
前言:
去年花费不少时间在扩展优化撮合交易系统,对交易系统的分布式及高性能有些心得,借着新冠状疫情带来的空闲时间,写此文章分享下交易架构的经验。
这里谈及的分布式交易系统属于股票和数字货币类的架构,跟在线电商是有所差异的,因电商无撮合引擎的概念。考虑到交易系统的业务复杂性,该文着重讲撮合系统的架构实现。后期会专门写文章来描述交易系统的业务上的设计和实现。

该文章后续仍在不断的更新修改中, 请移步到原文地址 http://xiaorui.cc/?p=6429
架构图:
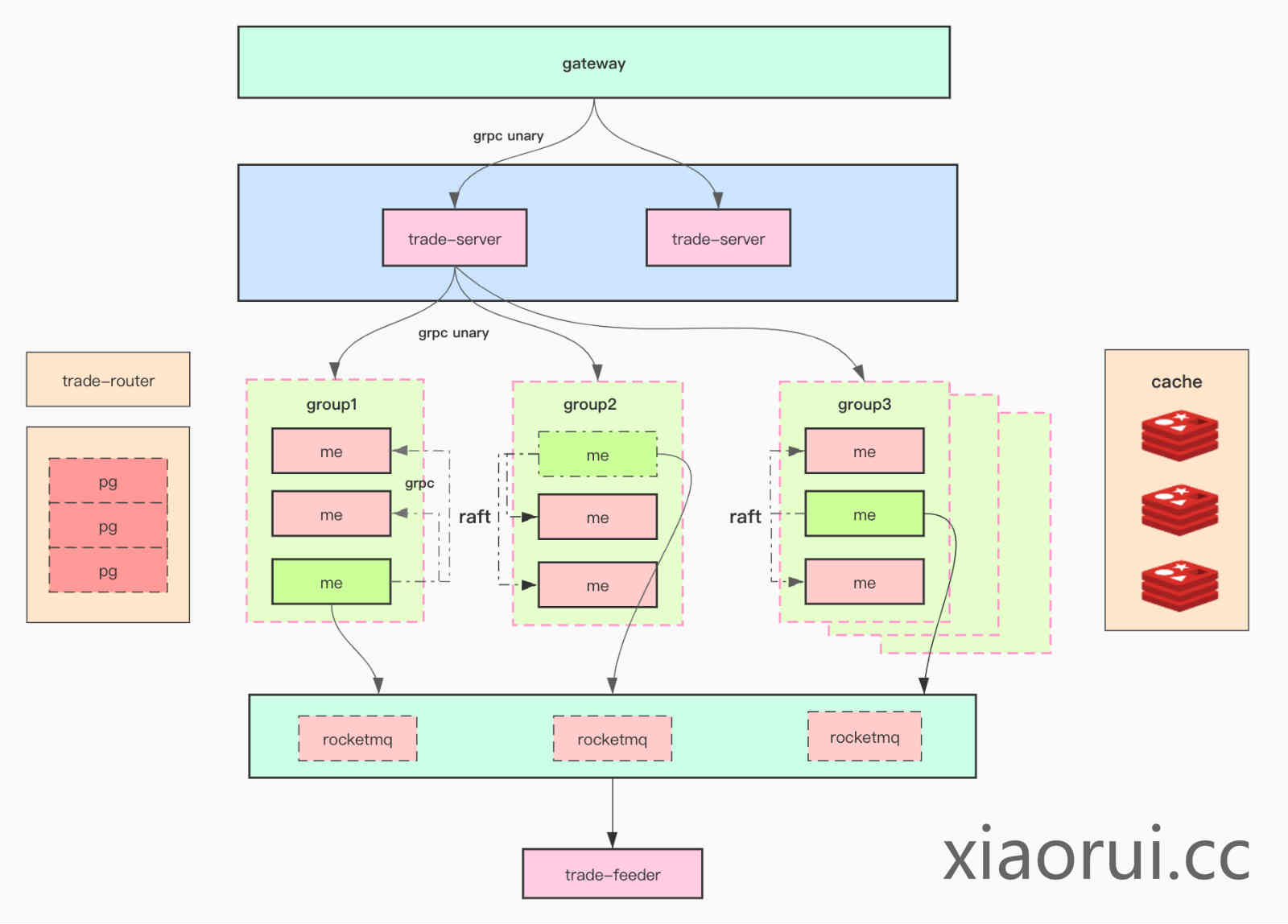
使用golang为交易系统的开发语言,go的优点大家都清楚,简单高并发。系统内部的通信则使用基于http2的grpc。
不建议大家使用go net/http作为高性能系统内部的通信协议,有几个影响性能的点,第一点数据协议的序列化消耗,第二点net/http连接池的锁竞争问题。go net/http作为client的最大qps输出也就4w左右,多开net/http连接池提升也是有限。大家可使用pprof和trace来分析下。而使用grpc配合连接池可压力输出30w+的qps。

介绍下该架构的各个组件:
gateway 入口网关
用来接收用户的请求,协议上可以是restful api和grpc。该gateway不单单是承担交易系统的网关,基本上除了行情推送业务都要走gateway网关。我们的部署方案是kubernetes,所以该gateway还承担了类似ingress的功能职责。
trade-router 交易路由
交易路由功能是对于trade-server及me-cluster的服务发现和状态回馈。
trade-server 交易系统
主要是管理委托和订单的逻辑,比如验证委托,冻结资产,创建订单等等。
me-cluster 撮合系统
把整个交易系统所支持的交易对切分多个分组,每组me集群承担一定数量的交易对。每组me集群通过raft来选举及维持数据的一致性。关于raft库这里使用了跟consul一样的hashicorp raft库,且把内置的msgpack rpc改为grpc协议。
rocketmq 消息集群
