag")
}
if leaseLockNamespace == "" {
klog.Fatal("missing lease-namespace flag")
}
config, err := rest.InClusterConfig()
client = clientset.NewForConfigOrDie(config)
if err != nil {
klog.Fatalf("failed to get kubeconfig")
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
lock := getNewLock(leaseLockName, podName, leaseLockNamespace)
runLeaderElection(lock, ctx, podName)
}
kube-scheduler 和 kube-manager-controller 选举的实现 ?
kube-scheduler 和 kube-manager-controller 为了实现保证高可用性,通常会启动启动个实例副本,但多个实例同时使用 informer 去监听处理必然会出现不一致或者重复执行的问题.
为了规避这个问题 kubernetes 中是通过 leaderelection 来实现选举, 只有一个实例能拿到锁, 拿到锁的实例才可以运行, 其他实例拿不到锁后会不断重试.
需要注意的是当某个 leader 实例由于不可控的原因不再续约或锁丢失时, 会触发 OnStoppedLeading 方法, 该方法会刷新日志后退出进程, 后面其他实例会竞争锁, 拿到锁的实例执行逻辑.
先前的 leader 实例在进程退出后, 会被 docker 或者 systemd 再次拉起, 拉起后再次尝试竞争锁, 拿不到锁就不断重试.
下面是 kube-manager-controller 选举的代码:
func Run() {
go leaderElectAndRun(c, id, electionChecker,
c.ComponentConfig.Generic.LeaderElection.ResourceLock,
c.ComponentConfig.Generic.LeaderElection.ResourceName,
leaderelection.LeaderCallbacks{
// 竞争 leader 成功后, 回调该方法
OnStartedLeading: func(ctx context.Context) {
initializersFunc := NewControllerInitializers
run(ctx, startSATokenController, initializersFunc)
},
// 丢失 leader 后, 回调该方法
OnStoppedLeading: func() {
// 刷新日志然后退出进程
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
},
}
)
}
func leaderElectAndRun(c *config.CompletedConfig, lockIdentity string, electionChecker *leaderelection.HealthzAdaptor, resourceLock string, leaseName string, callbacks leaderelection.LeaderCallbacks) {
rl, err := resourcelock.NewFromKubeconfig(resourceLock,
c.ComponentConfig.Generic.LeaderElection.ResourceNamespace,
leaseName,
resourcelock.ResourceLockConfig{
Identity: lockIdentity, // 随机id
},
c.Kubeconfig,
c.ComponentConfig.Generic.LeaderElection.RenewDeadline.Duration)
if err != nil {
klog.Fatalf("error creating lock: %v", err)
}
// 竞争锁
leaderelection.RunOrDie(context.TODO(), leaderelection.LeaderElectionConfig{
Lock: rl,
// 租约有效时长, 超过时长认定丢失
LeaseDuration: c.ComponentConfig.Generic.LeaderElection.LeaseDuration.Duration,
// 更新续约时长
RenewDeadline: c.ComponentConfig.Generic.LeaderElection.RenewDeadline.Duration,
// 重试间隔
RetryPeriod: c.ComponentConfig.Generic.LeaderElection.RetryPeriod.Duration,
Callbacks: callbacks,
WatchDog: electionChecker,
Name: leaseName,
})
}
为什么从 leader 转变为 candidate 候选者时, 粗暴退出?
可以发现 kube-scheduler 和 kube-manager-controller 的代码设计, 当 leader 节点出于各种的异常, 导致不是 leader 节点时, 为什么需要进程直接退出, 而没有做到优雅退出?
首先 kube-manager-controller 里面的十几个 controller 控制器只是实现了 Run() 运行, 但没有 Stop 的方法, 其实就算实现了 Stop 退出, 也不好解决优雅退出, 因为在 controller 内部有大量的异步逻辑, 不好收敛.
另外各个 controller 的逻辑很严谨, 判断各种的状态, 在 controoler 控制器重启后也可以准确的同步配置, 最后的状态为一致性.
leaderelection 使用轮询的方式来选主抢锁吗 ?
