
摘要
元旦期间 订单业务线 告知 推送系统 无法正常收发消息,作为推送系统维护者的我正外面潇洒,无法第一时间回去,直接让 ops 帮忙重启服务,一切好了起来,重启果然是个大杀器。由于推送系统本身是分布式部署,消息有做各种的可靠性策略,所以重启是不会丢失消息事件的。
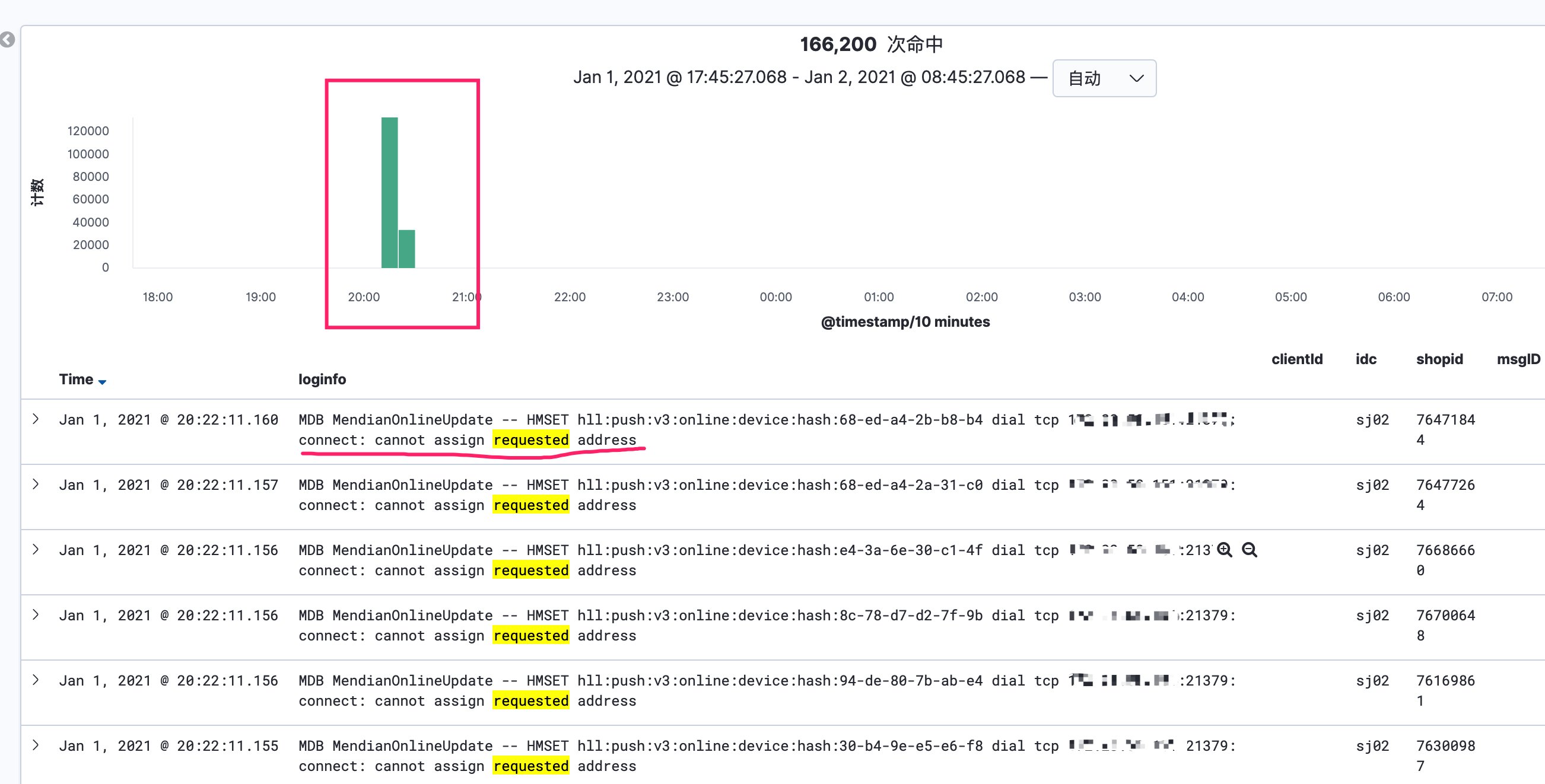
😅 事后通过日志分析有大量的 redis 的报错,十分钟内有 16w 次的错误。日志的错误是 connect: cannot assign requested address 。该错误不是推送服务内部及 redis 库返回的 error,而是系统回馈的 errno 错误。
这个错误是由于无法申请可用地址引起的,也就是无法申请到可用的 socket。
话说,元旦当天在线数和订单量确实大了不少,往常推送系统的长连接客户端在 35w,这次峰值飙到 50w 左右, 集群共 6 个节点,其中有 4 个节点每个都抗了 9w+ 的长连接。另外,推送的消息量也随之翻倍。

