
源码分析 kubernetes replicaset controller 的设计实现
replicaset controller 作用
replicaset controller 是 kube-controller-manager 组件中负责 replicaset 资源对象的控制器, 内部通过 informer 监听 pod 和 replicaSet 两个资源.
replicaset controller 主要作用是根据 replicaSet 对象所期望的 pod 数量与现存 pod 数量做比较,然后根据比较结果来选择扩容创建还是缩容删除 pod, 最终使得 replicaset 对象里预期 pod 数量和当前激活的 pod 数量相等.
replicaset controller 源码分析
基于 kubernetes v1.27.0 进行源码分析.
实例化副本控制器
kube-controller-manager 会注册各种的 controller 控制器,其中包括 replicaSet 副本控制器.
startReplicaSetController 为 replicaSet controller 的启动入口,通过 NewReplicaSetController() 方法实例化控制器.
源码位置: cmd/kube-controller-manager/app/apps.go
func startReplicaSetController(ctx context.Context, controllerContext ControllerContext) (controller.Interface, bool, error) {
go replicaset.NewReplicaSetController(
controllerContext.InformerFactory.Apps().V1().ReplicaSets(),
controllerContext.InformerFactory.Core().V1().Pods(),
).Run(ctx, int(controllerContext.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs))
return nil, true, nil
}
启动副本控制器
NewBaseController 是 replicaSet controller 的具体实现, 初始化时其内部会启动监听 replicaset 和 pod 资源的 informer, 并且注册了增删改对应的回调方法.
func NewReplicaSetController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int) *ReplicaSetController {
return NewBaseController(rsInformer, podInformer, kubeClient, burstReplicas,
...
)
}
func NewBaseController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int,
gvk schema.GroupVersionKind, metricOwnerName, queueName string, podControl controller.PodControlInterface, eventBroadcaster record.EventBroadcaster) *ReplicaSetController {
rsc := &ReplicaSetController{}
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.addRS,
UpdateFunc: rsc.updateRS,
DeleteFunc: rsc.deleteRS,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.addPod,
UpdateFunc: rsc.updatePod,
DeleteFunc: rsc.deletePod,
})
rsc.syncHandler = rsc.syncReplicaSet
return rsc
}
Run() 启动 rs 控制器, 并发启动 workers 数量的协程, 通过 wait.UntilWithContext 定时拉起 worker 处理函数.
workers 这个参数很重要,影响了 rs 控制器的处理性能, 调高此数值自然可以提供 rsc 的效率, 初始化配置里 ConcurrentRSSyncs 默认为 5.
func (rsc *ReplicaSetController) Run(ctx context.Context, workers int) {
// 等待 informer 完成同步缓存
if !cache.WaitForNamedCacheSync(rsc.Kind, ctx.Done(), rsc.podListerSynced, rsc.rsListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, rsc.worker, time.Second)
}
<-ctx.Done()
}
worker 处理函数相对简单,就是从 queue 里获取 key, 然后调用 syncHandler 处理, 如果失败则调用 queue 进行重入队.
func (rsc *ReplicaSetController) worker(ctx context.Context) {
for rsc.processNextWorkItem(ctx) {
}
}
func (rsc *ReplicaSetController) processNextWorkItem(ctx context.Context) bool {
// 从队列获取数据
key, quit := rsc.queue.Get()
if quit {
return false
}
defer rsc.queue.Done(key)
// syncHandler 核心处理函数
err := rsc.syncHandler(ctx, key.(string))
if err == nil {
rsc.queue.Forget(key)
return true
}
// 如果增删 pod 有异常, 则重新推到队列中, 等待下次重试.
rsc.queue.AddRateLimited(key)
return true
}
控制器内的 informer 监听
rsc 通过 informer 机制来监听处理 rs 和 pod 资源变动.
replicaSet informer
在 replicaSet informer 上注册增删改的 eventHandler, 这些逻辑都相对简单, 直接入队列就行了, 等待后面的 worker 协程去驱动 syncReplicaSet 来处理.
- 当 add rs 时, syncReplicaSet 识别有新 rs 被创建, 则创建 rs 对应的 pods.
- 当 delete rs 时, syncReplicaSet 在 expectations 找不到, 则进行清理.