是的, k8s leader election 抢锁选主的逻辑是周期轮询实现的, 相比社区中标准的分布式锁来说, 不仅增加了由于无效轮询带来的性能开销, 也不能解决公平性, 谁抢到了锁谁就是主 leader.
leader election 虽然有这些缺点, 但由于 k8s 里需要高可用组件就那么几个, 调度器和控制器组件开多个副本加起来也没多少个实例, 开销可以不用担心, 这些组件都是跟无状态的 apiserver 对接的, apiserver 作为无状态的服务可以横向扩展, 后端的 etcd 对付这些默认 2s 的锁请求也什么问题. 另外, 选主的逻辑不在乎公平性, 谁先谁后无所谓. 总结起来这类选举的场景, 轮询没啥问题, 实现起来也简单.
以前在 etcd v2 的时候是通过 put cas 实现的锁, 依赖关键的 prevExist 参数. 但 etcd 在 v3 的时候默认集成了 lock 的功能, 且在各个语言的 sdk 的 concurrent 里实现了 lock 功能.
简单说下 etcd v3 分布式锁的逻辑:
v3 的 lock 则是利用 lease (ttl), Revision (版本), Watch prefix 来实现的.
- 往自定义的 etcd 目录写一个 key, 并配置 key 的 lease ttl 超时
- 然后获取该目录下的所有 key. 判断当前最小 revision 的key 是否是由自身创建的, 如果是则拿到锁.
- 拿不到则监听 watch 比自身 revison 小一点的 key
- 当监听的 key 发生事件时, 则再次判断当前 key revison 是否最最小, 重新走第二个步骤.
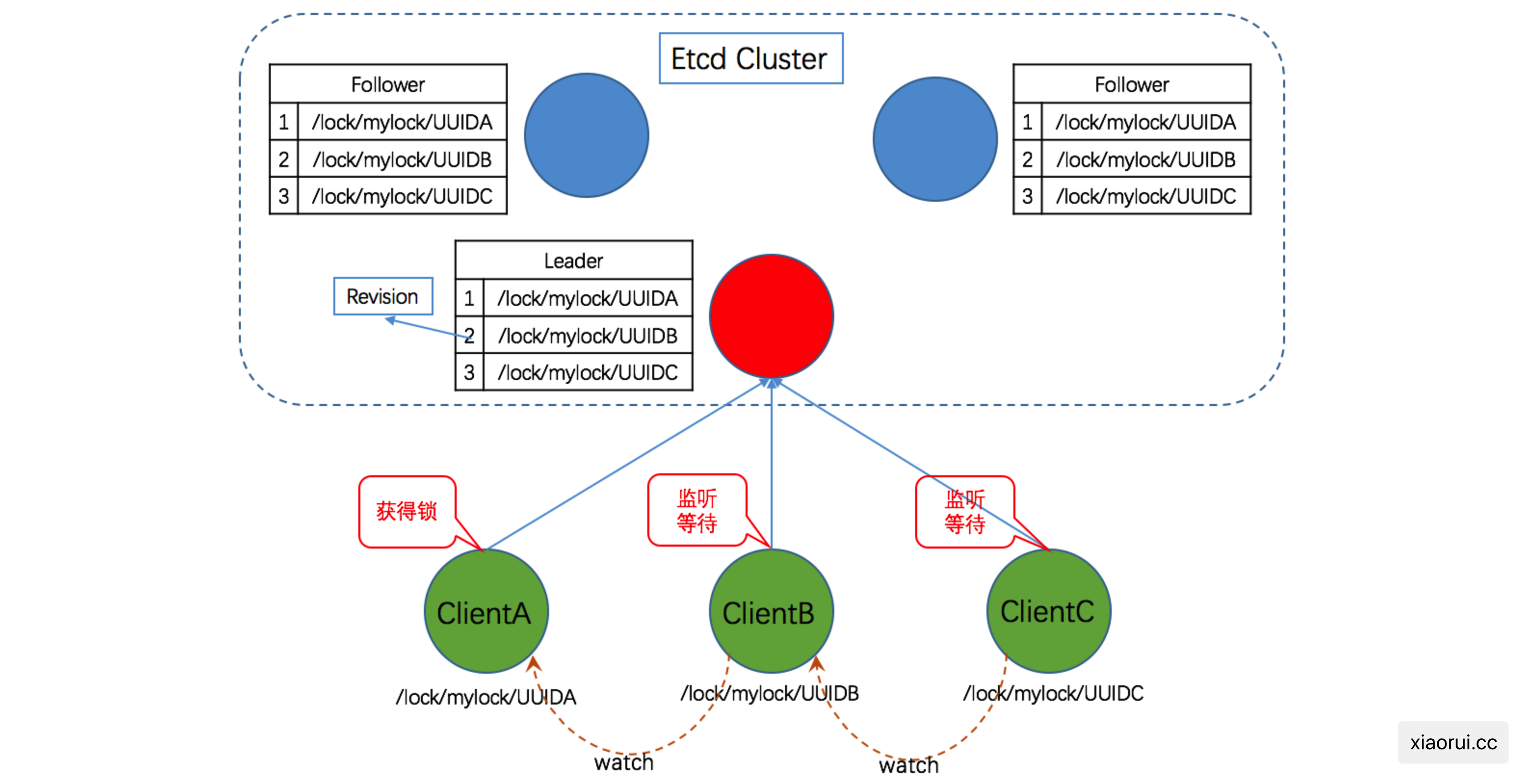
并发 leaderelection 操作是否有冲突 ?