分析
下面是 kibana 日志的统计,出错的时间区间里有近 16w 次的 redis 报错。
下面是出问题节点的 TCP 连接状况,可以看到 established 在 6w,而time-wait 连接干到 2w 多个。
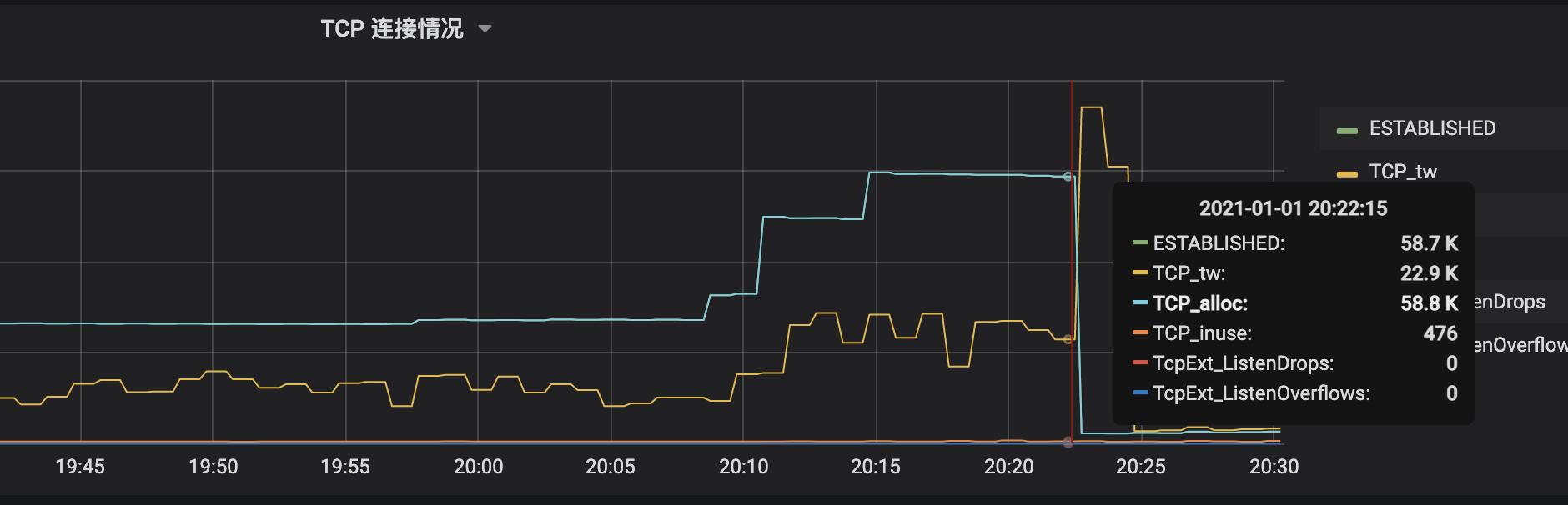
为什么会产生这么多 time-wait?谁主动关闭就就有 time-wait,但推送系统除了协议解析失败之外,其余情况都不会主动 close 客户端,哪怕是鉴权失败和弱网络客户端写缓冲爆满,事后通过日志也确定了不是推送系统自身产生的 tw。
另外,linux 主机被 ops 交付时应该有做内核调优初始化的,在开启 tw_reuse 参数后,time-wait 是可以复用的。难道是没开启 reuse?
