
前言:
社区里不少人都在谈论grpc有没有必要使用连接池,我这边有个grpc网关服务因需要高吞吐、低延迟的要求,所以对此问题作了些研究。
根据我的多方面测试,在线程/协程竞争压力不大的情况下,单个grpc client 连接是可以干到 8-9w的qps。在8 cpu core, 16 cpu core, 48 cpu core都有试过,数据来看不会超过9w的qps吞吐。
在网关层使用单个grpc client下,会出现cpu吃不满的情况。如果简单粗暴加大对单client的并发数,QPS反而会下降,具体原因后面有讲述。
该文章后续仍在不断的更新修改中, 请移步到原文地址 http://xiaorui.cc/?p=6001
原因何在?
我认为影响gprc client吞吐的原因,主要是两个方面,一个是网络引起的队头阻塞,另一个是golang grpc client的锁竞争问题。
什么是队头阻塞?
我们知道http1.1是有协议上的队头阻塞问题,http2在协议上实现了stream多路复用,避免了像http1.1需要排队的方式进行request 等待response,在未拿到response报文之前,该tcp连接不能被其他协程复用。http2.0虽然解决了应用层的队头阻塞,但是tcp传输层也是存在队头阻塞的。
比如,client根据内核上的拥塞窗口状态,可以并发的发送10个tcp包,每个包最大不能超过mss。但因为各种网络链路原因,服务端可能先收到后面的数据包,那么该数据只能放在内核协议栈上,不能放在socket buf上。这个情况就是tcp的队头阻塞。
golang grpc client锁竞争问题?
我在以前的文章中有描述过,golang标准库net/http由于单个连接池的限制会引起吞吐不足的问题。怎么个不足?就是cpu吃不满。这个是跟grpc有同样的表现,grpc在48个cup core的硬件环境下,在单客连接并发200的时候,只能跑到600%左右。再高的并发数只是增加了cpu消耗,grpc qps是没有提升。
为什么net/http的吞吐性能不足? 主要有两个点.
第一点,net/http默认的连接池配置很尴尬。MaxIdleConns=100, MaxIdleConnsPerHost=2,在并发操作某host时,只有2个是长连接,其他都是短连接。
第二点,net/http的连接池里加了各种的锁操作来保证连接状态安全,导致并发的协程概率拿不到锁,继而要把自己gopack到waitqueue,但是waitqueue也是需要拿semaRoot的futex锁。
在data race竞争压力大的时候,你又拿不到锁来gopark自己,你不能玩命的自旋拿锁吧,那怎么办? runtime/os_linux.go就是来解决该问题的。有兴趣的可以看下代码,简单说就是sleep再拿锁。
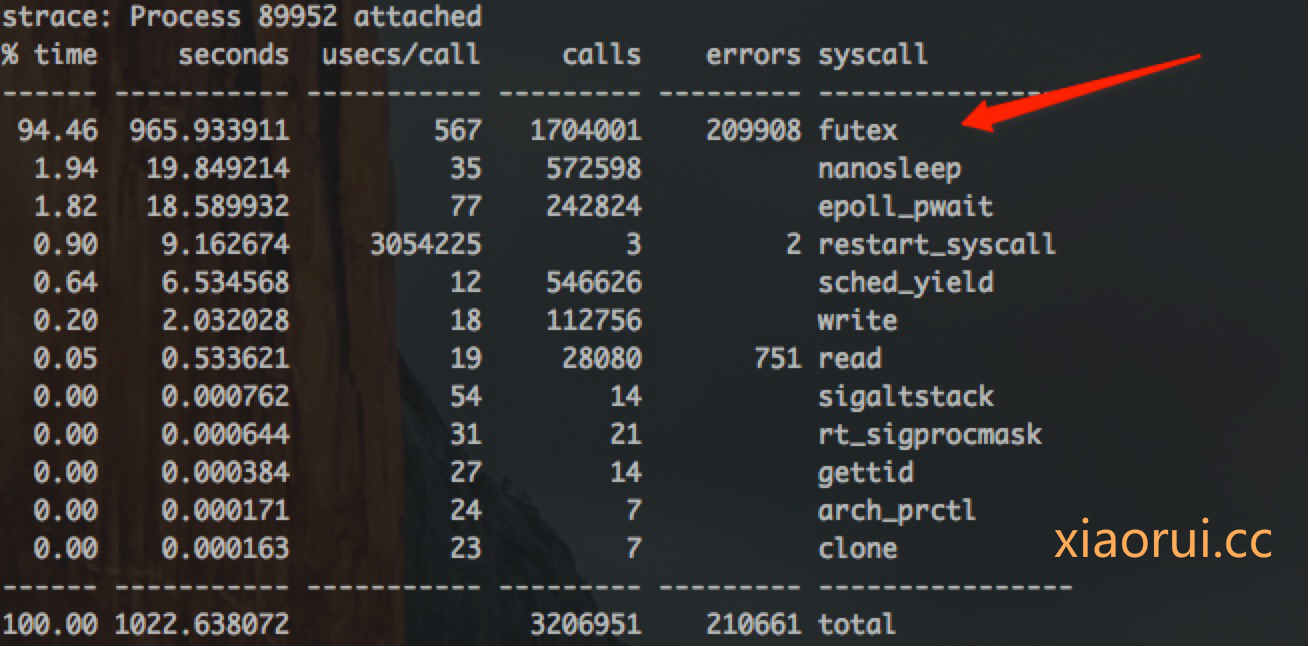
说完net/http的client的性能问题,我们在说grpc client的问题,下面是我针对gprc client压测时,strace统计的syscall系统调用。top的前两个syscall,一个是futex锁,另一个是nanosleep高精度定时器。这个数据跟net/http统计差不多情况,就此我们可以假设net/http和grpc客户端性能不足的问题是一样的。
grpc的http2.0组件是自己实现的,没有采用golang标准库里的net/http。在分析代码之前,先放一个go tool pprof的耗时分析图,我们会发现有个很大的消耗在withRetry这里,分析了代码确实有一些锁的操作,而且粒度不小。 😅


// xiaorui.cc
func (cs *clientStream) withRetry(op func(a *csAttempt) error, onSuccess func()) error {
cs.mu.Lock()
for {
if cs.committed {
cs.mu.Unlock()
return op(cs.attempt)
}
a := cs.attempt
cs.mu.Unlock()
err := op(a)
cs.mu.Lock()
if a != cs.attempt {
// We started another attempt already.
