
前言:
Hello , 有点怀念自己做运维的日子,做个试验,直接自己给自己分配N个服务器的权限,然后嗷嗷的开打。变为开发后,尼玛的求监控组的大哥大妹子们干点事,贼and真不容易 ! 要问他们是谁? 他们是大大爷 。轻易别找他们,因找了也是白找。
上次因为python和redis长时间brpop的时候,会有线程休眠挂起的情况,所有通知报警平台被下线了。这次算是完美解决了。再把这fix后的代码推上线,调试和模拟压力都通过,然后把公司的告警平移往我这边的接口上。
这边正在改zabbix cmdb的控制,所以暂时不能登录,因为这是个非常时期,一不注意的F5刷新都有可能造成并发。学习让他们帮忙写个redis和mogodb的监控,居然还让我发邮件和提供脚本及思路啥的。。。 一寻思,又要去zabbix,又要写脚本,还不如把监控都集合在自己的平台上的了。
这次没用选用钟爱的ganglia,麻烦。 也没用另一个graphite,而是用的是munin 。 一个直接yum后就可以访问的性能监控页面。
官方的redis监控和mongodb看起来很麻烦的样子,算了。直接看他们是怎么写的。源码是perl写的,插件好多是shell写的。
强势插入,标注原文地址 blog.xiaorui.cc
写法是相当的简单,只需要指明下图片的显示Y X 轴 ,然后echo就可以了!
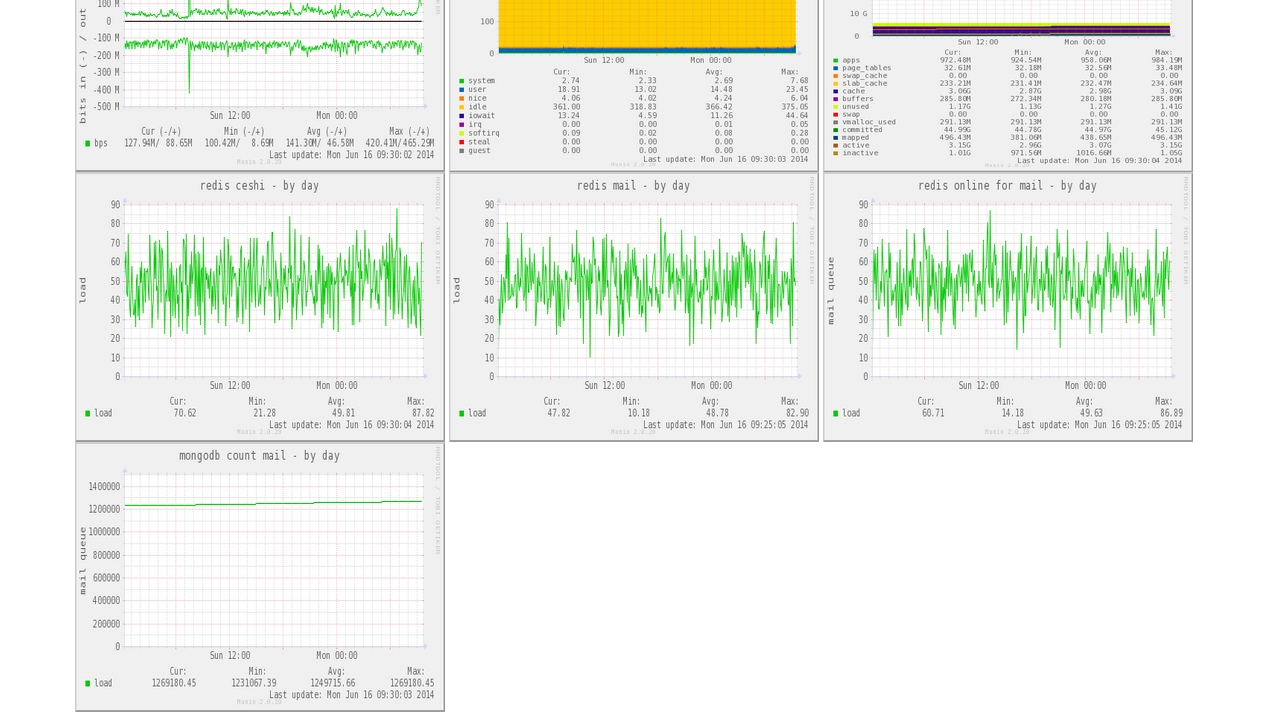
下面是redis 的token使用热点数据,队列的数据,及mongodb count的数据,说多了,你们也懒得去懂,反正就是一堆要监控的。
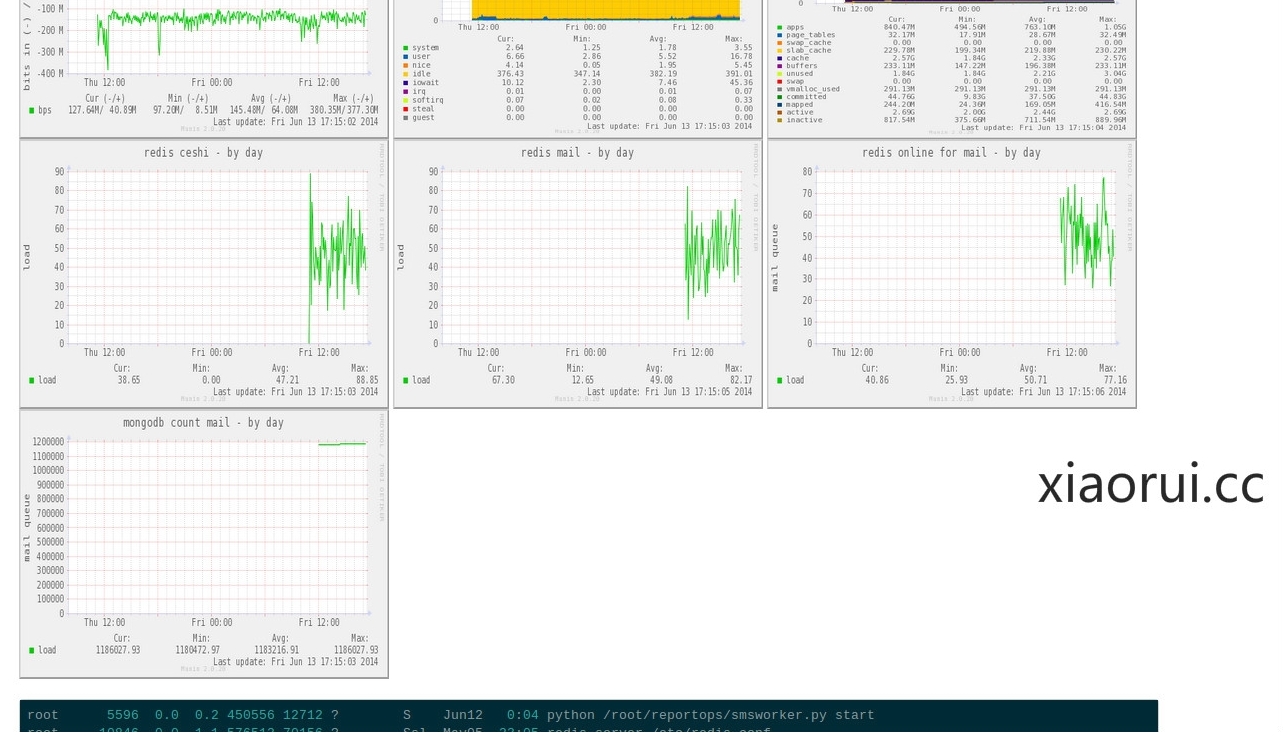
上面的图数据没有打满,今天在补上:
脚本的位置: /etc/munin/plugins
监控mongodb的脚本:
#xiaorui.cc
if [ "1" = "autoconf" ]; then
echo yes
exit 0
fi
if [ "1" = "config" ]; then
echo 'graph_title mongodb count mail'
echo 'graph_args --base 1000 -l 0'
echo 'graph_vlabel mail queue'
echo 'graph_scale no'
echo 'graph_category system'
echo 'load.label load'
echo 'graph_info The load average of the machine describes how many processes are in the run-queue (scheduled to run "immediately").'
echo 'load.info 5 minute load average'
exit 0
fi
echo -n "load.value "
mongo reportops --eval "db.reportops_log_mail.count()"|tail -n1
