
第一次接触futures这个库是在tornado中,4.0的tornado会经常的使用他,因为tornado本身的那个corouting的异步功能,是需要逻辑里面所调用的模块本身就支持异步才可以的。而且如果用futures之后,在一定程度上缓解了这个事情。
concurrent.futures 是python3新增加的一个库,用于并发处理,类似于其他语言里的线程池(也有一个进程池),他属于上层的封装,对于用户来说,不用在考虑那么多东西了。
逼不得已,注释下我的博客地址 blog.xiaorui.cc
这里主要有:
Executor:还有它的两个子类ThreadPoolExecutor和ProcessPoolExecutor
Future:有Executor.submit产生多任务
那先看下THreadPoolExecutor
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
print(list(executor.map(sleeper, x)))
接着看下ProcessPoolExecutor,会发现他的用法相当的简练,不再像以前threading、multiprocessing那样繁琐。
from concurrent.futures import ProcessPoolExecutor
def pool_factorizer_go(nums, nprocs):
nprocs=xxx
with ProcessPoolExecutor(max_workers=nprocs) as executor:
return {num:factors for num, factors in
zip(nums,
executor.map(factorize_naive, nums))}
Executor is an abstract class that provides methods to execute calls asynchronously. It should not be used directly, but through its two subclasses: ThreadPoolExecutor and ProcessPoolExecutor.
官方的介绍直白,用submit注册你的函数,以及要传递的相关的参数。
Executor.submit(fn, *args, **kwargs)
Schedules the callable to be executed as fn*(*args*, **kwargs) and returns a Future representing the execution of the callable.
with ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(pow, 323, 1235)
print(future.result())
那下面这个shutdown就有些kill了。你可以自己判断,或者是直接干掉他。
Executor.shutdown(wait=True)
注意一点:
看到官方提供的一个例子,是一个死锁的例子,大家在用future进行开发时,要避免一定的程度的互相引用。话说,这个有些像gevent的event result,在一个函数中等待另一个结果的完毕。
import time
def wait_on_b():
time.sleep(5)
print(b.result()) #b不会完成,他一直在等待a的return结果
return 5
def wait_on_a():
time.sleep(5)
print(a.result()) #同理a也不会完成,他也是在等待b的结果
return 6
executor = ThreadPoolExecutor(max_workers=2)
a = executor.submit(wait_on_b)
b = executor.submit(wait_on_a)
如果上面的任务,一定要同时进行的话,可以开出两个任务,中间用全局变量或者xxx。
下面的任务也照样会造成死锁的状态,最好不要在已经被submit的函数里面在调用submit。因为这好比你在threading里面再threading一定,是无效的。
def wait_on_future():
f = executor.submit(pow, 5, 2)
print(f.result())
executor = ThreadPoolExecutor(max_workers=1)
executor.submit(wait_on_future)
好了,上面总是说使用python future遇到的坑,官网的例子使用模块是python3的,我已改成python2支持的。
#coding:utf-8
from concurrent import futures
import urllib2
URLS = ['http://www.xiaorui.cc/',
'http://blog.xiaorui.cc/',
'http://ops.xiaorui.cc/',
'http://www.sohu.com/']
def load_url(url, timeout):
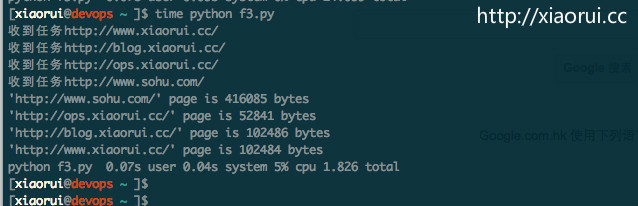
print '收到任务{0}'.format(url)
return urllib2.urlopen(url, timeout=timeout).read()
with futures.ThreadPoolExecutor(max_workers=5) as executor:
future_to_url = dict((executor.submit(load_url, url, 60), url)
for url in URLS)
for future in futures.as_completed(future_to_url):
url = future_to_url[future]
if future.exception() is not None:
print('%r generated an exception: %s' % (url,
future.exception()))
else:
print('%r page is %d bytes' % (url, len(future.result())))
除此之外,也来看看futures的其他的对象。
Future Objects The Future class encapulates the asynchronous execution of a callable. Future instances are created by Executor.submit(). 用cancel(),可以终止某个线程和进程的任务,返回状态为 True False Future.cancel() Attempt to cancel the call. If the call is currently being executed then it cannot be cancelled and the method will return False, otherwise the call will be cancelled and the method will return True. 判断是否真的结束了任务。 Future.cancelled() Return True if the call was successfully cancelled. 判断是否还在运行 Future.running() Return True if the call is currently being executed and cannot be cancelled. 判断是正常执行完毕的。 Future.done() Return True if the call was successfully cancelled or finished running. 针对result结果做超时的控制。 Future.result(timeout=None) Return the value returned by the call. If the call hasn’t yet completed then this method will wait up to timeout seconds. If the call hasn’t completed in timeout seconds then a TimeoutError will be raised. timeout can be an int or float.If timeout is not specified or None then there is no limit to the wait time.
很明显这个是增加函数的回调方法,那add_done_calback和咱们平时传入func做回调有啥区别,add_done_callback不仅可以后续的增加,而且就算你把Executor的任务给cancel取消,还是会帮你做些回调的处理,感觉一定是用装饰器搞的,有时间分析下他的源码。
Future.add_done_callback(fn)
那到现在为止,关于python的current.futures这个异步库,已经介绍完了,具体详细的大家还是看源码吧。 我相信这个也是坑逼无数的东西。


看博主的文章学到了很多,谢谢