
为什么要做告警平台? 到底是为什么? zabbx自己不就能发邮件么? 干嘛需要报警平台支持呢 ?
公司zabbix所监控的机器早就过万了,对于他们的报警触发,这边是调用smtplib通过exchange的smtp服务来发邮件,经常遇到3-5s之后才发件成功的情况,试想下zabbix发件那么多,又那么频繁,他的系统资源消耗是很多的。
其实有朋友说了,可以用postfix做扩展mta,这东西在***的时候,和公司的邮件大神交流过,得到的结果是,用postfix做第三扩展mta快是快了,但是增加了自己运维的成本,说白了就是没事找事,找si。 然后你给postfix是快了,但是呢,postfix里面的邮件还是会扔给exchange处理的。 所以这也不是我想要的。
zabbix进行报警告警的方式有那么几种,最常用的其实还是脚本的模式,其实我想要的是http的模式,看了下官方的文档,没有提供这个功能。
看了一段时间的zabbix发信的代码,一头雾水,其实我的想法很简单,不许要zabbix调用脚本,而是通过zabbix的底层代码直接发送http信息。毕竟调用脚本程序,然后在发送http,他的进程消耗肯定不小。 这个路子不通,倒是还有一条路子,那就是遍历下数据库的alerts的信息,然后搞出来发出去。 他的扩展行更好,能组合查询出更有效的信息组合。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> desc alerts;
+————-+———————+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+————-+———————+——+—–+———+——-+
| alertid | bigint(20) unsigned | NO | PRI | NULL | |
| actionid | bigint(20) unsigned | NO | MUL | NULL | |
| eventid | bigint(20) unsigned | NO | MUL | NULL | |
| userid | bigint(20) unsigned | YES | MUL | NULL | |
| clock | int(11) | NO | MUL | 0 | |
| mediatypeid | bigint(20) unsigned | YES | MUL | NULL | |
| sendto | varchar(100) | NO | | | |
| subject | varchar(255) | NO | | | |
| message | text | NO | | NULL | |
| status | int(11) | NO | MUL | 0 | |
| retries | int(11) | NO | | 0 | |
| error | varchar(128) | NO | | | |
| nextcheck | int(11) | NO | | 0 | |
| esc_step | int(11) | NO | | 0 | |
| alerttype | int(11) | NO | | 0 | |
+————-+———————+——+—–+———+——-+
|
把上面的话总结下,一句话,解决zabbix发信的负载问题。
软件框架:
接口:
nginx lua/nginx tornado
队列:
redis
mq:
zeromq
数据库:
mongodb (文档型数据库,最适合做这个干练的事情)
后端daemon:
python gevent smtplib requests
报警的来源:
zabbix,nagios,各种形式的报警来源
这里先描述下,运转的一个例子,比较简单的流程:
1. 用户发信息
curl -d “sendmode=mail&sendto=ruifengyun@xiaorui.cc&sendtitle=服务器死掉了&sendcontent=1.1.1.1” http://xiaorui.cc/recpost
2. 我这边收到信息并插入到redis后,会立马给他return一个状态。
3. 后端起一个daemon专门处理队列,并通过zeromq来分发任务,里面用了0mq的rep/req 和pull push这两个方案。
4. 当本地节点或者是分布式的节点收到msgpack的信息后,会解析要发送的信息,发送,并返回状态。
5. zeromq master端收到状态后,入库。
报警平台难道只有这些么? 当然不,其实报警平台最主要的核心是智能的分析和报警收敛,告警关联。
有很多重复性和有规律的邮件,短信,咱们可以统一发件,而不是每次都发。 因为收件人时常会懒得看邮件,因为太多了,烦了。那咱们有必要做一次统计方案。报警收敛,主要是体现在信息的整合,比如nginx1、nginx2、nginx3… 都开始狂爆502的网关错误,如果对方的接口加了支持调优的参数,我这边会延迟报警,然后把信息整合后再发送。例子是这样的,以后结果就是,每个人收到的短信和邮件都是精华。
再说下告警的关联,比如mongod数据大的时候很吃内存,引起了两个报警触发,一个是mongodb内存大了,还有一个是系统的内存比率大了。这个时候,可以做一些判断。 当然这些规则需要后期整理写入的。 我在后端的逻辑里面预留了这段代码的嵌入,以后可以做成一条条的匹配。
当然报警的智能收敛不是这么好搞的,毕竟他延迟了告警做相关的匹配。但个人认为利还是大于弊端的。
平台后期可以做大量的数据统计。
因为每次告警都是通过该平台接口来发邮件和发短信,我这边根据库里面的信息,做出那个哪台服务器,哪个业务,哪个时间段,哪种报警类型等等的统计。根据这些可以做定期的报表。
下面是我这十几天做的项目demo,现在已经接入了zabbix的接口,等再测试一段时间后,就替换zabbix报警接口 ~