- 当 update rs 时, syncReplicaSet 会进行副本数的协调同步.
func (rsc *ReplicaSetController) addRS(obj interface{}) {
// 直接入队列
rs := obj.(*apps.ReplicaSet)
rsc.enqueueRS(rs)
}
func (rsc *ReplicaSetController) updateRS(old, cur interface{}) {
oldRS := old.(*apps.ReplicaSet)
curRS := cur.(*apps.ReplicaSet)
...
// 如果新老配置的 replicas 副本数发生变更, 则打印出来.
if *(oldRS.Spec.Replicas) != *(curRS.Spec.Replicas) {
klog.V(4).Infof("%v %v updated. Desired pod count change: %d->%d", rsc.Kind, curRS.Name, *(oldRS.Spec.Replicas), *(curRS.Spec.Replicas))
}
// 入队
rsc.enqueueRS(curRS)
}
func (rsc *ReplicaSetController) deleteRS(obj interface{}) {
rs, ok := obj.(*apps.ReplicaSet)
key, err := controller.KeyFunc(rs)
// 在 expectations 里删除.
rsc.expectations.DeleteExpectations(key)
// 入队
rsc.queue.Add(key)
}
enqueueRs 是入队列的逻辑, 从 rs 对象获取 namespace/name 格式的 key, 后扔到 rsc 队列即可.
func (rsc *ReplicaSetController) enqueueRS(rs *apps.ReplicaSet) {
key, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for object %#v: %v", rs, err))
return
}
rsc.queue.Add(key)
}
pod informer
addPod 和 deletePod 主逻辑是先操作下 expectations, 遇到 add 时加一, 遇到 del 时减一, 然后把 rs 入队列里, 当 syncReplicaSet 处理时发现当前跟预期的副本数不一致, 进行同步协调.
updatePod 的事件代码相对麻烦点, 内有各种的条件判断, 请直接看下面代码中的注释.
func (rsc *ReplicaSetController) addPod(obj interface{}) {
pod := obj.(*v1.Pod)
// 如果 pod 字段不为空,则删除.
if pod.DeletionTimestamp != nil {
rsc.deletePod(pod)
return
}
if controllerRef := metav1.GetControllerOf(pod); controllerRef != nil {
rs := rsc.resolveControllerRef(pod.Namespace, controllerRef)
rsKey, err := controller.KeyFunc(rs)
// 在 expectations 里把 add 字段加一.
rsc.expectations.CreationObserved(rsKey)
// 把 rskey 推到队列里
rsc.queue.Add(rsKey)
return
}
// 走到这里说明是孤儿 pod, 获取 pod 所属的 rs 集合
rss := rsc.getPodReplicaSets(pod)
if len(rss) == 0 {
return // 没找到对应 rs 则忽略.
}
for _, rs := range rss {
// 把 rs 扔到队列里, 让后面的同步流程去清理
rsc.enqueueRS(rs)
}
}
func (rsc *ReplicaSetController) deletePod(obj interface{}) {
pod, ok := obj.(*v1.Pod)
controllerRef := metav1.GetControllerOf(pod)
rs := rsc.resolveControllerRef(pod.Namespace, controllerRef)
// 在 expectations 里找到 rskey 对应的 exp, 在 del 字段 -1