一方面用作事务消息,另一方面做行情的数据发布。通过事务消息的确认可以保证多个操作的一致性。作为发布订阅功能来说,在多topic和partition下rocketmq比kafka有更高的性能,主要体现在disk io消耗情况。
kafka每个分区都为一个文件,使用o_append模式来顺序io追加日志。但当请求密集时,顺序io转变为随机io。而rocketmq的消息数据都存在一个commitlog的集合里,consumerQueue只是存消息的offset。根绝操作系统page cache及脏数据flush的特性,尽量多的程度来保证磁盘做顺序io。
其他组件
数据库方面使用了postgres。缓存是大家熟悉的redis cluster。
撮合引擎系统的设计 ?
大家看了上面的架构图后应该会对撮合引擎me感兴趣,整个交易系统的核心其实是撮合系统引擎的设计。撮合系统是在股票和数字货币交易系统中必有的概念。
撮合系统的目的在于对用户的委托实现撮合匹配交易。比如已经有a b c三个卖家,他们以太坊ETH的价格分别是300, 200, 500。用户d发起了以太坊ETH买委托,价格为250。那么这个用户d的买委托会跟卖价格200的用户b撮合成交。
那么设计撮合系统你要考虑数据怎么存? 怎么用?
先需要把委托存在mysql里,然后建立价格及时间的索引,为了性能要分别建立买和卖的委托表。下面是撮合的伪操作过程。实现是没有问题,但是性能很差,匹配查找的合适委托过程过慢,毕竟要走磁盘。当同一交易对委托请求过多时会出现阻塞排队问题。下面的过程中来回这么多次的网络io,大概率造成一些延迟。
其他都好说,撮合系统时最大的性能瓶颈就是在如何高效匹配委托 !!!
// xiaorui.cc begin; select * from entrust where symbol = btc and market eth and side = sell and price < xxx order by create_time asc; 在程序里进一步判断是否符合 delete from entrust where status = init and id in (xx, xx); insert into order .... commit;
