
前言:
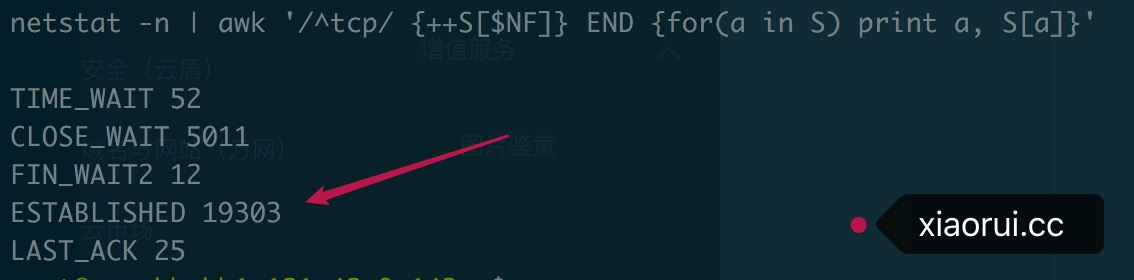
这节主要是聊聊怎么快速定位到问题,并解决问题的。 这次问题更多的是由于造了一个连接池轮子,然后自己坑自己。 事情是这样,一堆Ops找我,说我的任务派发系统连接数高达2w, 还都是established已经建立连接的,其他time-wait, close-wait 这类中间状态很少。 另外该系统是分布式的,每个机房都有几个proxy节点,算起来全网最少有几百个节点了。 下面是某个主机当时的连接数情况,当前的qps在7000左右,但后端连接的主机也才几十台…
该文章后续仍在不断更新中, 请移步到原文地址 http://xiaorui.cc/?p=5041
值得幸运的是出现这类连接暴涨的节点不到十台,而且不是主调度节点。 幸运完了,就说明下怎么分析问题的吧? 首先想,为什么以前没有这情况? 根据监控图表可以分析出,以前不管是连接数,cpu,内存,包括业务的任务量都不大,随着任务量暴增后,节点就不够用了,作为任务系统就需要承载更多的并发。
我的服务框架是多进程+协程池的方案,所以strace的维度只能是一个进程了。 通过观察,每次子进程处理一个量级后,由master重新实例化子进程的时候,子进程会很疯狂的去建立连接。 然而过一段时间平稳期后,就不会重新建立连接。 再次通过lsof 和 strace 比对文件描述符,发现平稳期内一直在复用以前的连接。 这说明什么? 说明连接池看起来没有问题的。
# xiaorui.cc/
setsockopt(3, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0
fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
connect(3, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("xxxxxx")}, 16) = -1...
既然看起来没问题,那么为毛会干到2w的连接数,还不只是一台服务器这样 ? 再次对比lsof的文件描述符,发现相同的主机建立了有30多个连接… 那么继续往下推,根绝我的经验,会建立这么多连接只有一种情况,就是并发太高,python requests连接池是借用urllib2 pool实现的,里面主要是靠tcp的四元组来匹配,当某个协程拿到连接之后,另一个协程并发执行发现没有可用的连接,那么他会重新new一个连接,当然这要看是否触发到requests 适配器的连接池的大小,不可能让他无限的暴增。

统计日志分析出并发量比先前大了不少,区间内峰值,每秒QPS已经提升到11000左右了。但问题是,并不是后端主机的任务都这么多,任务量零零散散的主机,为什么也会实例化创建这么多的http连接。 另外,连接数跟进程内的协程数几乎同一,但基本没有不会超过协程数。 这里,问题差不多可以猜出来了,协程之间没有共用这个连接池。如果是共用一个池,那么理想状态是,针对某个后端主机有几个并发,就应该有几个http连接。 连接数太多造成的直接问题就是,你的主动连接端口不够用,因为一个源ip发起的端口数只有65535,除去预留,那更少了….
回溯历史
问题的核心是 协程之间没有共用连接池。 项目的初期,我用的是requests这么非常human的库,但他最大的问题就是性能 !!! 封装过多,另一方面他底层的urllib2的http protocol parser性能也不行。 在暴力压测的场景下,cpu奇高无比,各类性能分析可以确定http parse有不少的性能损耗责任。 后来选过一些性能相对高端但是比较难用的http client, 像uvloop的httptools、fasthttp、meinheld http client,在压测环境下性能还是很客观,最少cpu不会吃的那么高。但是他们的最大问题是,连接池都好用,小问题不少…
后来索性自己实现一组连接池,当初因为是着急退换requests,各方面考虑不周,没有加入线程安全维度,只能暂时每个协程实例化连接,规避线程安全问题,这也是问题根源所在…. 退回到requests的时候,中间也遇到一个问题,就是连接数不够用,他可能会阻塞 ? 如果你默认开启了最大限制及block选项,怎么算单个进程的最大的连接数 ? 协程数 * 后端主机数 = 最大连接数. 因为你要想到一个问题,所有的协程都在并发请求一个主机…. 对于一个高频的服务来说,连接数过几千是很正常的事情.
监控图
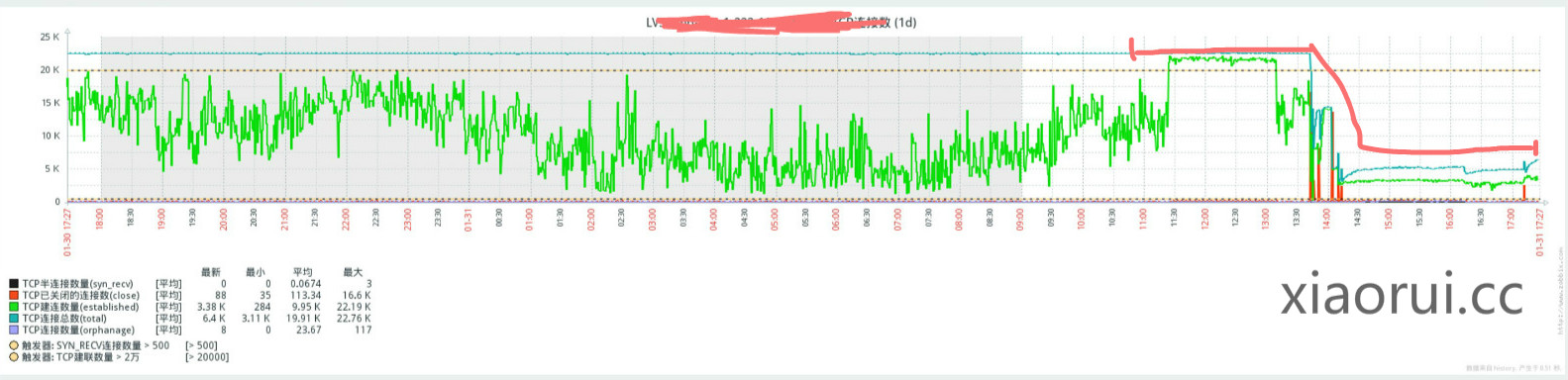
下图是tcp连接数暴涨的趋势图,后面是我找到原因,并重新打包上线后的情况。连接数已经降低到 2k 左右了。
总结:
老人常常说,造轮子是有风险的…. 好像是这么一回事… 好在,发现问题到解决问题,半小时搞定 …
END.