rsKey, err := controller.KeyFunc(rs)
rsc.expectations.DeletionObserved(rsKey, controller.PodKey(pod))
// 把 rskey 插入到队列里
rsc.queue.Add(rsKey)
}
func (rsc *ReplicaSetController) updatePod(old, cur interface{}) {
curPod := cur.(*v1.Pod)
oldPod := old.(*v1.Pod)
if curPod.ResourceVersion == oldPod.ResourceVersion {
return
}
// 如果 pod label 改变或者处于删除状态,则直接删除
labelChanged := !reflect.DeepEqual(curPod.Labels, oldPod.Labels)
if curPod.DeletionTimestamp != nil {
rsc.deletePod(curPod)
if labelChanged {
rsc.deletePod(oldPod)
}
return
}
// 如果 pod 的 OwnerReference 发生改变,将 oldRS 入队
curControllerRef := metav1.GetControllerOf(curPod)
oldControllerRef := metav1.GetControllerOf(oldPod)
controllerRefChanged := !reflect.DeepEqual(curControllerRef, oldControllerRef)
if controllerRefChanged && oldControllerRef != nil {
if rs := rsc.resolveControllerRef(oldPod.Namespace, oldControllerRef); rs != nil {
rsc.enqueueRS(rs)
}
}
// 获取 pod 关联的 rs, 入队 rs
if curControllerRef != nil {
rs := rsc.resolveControllerRef(curPod.Namespace, curControllerRef)
if rs == nil {
return
}
rsc.enqueueRS(rs)
if !podutil.IsPodReady(oldPod) && podutil.IsPodReady(curPod) && rs.Spec.MinReadySeconds > 0 {
rsc.enqueueRSAfter(rs, (time.Duration(rs.Spec.MinReadySeconds)*time.Second)+time.Second)
}
return
}
// 查找匹配的 rs
if labelChanged || controllerRefChanged {
rss := rsc.getPodReplicaSets(curPod)
if len(rss) == 0 {
return
}
for _, rs := range rss {
rsc.enqueueRS(rs)
}
}
}
核心同步管理副本集
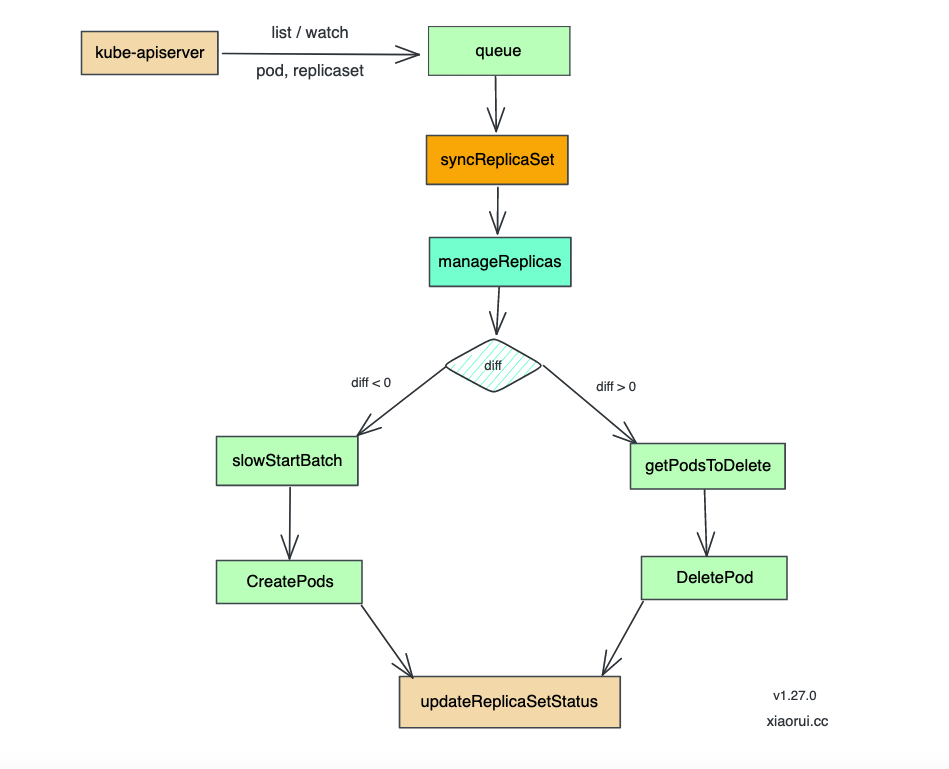
syncReplicaSet 实现了 syncHandler 方法, 下面分析下 syncReplicaSet 的源码实现.
syncReplicaSet 是 replicaset controller 里最核心的代码了, 该方法会控制驱动使 replicaSet 副本数跟预期一致, 如果当前副本数比预期少,那么就创建,反之比预期多就销毁 pod, 操作完后会计算状态并向 apiserver 上报副本集的状态.
syncHandler 主逻辑流程
1、根据 ns/name 获取 rs 对象;
2、调用 expectations.SatisfiedExpectations 判断是否需要执行真正的 sync 操作;
3、获取所有 pod list;
4、根据 pod label 进行过滤获取与该 rs 关联的 pod 列表,对于其中的孤儿 pod 若与该 rs label 匹配则进行关联,若已关联的 pod 与 rs label 不匹配则解除关联关系;
5、调用 manageReplicas 进行同步 pod 操作,add/del pod;
6、计算 rs 当前的 status 并进行更新;
func (rsc *ReplicaSetController) syncReplicaSet(ctx context.Context, key string) error {
// 从 key 获取 namespace 命令空间 和 name 集合名.