查看 sysctl.conf 的内核参数得知,果然 tcp_tw_reuse 参数没有打开,不能快速地复用还处在 time-wait 状态的地址,只能等待 time-wait 的超时关闭,rfc 协议里规定等待 2 分钟左右,开启 tw_reuse可在 1s 后复用该地址。另外 ip_local_port_range 端口范围也不大,缩短了可用的连接范围。
sysctl -a|egrep "tw_reuse|timestamp|local_port"
net.ipv4.ip_local_port_range = 35768 60999
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 0
所以,由于没有可用地址才爆出了 connect: cannot assign requested address 错误。
内在问题
追究问题
上面是表象问题,来查查为什么会有这么多的 time-wait ?再说一遍,通常哪一端主动 close fd,哪一端就会产生 time-wait。事后通过 netstat 得知 time-wait 连接基本是来自 redis 主机。
下面是推送代码中的连接池配置,空闲连接池只有 50,最大可以 new 的连接可以到 500 个。这代表当有大量请求时,企图先从 size 为 50 的连接池里获取连接,如果拿不到连接则 new 一个新连接,连接用完了后需要归还连接池,如果这时候连接池已经满了,那么该连接会主动进行 close 关闭。
MaxIdle = 50
MaxActive = 500
Wait = false
除此之外,还发现一个问题。有几处 redis 的处理逻辑是异步的,比如每次收到心跳包都会 go 一个协程去更新 redis, 这也加剧了连接池的抢夺,改为同步代码。这样在一个连接上下文中同时只对一个 redis 连接操作。
解决方法
调大 golang redis client 的 maxIdle 连接池大小,避免了大并发下无空闲连接而新建连接和池子爆满又不能归还连接的尴尬场面。当 pool wait 为 true 时,意味着如果空闲池中没有可用的连接,且当前已建立连接的连接数大于 MaxActive 最大空闲数,则一直阻塞等待其他人归还连接。反之直接返回 “connection pool exhausted” 错误。
MaxIdle = 300
MaxActive = 400
Wait = true
redis 的 qps 性能瓶颈
redis 的性能一直是大家所称赞的,在不使用 redis 6.0 multi io thread 下,QPS 一般可以在 13w 左右,如果使用多指令和 pipeline 的话,可以干到 40w 的 OPS 命令数,当然 qps 还是在 12w-13w 左右。
Redis QPS 高低跟 redis 版本和 cpu hz、cache 存在正比关系
根据我的经验,在内网环境下且已实例化连接对象,单条 redis 指令请求耗时通常在 0.2ms 左右,200us 已经够快了,但为什么还会有大量因 redis client 连接池无空闲连接而建立新连接的情况?