那么Redis是否可以? 使用redis sorted set是可以对委托单进行排序,可以通过价格+时间的格式对其方式存储,这样就满足了价格及时间优先的排序标准。
但有几个问题? 首先,如何实现可靠的持久化?redis的aof写入是异步的,不是主线程写入,由另一个异步功能线程来日志写入,有crash后丢失的概率。另外,redis的主从架构同步数据方式为异步,mysql最少还有个半同步及加强版半同步 😅。
上面说的是redis怎么存,那么怎么来保证撮合的一致性? 不要实现,倒是可以用分布式锁来关联委托主键id。但后面带来的问题也不少。
高性能撮合引擎设计
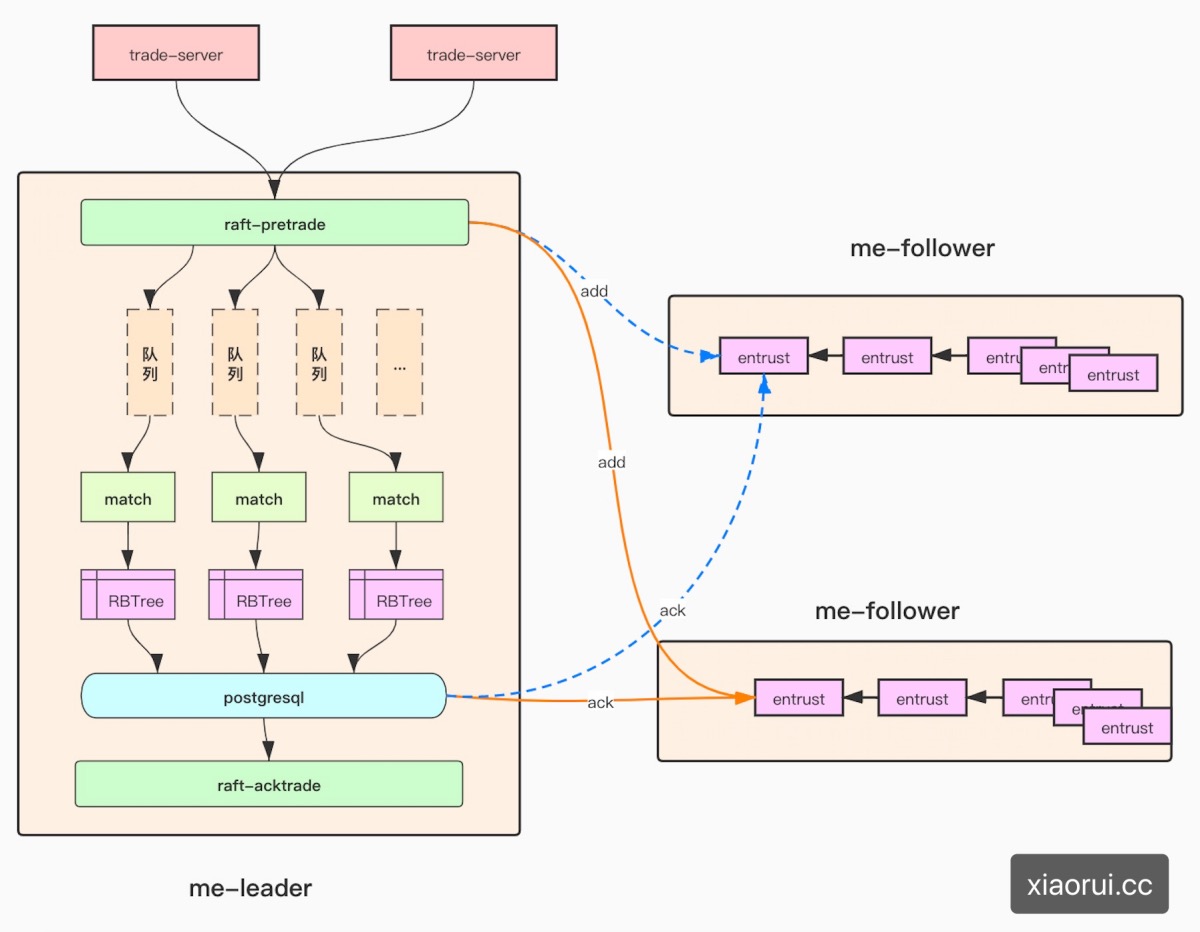
上面说了mysql及redis的方案可能存在的问题,那么业界多是怎么搞的? 基本是内存撮合!在程序内存里用红黑树来存放委托单,这样规避了网络和磁盘io的消耗。既然用内存红黑树结构存放委托,那么必然要考虑内存的特性。
如果程序crash怎么办?
撮合引擎需要设计recovery机制,可以从postgres数据库中把把未操作的委托放到撮合引擎系统里。委托数据存两份,一份是内存中,一份是数据库里。
为了规避撮合引擎由于频繁上线及crash后的recovery恢复耗时,所以我们又设计了raft节点一致性。这样当某个节点crash后,follower会提升为主并迅速接管撮合交易。在这里使用数据库postgres作为recovery的兜底方案,当撮合引擎所有节点都进行重新实例化时,那么就会走该兜底方案。
既然有了数据库作为兜底,那么raft节点产生的日志和快照都使用内存来存取。
为何根据交易对进行撮合集群分组?
golang社区里比较靠谱的raft库就两个,一个是etcd的,一个是consul的。但他们的raft库实现是单一分组实现,不支持multi raft分组。所以把撮合引擎直接在架构上拆分了多组,每个分组由3个raft节点构成。在trade-router来分配交易对及分组的关系。
后来在github中找到了golang支持multi raft的库,经过一番测试,性能还不如分组部署。
这里说下压测并发下的交易数据,每秒交易qps可以到8w,最后的瓶颈在数据库的磁盘压力。😅
trade-server是否每次转发都需访问trade-route?