不会的 !!!
因为 create 创建操作在 etcd 层面是原子的, 同一时间只能有一个协程可以创建成功, 另一个协程会拿到 key 已存在的错误.
另外, 更新操作则使用 etcd 软事务来实现的, 当 Identity 值一致才更新.
kube-manager-controller leader election 默认参数配置
- –leader-elect-lease-duration duration, 默认值: 15s
- –leader-elect-renew-deadline duration, 默认值: 10s
- –leader-elect-retry-period duration, 默认值: 2s
type LeaderElectionConfig struct {
// Core clients default this value to 15 seconds.
LeaseDuration time.Duration
// Core clients default this value to 10 seconds.
RenewDeadline time.Duration
// Core clients default this value to 2 seconds.
RetryPeriod time.Duration
}
代码位置: https://github.com/kubernetes/client-go/blob/master/tools/leaderelection/leaderelection.go
关于 client-go leaderelection 选举的实现原理
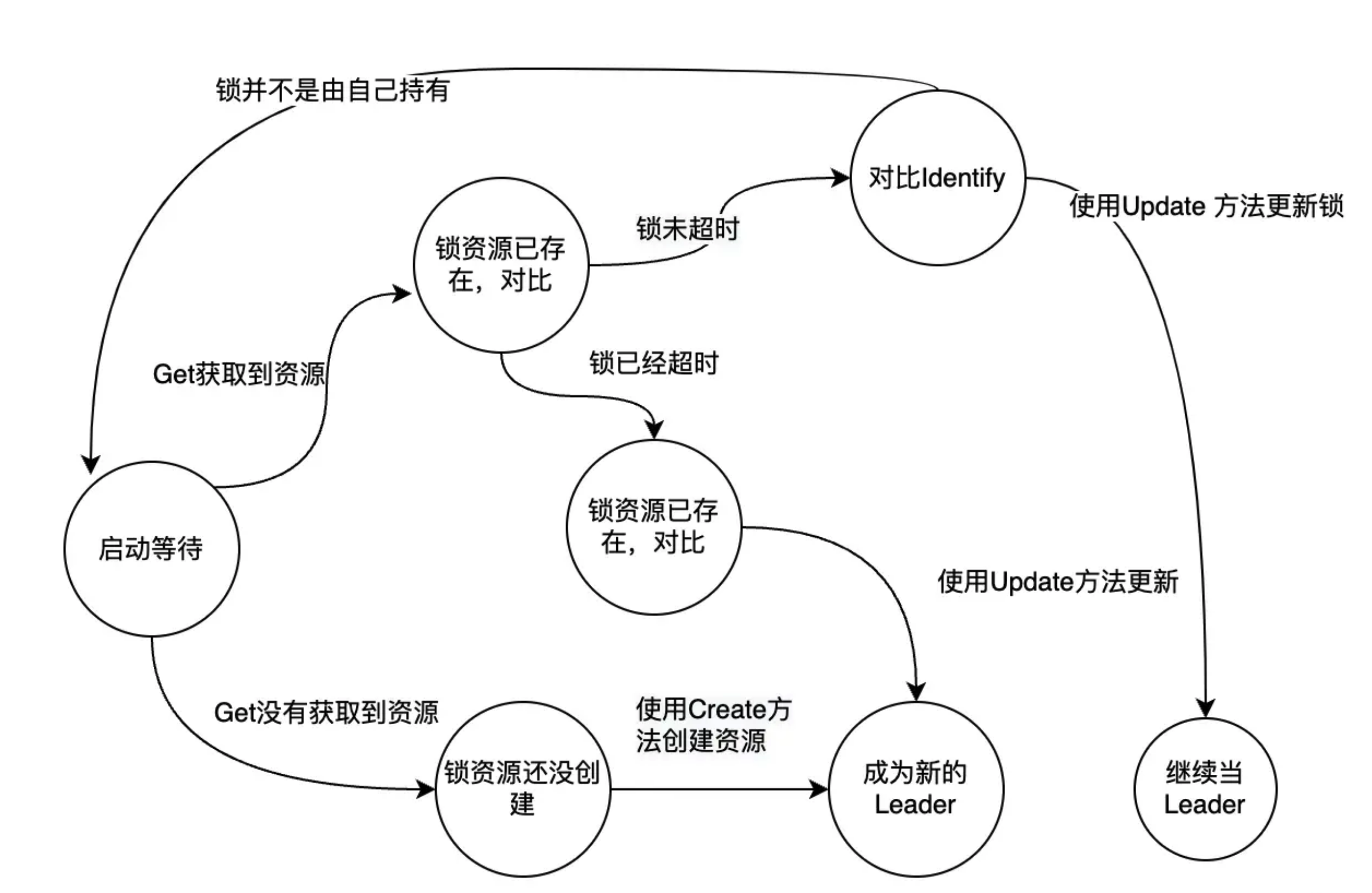
Run() 内部调用是 acquire() 不断的尝试拿锁和续约, 当拿到锁或者更新已有锁后, 调用 renew() 方法来周期性的续约.
代码位置: k8s.io/client-go/tools/leaderelection/leaderelection.go
func RunOrDie(ctx context.Context, lec LeaderElectionConfig) {
le, err := NewLeaderElector(lec)
...
if lec.WatchDog != nil {
// 在 watchDog 里配置 ld 对象
lec.WatchDog.SetLeaderElection(le)
}
// 抢锁和 renew 续约的逻辑