通过二维码可直接访问。

这里是给开发和运维人员提供的报警的接口文档,提供了多个接口形式,字段除了必须那三个字段外,其余的可随意定义。

这是发送邮件的历史信息查看,可以通过各种选项配合正则来查询各种信息。

这里是可以清空队列和选择性的***队列信息。

这是短信的历史记录接口,方便的各种查询。

这是大屏幕监控,现在做的有点粗糙,对于各种报警的级别还没有做细化,这报警平台页面后期可放在公司墙上的大屏幕,实时查看各种动向,对于重要的业务,会有声音的提醒。简单点的有 叮叮的声音,如果你的声音够磁性,可自己录音。 比如,xxx的nginx挂了,你妹的赶紧处理呀。

邮件的样式模板:


一个简单的调试页面:

数据的分析以后造成这个样子,这是我以前做的一个报警分析的东西 ~
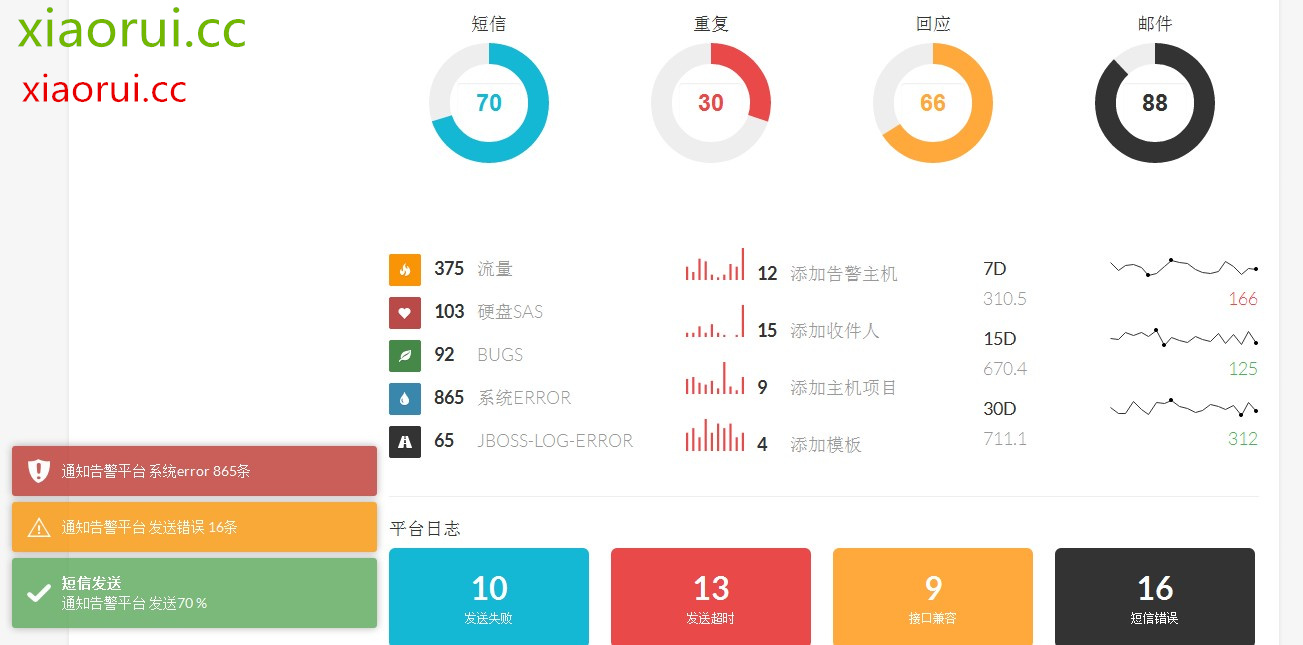
挂在公司的电视上,做大屏幕 !

这样咱们一抬头就很方便看到zabbix报警信息~

还没有写完,待续~~~条件过滤的实现,可以方便的定义,你要过滤的条件,比如相同的报警内容不能在30秒内重复发,包括内容的正则的匹配!