continue
}
if err == io.EOF {
<-a.s.Done()
}
if err == nil || (err == io.EOF && a.s.Status().Code() == codes.OK) {
onSuccess()
cs.mu.Unlock()
return err
}
if err := cs.retryLocked(err); err != nil {
cs.mu.Unlock()
return err
}
}
}如何grpc client的吞吐问题?
跟解决net/http一个套路,就是增加连接池。我这边写了一个应用在grpc网关的grpc client连接池,可能不适合大家直接去引用,但可以参考下。 https://github.com/rfyiamcool/grpc-client-pool
代码为了规避获取grpc client的锁消耗,所以采用了预先初始化客户端池,为了规避连接泄露,使用lazy加锁初始化连接的方法。简单说,获取client的过程不加锁。。如果有动态扩充连接池的需求,可以使用copy on write map的方法来规避锁map的读写冲突。
性能测试
单个grpc client的吞吐性能数据,在并发200的时候,client cpu在600%左右,当超过200并发后,cpu会逐渐升到1100%,qps吞吐量反降。
// xiaorui.cc
[root@k8s1 ~]# ./client -addr=10.2.0.24:50051 -c=1 -n=1000000 -g=50
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 1, worker num: 50
multi client: 1, qps is 68829
[root@k8s1 ~]# ./client -addr=10.2.0.24:50051 -c=1 -n=1000000 -g=100
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 1, worker num: 100
multi client: 1, qps is 80752
[root@k8s1 ~]# ./client -addr=10.2.0.24:50051 -c=1 -n=1000000 -g=300
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 1, worker num: 300
multi client: 1, qps is 58041
[root@k8s1 ~]# ./client -addr=10.2.0.24:50051 -c=1 -n=1000000 -g=500
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 1, worker num: 500
multi client: 1, qps is 54913
多个gprc client的性能表现情况?
// xiaorui.cc
./client -addr=10.2.0.24:50051 -c=50 -n=1000000 -g=100
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 50, worker num: 100
multi client: 50, qps is 148335
./client -addr=10.2.0.24:50051 -c=50 -n=1000000 -g=250
server addr: 10.2.0.24:50051, totalCount: 1000000, multi client: 50, worker num: 250
multi client: 50, qps is 217028
./client -addr=10.2.0.24:50051 -c=100 -n=2000000 -g=1000
server addr: 10.2.0.24:50051, multi client: 100, worker num: 1000
multi client: 100, qps is 359081在多grpc client的并发下,grpc的吞吐是可以压测到35w的QPS。多个grpc client在提高qps吞吐之外,也能规避单个grpc client在高并发请求场景下产生竞争,竞争会拖慢qps吞吐量。
有朋友可能疑惑了,一个服务实例化这么多连接好么?我们要知道nginx upstream的keepalive连接数过小的化,他的qps是上不去的。使用ab, wrk进行压测时,client数太小照样会影响qps的指标。当然,作为业务服务来说没必要使用连接池,大多数也没这么大的请求量,又因为优秀的架构设计是可以扩展分布式。但作为网关还是有必要的。
由于grpc网关的设计偏复杂,所以我单独写了个我把grpc的测试脚本,已封装成项目放到github了,有兴趣的可以拉下来性能测试。需要注意下软中断及内核日志情况。https://github.com/rfyiamcool/grpc_batch_test
总结:
grpc复用http2协议是个好事,这样能让grpc有高度的兼容性,但是相比thrift来说性能是差点意思。毕竟grpc相对于thrift来说,需要unpack两次数据包,一次是header,一次是protobuf body。但话又说回来,相比性能,grpc有更活跃的社区支持和兼容性。
像istio的envoy sidecar本就支持http2,那么自然就很容易支持grpc。而像小米为了解决kubernets istio的联合,改了不少istio的控制面板代码来支持thrift协议。