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
// 通过 namespace 和 name 从 informer cache 里获取 rs 对象.
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
// 如果 rs 已经被删除,则尝试在 expectations 清空对应的记录.
if apierrors.IsNotFound(err) {
rsc.expectations.DeleteExpectations(key)
return nil
}
if err != nil {
return err
}
// 判断下是否需要 manageReplicas 同步, 后面有详细描述.
rsNeedsSync := rsc.expectations.SatisfiedExpectations(key)
selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector)
if err != nil {
return nil
}
// 获取相关的 pods 集合.
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
if err != nil {
return err
}
// 过滤激活状态的 pods.
filteredPods := controller.FilterActivePods(allPods)
filteredPods, err = rsc.claimPods(ctx, rs, selector, filteredPods)
if err != nil {
return err
}
var manageReplicasErr error
if rsNeedsSync && rs.DeletionTimestamp == nil {
manageReplicasErr = rsc.manageReplicas(ctx, filteredPods, rs)
}
// 计算 rs 的状态.
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
// 向 apiserver 更新新的 rs 的状态.
updatedRS, err := updateReplicaSetStatus(rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
if err != nil {
return err
}
return manageReplicasErr
}
syncReplicaSet 源码中涉及到的操作比较多, 这里对重点方法进行下源码.
- 判断是否需要同步 ? rsc.expectations.SatisfiedExpectations
- 同步管理副本集, rsc.manageReplicas
- 计算副本集状态, calculateStatus
判断是否需要同步 SatisfiedExpectations
该方法主要判断 rs 是否需要执行真正的同步操作, 当从没执行 rs 或距离上次操作超过 5 分钟或已满足预期时, 则返回 true, 也就是会执行 manageReplicas 进行副本数同步.
有个问题, 当 Fulfilled 返回 true, 也就是当前集群副本数跟预期状态一致时, 为什么还返回 true ?
func (r *ControllerExpectations) SatisfiedExpectations(controllerKey string) bool {
// 如果有 exp 对象, 那么判断是否满足条件或者超过同步周期, 则返回 true
if exp, exists, err := r.GetExpectations(controllerKey); exists {
if exp.Fulfilled() {
return true
} else if exp.isExpired() {
return true
} else {
// 其他情况则返回 false
return false
}
} else if err != nil {
// 预期检查失败
} else {
// 如果没有 exp 对象,也就是说从没创建过 rs, 则返回 true
}
return true
}
// 距离上次时间超过阈值为 5 分钟为超时
func (exp *ControlleeExpectations) isExpired() bool {
return clock.RealClock{}.Since(exp.timestamp) > ExpectationsTimeout
}
// 当 add 和 del 都 <= 0 时, 当前集群已经达到了预期状态.
func (e *ControlleeExpectations) Fulfilled() bool {
// TODO: think about why this line being atomic doesn't matter
return atomic.LoadInt64(&e.add) <= 0 && atomic.LoadInt64(&e.del) <= 0
}
expectations 里的 add 和 del 的数值是怎么来的 ? 后面会具体分析下 expectations.
同步副本操作 manageReplicas
计算当前副本数跟预期副本数差值,如果比预期少,那么创建副本, 使用 slowStartBatch 来并发分批的创建. 但如果当前的副本数比预期还多, 那么就需要销毁多余的副本.
不管是创建还是删除单次最多可以操作 500 个, 当然这个配置可以在初始化 kube-controller-manager 时指定. 创建前需要在 expectations 的 add 里做个记录, 创建操作完毕后,从 add 里递减数值. 销毁前同样需要类似的操作,先标记 del 字段,再发起删除操作,完成后减去 del 数值.
func (rsc *ReplicaSetController) manageReplicas(ctx context.Context, filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
// 当前的副本数 - 配置里预期的副本数
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey, err := controller.KeyFunc(rs)
if err != nil {
return nil
}
// 如果 < 0, 说明还有副本需要创建
if diff < 0 {
diff *= -1 // 负数转成正数
if diff > rsc.burstReplicas { // 最大不能超过 500, 单次创建不能超过 500.
diff = rsc.burstReplicas
}
// 创建一个 expections 对象, 其 add 值为 diff
rsc.expectations.ExpectCreations(rsKey, diff)
// 调用 slowStartBatch 来并发分批的创建 pods, 返回成功实例化 pods 的数量
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
err := rsc.podControl.CreatePods(ctx, rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
if err != nil {
...