le.Run(ctx)
}
func (le *LeaderElector) Run(ctx context.Context) {
defer func() {
// 退出时调用注册的 OnStoppedLeading 方法, 只有 ctx 被 cancel 才会触发这个.
le.config.Callbacks.OnStoppedLeading()
}()
// 不断的重试拿锁, 每次间隔 RetryPeriod 时长, 直到拿到锁, 返回 false 为 ctx 被关闭.
if !le.acquire(ctx) {
return
}
// 派生子 ctx
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// 成功拿到锁后, 角色变更为 leader, 执行注册的 OnStartedLeading 代码
go le.config.Callbacks.OnStartedLeading(ctx)
// 循环进行租约的更新, 保证锁不丢失
le.renew(ctx)
}
acquire(ctx) 的逻辑简单, 就是使用 wait.JitterUntil 周期性的调用 tryAcquireOrRenew 方法, 周期为经过抖动的 retryPeriod 时长.
tryAcquireOrRenew 是 leaderelection 选举的关键代码, 里面不仅实现了拿锁也实现了 renew 续约逻辑.
- 首先尝试获取锁对象
- 如果没有锁对象, 那么尝试创建锁资源
- 如果拿到锁对象, 则判断是否超过 LeaseDuration 时长且当前实例不是 leader, 没有满足则直接退出
- 如果锁没有超时, 且锁的holdID 是当前实例, 则更新锁对象, 具体更新 acquireTime, renewTime, leasetDuration, holderID 等字段
func (le *LeaderElector) acquire(ctx context.Context) bool {
ctx, cancel := context.WithCancel(ctx)
defer cancel()
wait.JitterUntil(func() {
succeeded = le.tryAcquireOrRenew(ctx)
le.maybeReportTransition()
// 当返回 false 时退出
if !succeeded {
return
}
...
// 如果拿到锁, 就取消 wait.until 轮询器.