不需要!因trade-server自己也会有一层映射缓存。当me-group产生扩容时,必然要迁移分片中的交易对过去,如何保证迁移时的安全及一致性? 简单说就是阻塞交易对,然后迁移,等迁移成功后,做删除并解除阻塞状态。
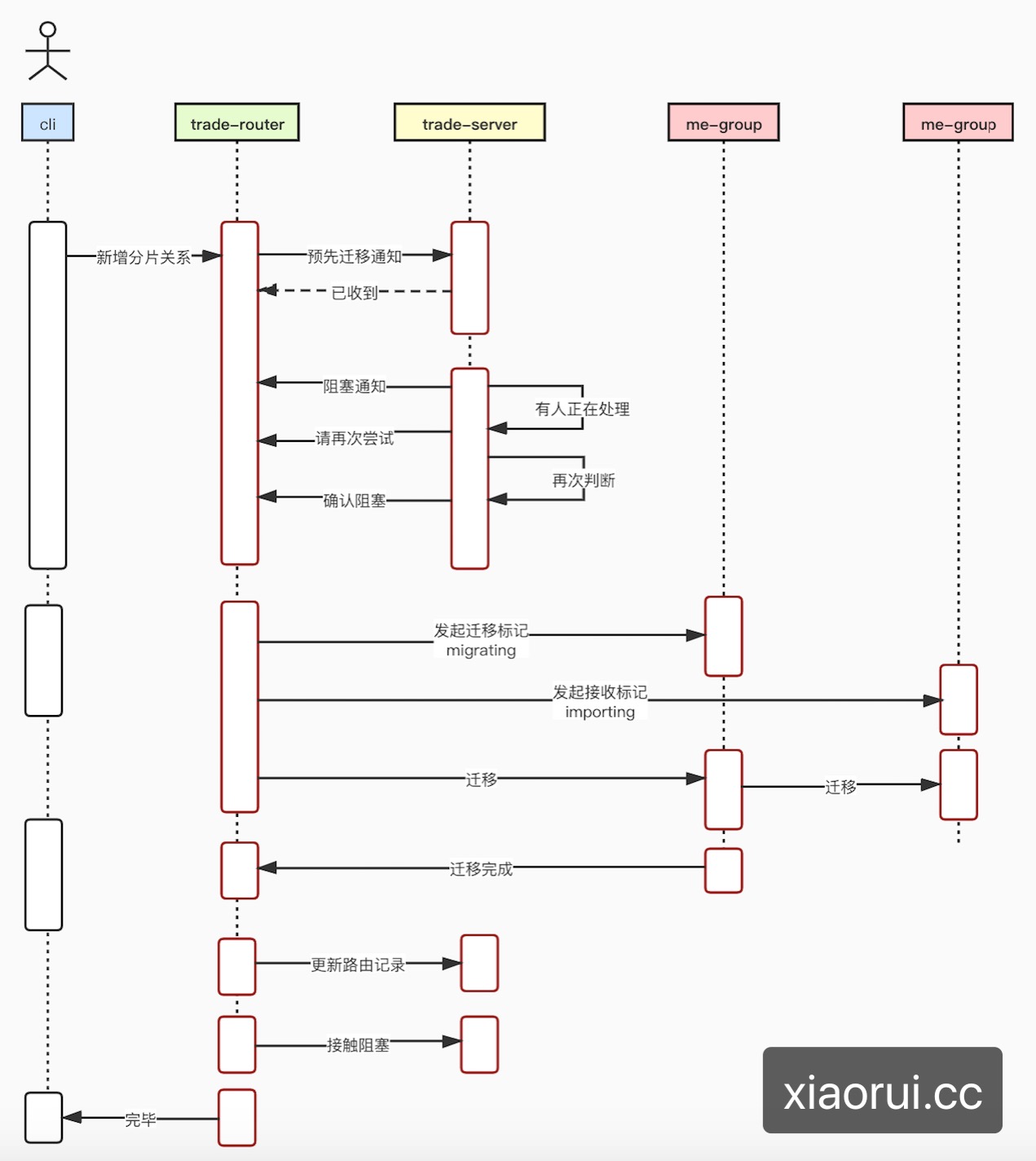
leader跟follower同步数据的过程 ?
性能调优
1 需要对订单表进行分库分表。
2 raft做节点同步时根据突发情况,进行批量同步,以减少syscall调用.
3 使用redis做查询订单的缓存,缓存算法为先更新db再淘汰缓存.
4 能批量的都批量.
5 golang使用sync.pool减少堆对象生成,时间轮来减少锁竞争,分段锁map等等
总结:
关于交易系统的分布式和高性能实现就先说这么多了,对于更多的细节会在后面的文章补上。另外,国内外不少证券和数字货币交易所的设计更是复杂,使用了比如机房直连、udp组播、原子钟等技术。
在这日益严重的疫情期间,大家要保护自己!武汉加油,中国加油🇨🇳 。