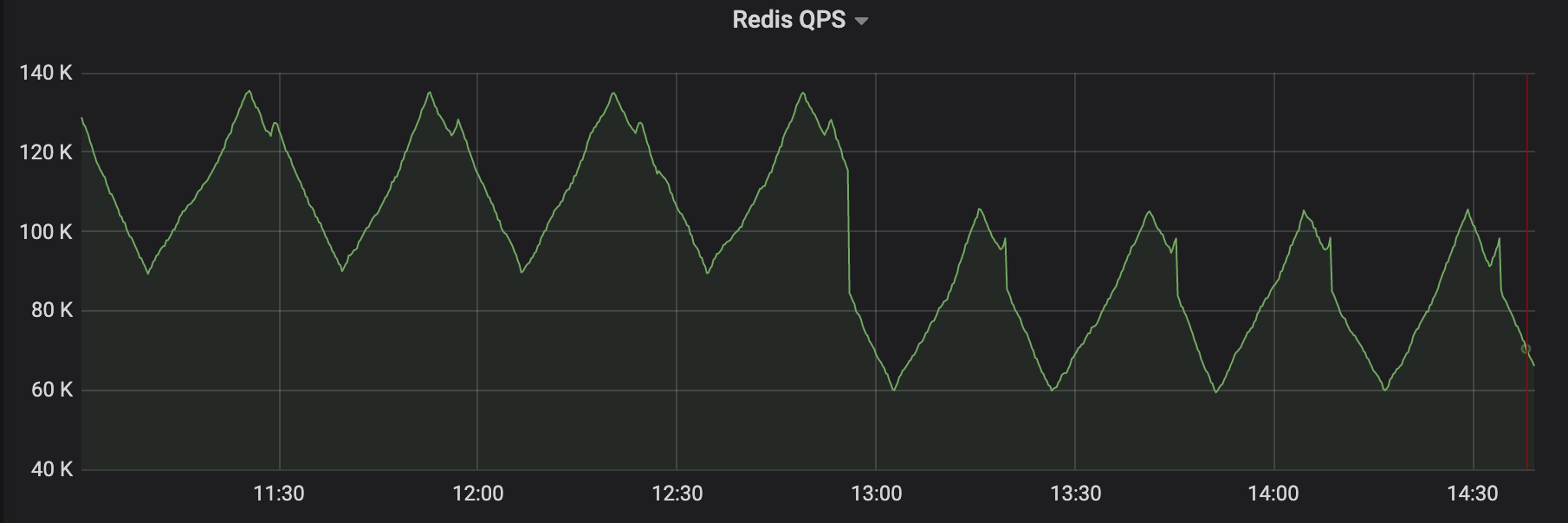
通过 grafana 监控分析 redis 集群,发现有几个节点 QPS 已经到了 Redis 单实例性能瓶颈,QPS 干到了近 15w 左右。难怪不能快速处理来自业务的 redis 请求。这个瓶颈必然会影响请求的时延。请求的时延都高了,连接池不能及时返回连接池,所以就造成了文章开头说的问题。总之,业务流量的暴增引起了一系列问题。

发现问题,那么就要解决问题,redis 的 qps 优化方案有两步:
- 扩容 redis 节点,迁移 slot 使其分担流量
- 尽量把程序中 redis 的请求改成批量模式
增加节点容易,批量也容易。起初在优化推送系统时,已经把同一个逻辑中的 redis 操作改为批量模式了。但问题来了,很多的 redis 操作在不同的逻辑块里面,没法合成一个 pipeline。
然后做了进一步的优化,把不同逻辑中的 redis 请求合并到一个 pipeline 里,优点在于提高了 redis 的吞吐,减少了 socket 系统调用、网络中断开销,缺点是增加了逻辑复杂度,使用 channal 管道做队列及通知增加了 runtime 调度开销,pipeline worker 触发条件是满足 3 个 command 或 5ms 超时,定时器采用分段的时间轮。