}
return err
})
// diff - 成功的数量等于 skippedPods
if skippedPods := diff - successfulCreations; skippedPods > 0 {
for i := 0; i < skippedPods; i++ {
// 给 exp 结构的 add 字段 atomic add 加一
rsc.expectations.CreationObserved(rsKey)
}
}
return err
// 如果 > 0 ,说明当前副本数超过了预期, 需要删除多出来的副本.
} else if diff > 0 {
if diff > rsc.burstReplicas { // 一次对多可以处理 500
diff = rsc.burstReplicas
}
relatedPods, err := rsc.getIndirectlyRelatedPods(rs)
// 获取可以被清理的 pods
podsToDelete := getPodsToDelete(filteredPods, relatedPods, diff)
// 在发起删除操作之前, 先在 expectations 记录 del 字段
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
// 并发去删除 pod, 如果删除成功,则在 expectations 里 del 字段减一.
var wg sync.WaitGroup
wg.Add(diff)
// 删除就没有创建来的优雅,直接遍历开协程去删除.
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
if err := rsc.podControl.DeletePod(ctx, rs.Namespace, targetPod.Name, rs); err != nil {
podKey := controller.PodKey(targetPod)
rsc.expectations.DeletionObserved(rsKey, podKey)
...
}
}(pod)
}
wg.Wait()
}
return nil
}
创建 pods 的操作 ?
slowStartBatch 方法用来并发的分批创建 pods, 每次创建的 pods 数是呈指数级增长, initialBatchSize 默认为 1, 后面会按照 2, 4, 8, 16, 32, 64 ... 来指数级增长.
func slowStartBatch(count int, initialBatchSize int, fn func() error) (int, error) {
remaining := count
successes := 0
for batchSize := integer.IntMin(remaining, initialBatchSize); batchSize > 0; batchSize = integer.IntMin(2*batchSize, remaining) {
errCh := make(chan error, batchSize)
var wg sync.WaitGroup
wg.Add(batchSize)
for i := 0; i < batchSize; i++ {
go func() {
defer wg.Done()
if err := fn(); err != nil {
errCh <- err
}
}()
}
wg.Wait()
curSuccesses := batchSize - len(errCh)
successes += curSuccesses
if len(errCh) > 0 {
return successes, <-errCh
}
remaining -= batchSize
}
return successes, nil
}
再来看下 slowStartBatch 具体创建 pod 的方法.
pkg/controller/controller_utils.go
func (r RealPodControl) CreatePodsWithGenerateName(ctx context.Context, namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference, generateName string) error {
// 通过模板创建 pod 对应
pod, err := GetPodFromTemplate(template, controllerObject, controllerRef)
if err != nil {
return err
}
return r.createPods(ctx, namespace, pod, controllerObject)
}
func (r RealPodControl) createPods(ctx context.Context, namespace string, pod *v1.Pod, object runtime.Object) error {
// 通过调用 clientset 的 create 创建 pod.
newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(ctx, pod, metav1.CreateOptions{})
if err != nil {
...
return err
}
...
return nil
}
删除 pods 操作 ?
通过 getPodsToDelete 方法筛选出需要删除的 pods, 然后并发删除这些 pod.
如何选出要删除的 pods ?
pkg/controller/controller_utils.go
通过下面的策略对 pod 筛选排序操作, 按照质量优先级进行排列, 低优先级的 pod 位于前面:
type ActivePodsWithRanks struct {
Pods []*v1.Pod
Rank []int
}
// 实现 less 排序比较接口,调用方可以使用 sort.Sork 进行排序.
