
cgo阻塞调用引起golang线程暴增
我们知道golang抽象了一个pmg的体系概念,里面p可以理解为协程管理队列,在多核主机下go默认会设置跟cpu core相匹配的队列数。
runtime handoffp
mg跟p什么时候会解绑,在golang runtime里专业名词叫handoffp。主动的解绑,貌似只有锁操作。空任务是m跟p解绑,不会带着g。 非正常的handoffp解绑,一般是由于runtime sysmon retake()被抢占了。我们在阻塞disk io操作下,遇到过被retake抢占异常handoffp。 这样会有问题么? 是的,这样会造成大量的线程暴增。原因在先前的文章里阐述过,有兴趣的可以看看以前的文章。
那咱们文章的主题是cgo,cgo要跑起来必然也要被封装成goroutine协程结构体,然后他也是有newproc1 到runqput的过程。既然cgo的g在p里面,如果cgo有阻塞逻辑或者调用阻塞syscall,也会造成类似磁盘io那样的线程暴增? 在理解这问题之前,我们还要进一步理解golang的syscall,继续看下面.
golang里的几种syscall
第一种,rawsyscall是调用压根不会阻塞的系统调用,比如getpid, getuid, time。因为vdso机制,直接把调用打到你的进程方法映射空间里。
第二种,可被runtime调度的syscall, 这里的syscall又分为enterSyscall和enterSyscallBlock。我搜遍了golang1.9的所有可触及的代码,只有锁相关的逻辑会调用enterSyscallBlock, go把mutex锁抽象成可cas + waitqueue + futex的阻塞, entersyscallBlock因为知道可能会阻塞,所以直接就handoffp。(这里插嘴一句,golang锁底层实现很蛋疼,可以看os_linux.go里面锁等待的描述,说是一个linux的bug。)
其他常见的系统调用走的都是enterSyscall逻辑,像我们经常用到的disk io、socket io、cgo、申请内存等都是走这个逻辑。entersyscall可以被sysmon retake抢占的,如果你长时间pmg绑定,状态又为Psyscall。
那么想一个问题,为什么socket io不放在enterSyscallBlock? 因为在golang里socket都是nonblock为异步非阻塞的,基本不会阻塞。 如果硬要把放在enterSyscallBlock里调用徒然增加了调度开销,有调度的时间,都能执行完syscall了。
// xiaorui.cc
func entersyscallblock() {
...
systemstack(entersyscallblock_handoff)
...
}
func entersyscallblock_handoff() {
if trace.enabled {
traceGoSysCall()
traceGoSysBlock(getg().m.p.ptr())
}
handoffp(releasep())
}
更多的golang syscall文章,可以移步到滴滴大神老曹的go syscall原理讲述 http://xargin.com/syscall/
怎么就暴涨了?
socket io基本不会阻塞,那么diskio 和 cgo会阻塞么? disk io只要不用恶心的同步fsync,基本都是落内存,由操作系统的sync进程来flush磁盘。cgo如果逻辑没问题,不会阻塞,如果写的不好? 必然阻塞。 阻塞了就会被sysmon扫描到,继而发起抢占信号,cgo被迫handoffp,mg走了,那么需要startm找一个空闲的m, 如果线程都在cgo block中,那么就会不断的创建线程。一直到golang runtime写死的10000个线程数,才会panic异常。
调用handoffp会寻找空闲线程,如果没有就创建新线程。
// xiaorui.cc
func handoffp(_p_ *p) {
...
// if it has local work, start it straight away
if !runqempty(_p_) || sched.runqsize != 0 {
startm(_p_, false)
return
}
// no local work, check that there are no spinning/idle M's,
// otherwise our help is not required
if atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0 && atomic.Cas(&sched.nmspinning, 0, 1) { // TODO: fast atomic
startm(_p_, true)
return
}
...
if sched.runqsize != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
...
}
sysmon线程会循环检测syscall阻塞,并发起解绑抢占。
func sysmon() {
...