cancel()
}, le.config.RetryPeriod, JitterFactor, true, ctx.Done())
return succeeded
}
func (le *LeaderElector) tryAcquireOrRenew(ctx context.Context) bool {
now := metav1.Now()
// 锁资源对象内容
leaderElectionRecord := rl.LeaderElectionRecord{
HolderIdentity: le.config.Lock.Identity(),
LeaseDurationSeconds: int(le.config.LeaseDuration / time.Second),
RenewTime: now,
AcquireTime: now,
}
// 获取或者创建锁记录
oldLeaderElectionRecord, oldLeaderElectionRawRecord, err := le.config.Lock.Get(ctx)
if err != nil {
// 有 error 异常, 但不是 NotFound 类型的则退出
if !errors.IsNotFound(err) {
return false
}
// 这里可以判定没有锁, 所以尝试创建锁, 如果失败则直接退出
if err = le.config.Lock.Create(ctx, leaderElectionRecord); err != nil {
return false
}
// 成功创建锁, 返回 true
return true
}
// 拿到了锁对象, 判断锁的 id 和 time
if !bytes.Equal(le.observedRawRecord, oldLeaderElectionRawRecord) {
le.setObservedRecord(oldLeaderElectionRecord)
le.observedRawRecord = oldLeaderElectionRawRecord
}
// 当锁没有过期且拿锁的id不是自身, 则直接退出, 等待 5s 后再重试
if len(oldLeaderElectionRecord.HolderIdentity) > 0 &&
le.observedTime.Add(le.config.LeaseDuration).After(now.Time) &&
!le.IsLeader() {
return false
}
// 当前自身已经是 leader 了, 上一次也是leader和首次变为leader
if le.IsLeader() {
// 上次也是 leader
leaderElectionRecord.AcquireTime = oldLeaderElectionRecord.AcquireTime
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions
} else {
// 累加锁的转变次数
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions + 1
}
// 更新锁资源, 其实就是更新 ttl 时效
if err = le.config.Lock.Update(ctx, leaderElectionRecord); err != nil {
return false
}
le.setObservedRecord(&leaderElectionRecord)
return true
}
看下 leaseLock 的 get, create, update 的实现, 没什么可说的, 就是映射 LeaderElectionRecord 结构, 然后调用 restapi 对 apiserver 的 lease 资源操作.
需要注意的是 LeaderElectionRecordToLeaseSpec 方法, 会把 LeaderElectionRecord 数据结构映射到 leaseSpec 里, 这样 leaseSpec 结构有 acquireTime, renewTime, leasetDuration, holderID 字段. 后面当我们使用 kubectl get leases.coordination.k8s.io xxx 查询时就可以看到锁的信息.
代码如下: k8s.io/client-go/tools/leaderelection/resourcelock/leaselock.go
// Get returns the election record from a Lease spec
func (ll *LeaseLock) Get(ctx context.Context) (*LeaderElectionRecord, []byte, error) {
lease, err := ll.Client.Leases(ll.LeaseMeta.Namespace).Get(ctx, ll.LeaseMeta.Name, metav1.GetOptions{})
if err != nil {
return nil, nil, err
}
ll.lease = lease
record := LeaseSpecToLeaderElectionRecord(&ll.lease.Spec)
recordByte, err := json.Marshal(*record)
if err != nil {
return nil, nil, err
}
return record, recordByte, nil
}
// Create attempts to create a Lease
func (ll *LeaseLock) Create(ctx context.Context, ler LeaderElectionRecord) error {
var err error
ll.lease, err = ll.Client.Leases(ll.LeaseMeta.Namespace).Create(ctx, &coordinationv1.Lease{
ObjectMeta: metav1.ObjectMeta{
Name: ll.LeaseMeta.Name,
Namespace: ll.LeaseMeta.Namespace,
},
Spec: LeaderElectionRecordToLeaseSpec(&ler),
}, metav1.CreateOptions{})
return err
}
// Update will update an existing Lease spec.
func (ll *LeaseLock) Update(ctx context.Context, ler LeaderElectionRecord) error {
if ll.lease == nil {
return errors.New("lease not initialized, call get or create first")
}
ll.lease.Spec = LeaderElectionRecordToLeaseSpec(&ler)
lease, err := ll.Client.Leases(ll.LeaseMeta.Namespace).Update(ctx, ll.lease, metav1.UpdateOptions{})
if err != nil {
return err
}
ll.lease = lease
return nil
}
leaseLock 的 get, creaet, update 的调用实现在这里.
代码地址: k8s.io/client-go/kubernetes/typed/coordination/v1/lease.go
总结
k8s 为了保证 kube-scheduler 和 kube-manager-controller 的高可用性, 所以各个核心组件可以启动多个实例, 但由于这些组件是通过 informer 来监听并处理事件的, 本身没有互斥特性, 多个相同组件启动监听会出现混乱的问题.
为了保证这些组件的唯一性, k8s 设计了 leader election 选举特性, 只有拿到锁的实例才可以执行任务, 拿不到锁就不断尝试去拿锁. 当实例丢失 leader 后, 直接退出进程, 然后重新启动后再次抢锁.