监控redis队列的脚本:
写完了后,/etc/init.d/munin-node restart 就可以了。等一会刷新下页面就出来了。
关键就是最后那两行。。
echo -n "load.value " redis-cli LLEN sendmaillist|cut -d '' -f2
网上有人做了python的munin操作模块,有兴趣的朋友可以试试。
#!/usr/bin/env python
import os
from munin import MuninPlugin
class LoadAVGPlugin(MuninPlugin):
title = "Load average"
args = "--base 1000 -l 0"
vlabel = "load"
scale = False
category = "system"
@property
def fields(self):
warning = os.environ.get('load_warn', 10)
critical = os.environ.get('load_crit', 120)
return [("load", dict(
label = "load",
info = 'The load average of the machine describes how many processes are in the run-queue (scheduled to run "immediately").',
type = "GAUGE",
min = "0",
warning = str(warning),
critical = str(critical)))]
def execute(self):
if os.path.exists("/proc/loadavg"):
loadavg = open("/proc/loadavg", "r").read().strip().split(' ')
else:
from subprocess import Popen, PIPE
output = Popen(["uptime"], stdout=PIPE).communicate()[0]
loadavg = output.rsplit(':', 1)[1].strip().split(' ')[:3]
return dict(load=loadavg[1])
if __name__ == "__main__":
LoadAVGPlugin().run()
总结下,munin真的够简单的了,他的简单也意味着,他也就 适合我这样的研发人员临时做些统计的场景,还有个前提,你要有root,因为有root的开发可是很少哦。 关于性能问题,记得以前使用munin,当时做zeromq的统计,超过几十台是没啥问题,当然这话是(feihua),要是几十台都有问题,那这监控的水准确实够烂。 这东西的局限确实够大。也就临时画画针对你的需求还是蛮不错的。