func (s ActivePodsWithRanks) Less(i, j int) bool {
// 1. Unassigned < assigned
// If only one of the pods is unassigned, the unassigned one is smaller
if s.Pods[i].Spec.NodeName != s.Pods[j].Spec.NodeName && (len(s.Pods[i].Spec.NodeName) == 0 || len(s.Pods[j].Spec.NodeName) == 0) {
return len(s.Pods[i].Spec.NodeName) == 0
}
// 2. PodPending < PodUnknown < PodRunning
if podPhaseToOrdinal[s.Pods[i].Status.Phase] != podPhaseToOrdinal[s.Pods[j].Status.Phase] {
return podPhaseToOrdinal[s.Pods[i].Status.Phase] < podPhaseToOrdinal[s.Pods[j].Status.Phase]
}
// 3. Not ready < ready
// If only one of the pods is not ready, the not ready one is smaller
if podutil.IsPodReady(s.Pods[i]) != podutil.IsPodReady(s.Pods[j]) {
return !podutil.IsPodReady(s.Pods[i])
}
// 4. lower pod-deletion-cost < higher pod-deletion cost
if utilfeature.DefaultFeatureGate.Enabled(features.PodDeletionCost) {
}
// 5. Doubled up < not doubled up
// If one of the two pods is on the same node as one or more additional
// ready pods that belong to the same replicaset, whichever pod has more
// colocated ready pods is less
if s.Rank[i] != s.Rank[j] {
return s.Rank[i] > s.Rank[j]
}
// 6. Been ready for empty time < less time < more time
// If both pods are ready, the latest ready one is smaller
if podutil.IsPodReady(s.Pods[i]) && podutil.IsPodReady(s.Pods[j]) {
}
// 7. Pods with containers with higher restart counts < lower restart counts
if maxContainerRestarts(s.Pods[i]) != maxContainerRestarts(s.Pods[j]) {
return maxContainerRestarts(s.Pods[i]) > maxContainerRestarts(s.Pods[j])
}
// 8. Empty creation time pods < newer pods < older pods
if !s.Pods[i].CreationTimestamp.Equal(&s.Pods[j].CreationTimestamp) {
}
return false
}
返回前面 diff 数量的 pods.
func getPodsToDelete(filteredPods, relatedPods []*v1.Pod, diff int) []*v1.Pod {
if diff < len(filteredPods) {
// 对同一个节点下 pods 进行 rank 计分
podsWithRanks := getPodsRankedByRelatedPodsOnSameNode(filteredPods, relatedPods)
// 对已实现了排序接口的对象进行排序
sort.Sort(podsWithRanks)
}
return filteredPods[:diff]
}
具体怎么删除 pod
只是单纯的使用 clientset 的 pod delete 来删除, 没什么可说的.
func (r RealPodControl) DeletePod(ctx context.Context, namespace string, podID string, object runtime.Object) error {
if err := r.KubeClient.CoreV1().Pods(namespace).Delete(ctx, podID, metav1.DeleteOptions{}); err != nil {
return fmt.Errorf("unable to delete pods: %v", err)
}
...
return nil
}
exceptions 预期集合
什么作用 ?
expectations 会记录 rs 所有对象需要 add/del 的 pod 数量.
若两者都为 0 则说明该 rs 所期望创建的 pod 或者删除的 pod 数已经被满足,若不满足则说明某次在 syncLoop 中创建或者删除 pod 时有失败的操作,则需要等待 expectations 过期后再次同步该 rs.
expectations 需要满足哪些条件 ?
- 当 expectations 中不存在 rsKey 时, 也就说首次创建 rs 时;
- 当 expectations 中 del 以及 add 值都为 0 时, rs 所需要创建或者删除的 pod 数都已满足;
- 当 expectations 过期时, 即超过 5 分钟未进行 sync 操作;
rsc 里有哪些逻辑会设计到 expectations
- 与 rs informer 相关的 AddRS、UpdateRS、DeleteRS
- 与 pod informer 相关的 AddPod、UpdatePod、DeletePod
- syncReplicaSet 里对 expectations 判断及增删覆盖.
syncReplicaSet 中调用过的 exceptions 方法
// 字段 add 期望值需要减少一个 pod
CreationObserved(controllerKey string)
// 字段 del 期望值需要减少一个 pod
DeletionObserved(controllerKey string)
// 写入 key 需要 add 的 pod 数量
ExpectCreations(controllerKey string, adds int) error
// 写入 key 需要 del 的 pod 数量
ExpectDeletions(controllerKey string, dels int) error
// 删除该 key
DeleteExpectations(controllerKey string)