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
你以为golang的线程数会动态的缩减? 恩,你想多了,只有增加,就没有缩减。我从去年发现这问题,观察这问题,就没有缩减过。
cgo
为什么突然想搞cgo ? 我们在高频的cdn服务发现一个小问题,就是net/http标准库不断的创建go协程,别跟我说创建协程的开销很低,不可忽略的是gc的成本。因为每个连接最少3个协程、两个channel、一堆附属的结构体。
很早就发现有这问题了,原计划在net/http里加一层patch,把fasthttp的http groutine pool引入进去。奈何go标准库的代码相互耦合,不敢触碰。 我们现在解决方法是限频了,但是限频在创建连接和一堆结构各种资源之后才走的逻辑。
看到一篇广发证券的一个go分享,他们通过cgo的方法替换了accept,使用协程池来消费连接,用来收敛协程数。在公司憋了好几天写出不少cgo的bug代码,其中就有一个cgo线程暴涨的问题。
为了体现线程暴涨,随意写个cgo调用sleep的例子,当然你可以加入一些别的阻塞逻辑。
# xiaorui.cc
package main
/*
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void output(char *str) {
usleep(1000000);
printf("%s\n", str);
}
*/
import "C"
import "unsafe"
func main() {
for i := 0;i < 50;i++ {
go func(){
str := "hello cgo"
//change to char*
cstr := C.CString(str)
C.output(cstr)
C.free(unsafe.Pointer(cstr))
}()
}
select{}
}
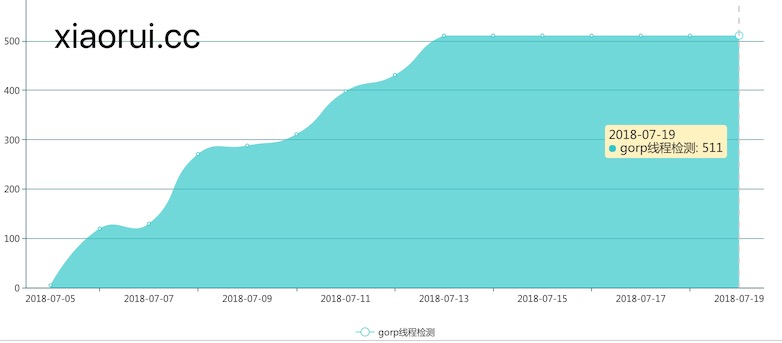
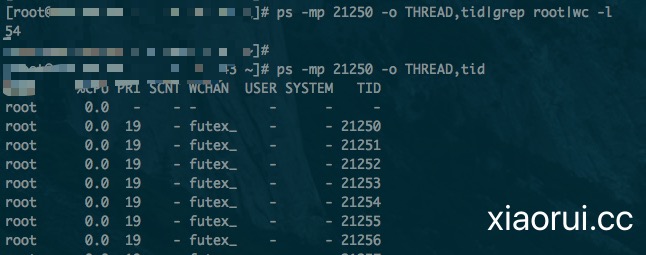
输出结果是54个线程。
怎么解决线程暴增?
当然,第一步肯定要先从本质去解决,比如 disk io 阻塞引发线程暴涨,你可以加大内存,更换 nvme ssd 存储介质。cgo引起阻塞,可以分析你的 cgo bug。
使用 runtime.LockOSThread 也可以干掉线程,这个是一个 hack 的用法。其干掉线程的方法很简单,开一个协程执行 runtime.LockOSThread,但不进行 runtime.UnlockOSThread 解绑。golang runtime 内部会做兜底处理,在方法执行退出后干掉该线程。
总结
没什么好总结,正常写golang代码应该很难出现线程暴涨的问题吧,很不巧,我就遇到过两次线程暴增。文章里更多说明什么原因会造成golang线程暴涨。大家感兴趣可以看看runtime syscall相关的源码实现,对于理解线程暴涨很有意义的。