对比优化修改前,cpu开销减少了 3% 左右,压测下redis qps平均降了 3w 左右差值,最多可以降到 7w 左右,当然概率上消息的时延会高了几个ms。
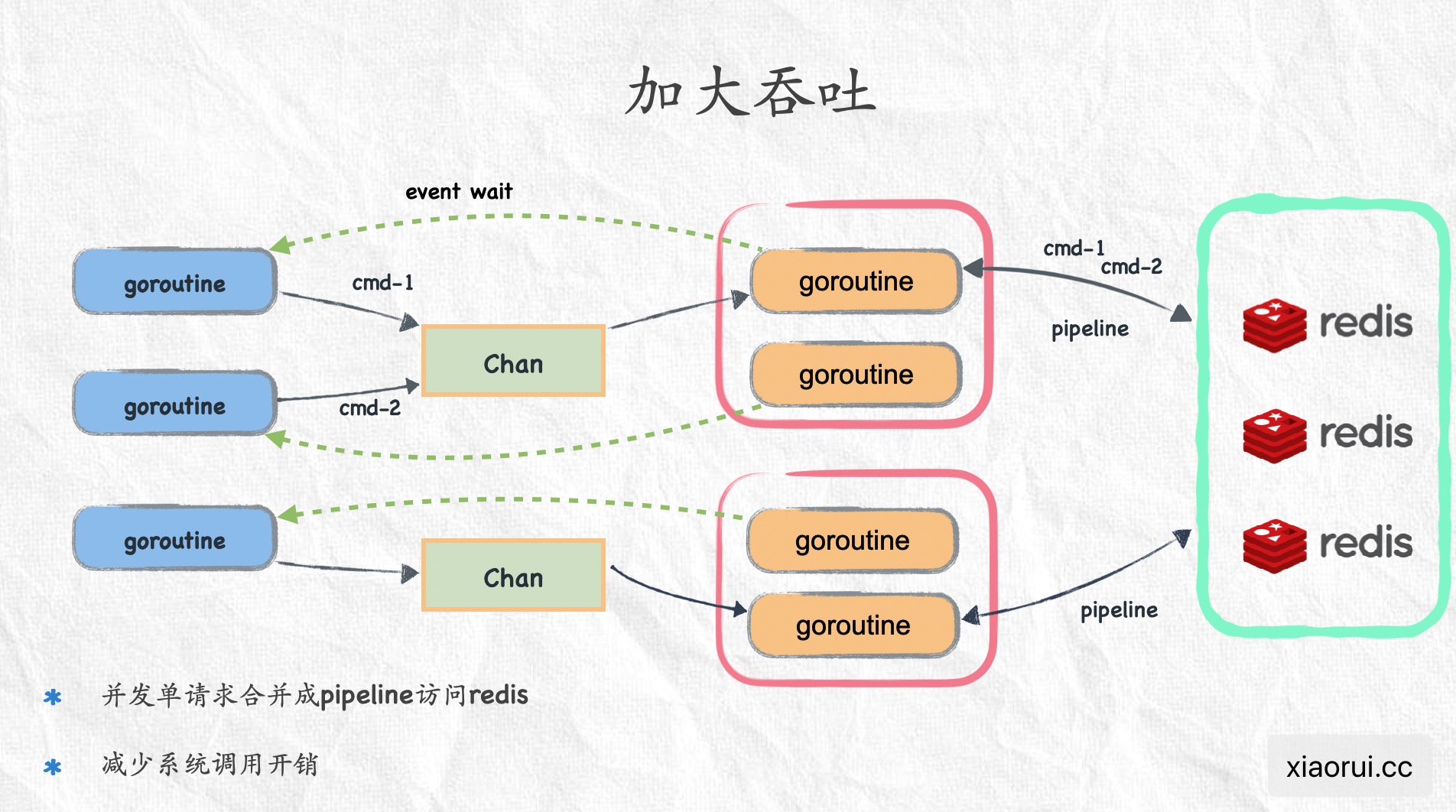
实现的逻辑参考下图,调用方把redis command和接收结果的chan推送到任务队列中,然后由一个worker去消费,worker组装多个redis cmd为pipeline,向redis发起请求并拿回结果,拆解结果集后,给每个命令对应的结果chan推送结果。调用方在推送任务到队列后,就一直监听传输结果的chan。
这个方案来自我在上家公司做推送系统的经验,有兴趣的朋友可以看看 PPT,内涵不少高并发经验。分布式推送系统设计与实现
总结
推送系统设计之初是预计 15w 的长连接数,稳定后再无优化调整,也一直稳定跑在线上。后面随着业务的暴涨,长连接数也一直跟着暴涨,现在日常稳定在 35w,出问题时暴到 50w,我们没有因为业务暴增进行整条链路压测及优化。
话说,如果对推送系统平时多上点心也不至于出这个问题。我曾经开发过相对高规格的推送系统,而现在公司的推送系统我是后接手的,由于它的架子一般,但业务性又太强,看着脑仁疼,所以就没有推倒来重构。一直是在这个架子上添添补补,做了一些常规的性能优化。嗯,看来不能掉以轻心,免得绩效离我远去。

