
前言:
我想大家都知道 ssdb ,pika吧,这两个nosq都是兼容redis协议的存储。 底层的存储用的是kv结构的leveldb,后台这两nosq都渐进到rocksdb , 因为在数据量大的情况下 rocksdb性能更高。
RocksDB支持一次获取多个K-V,还支持Key范围查找。LevelDB只能获取单个Key。RocksDB提供一些方便的工具,这些工具包含解析sst文件中的K-V记录、解析MANIFEST文件的内容等。有了这些工具,就不用再像使用LevelDB那样,只能在程序中才能知道sst文件K-V的具体信息了。
RocksDB支持多线程合并,而LevelDB是单线程合并的。LSM型的数据结构,最大的性能问题就出现在其合并的时间损耗上,在多CPU的环境下,多线程合并那是LevelDB所无法比拟的。不过据其官网上的介绍,似乎多线程合并还只是针对那些与下一层没有Key重叠的文件,只是简单的rename而已,至于在真正数据上的合并方面是否也有用到多线程,就只能看代码了。
RocksDB增加了合并时过滤器,对一些不再符合条件的K-V进行丢弃,如根据K-V的有效期进行过滤。
压缩方面RocksDB可采用多种压缩算法,除了LevelDB用的snappy,还有zlib、bzip2。LevelDB里面按数据的压缩率(压缩后低于75%)判断是否对数据进行压缩存储,而RocksDB典型的做法是Level 0-2不压缩,最后一层使用zlib,而其它各层采用snappy。
在故障方面,RocksDB支持增量备份和全量备份,允许将已删除的数据备份到指定的目录,供后续恢复。
那么说到底 rocksdb只提供了key – value的结构, 那如何实现一个list和hash数据结构. 上次在giac听过360关于pika的分享,还是有些收获的。
Rocksdb 、leveldb的数据结构是 lsm tree, 日志合并树是可以保证数据对应到磁盘同样是有序的.
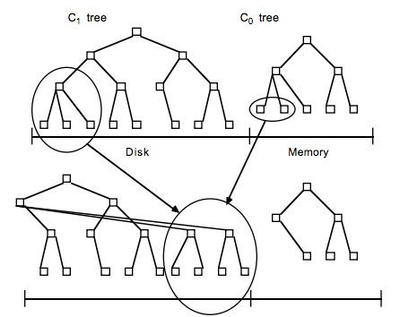
数据结构是如何映射的 ?
下面的图片就是引用了pika的设计… 大家一看就懂的…
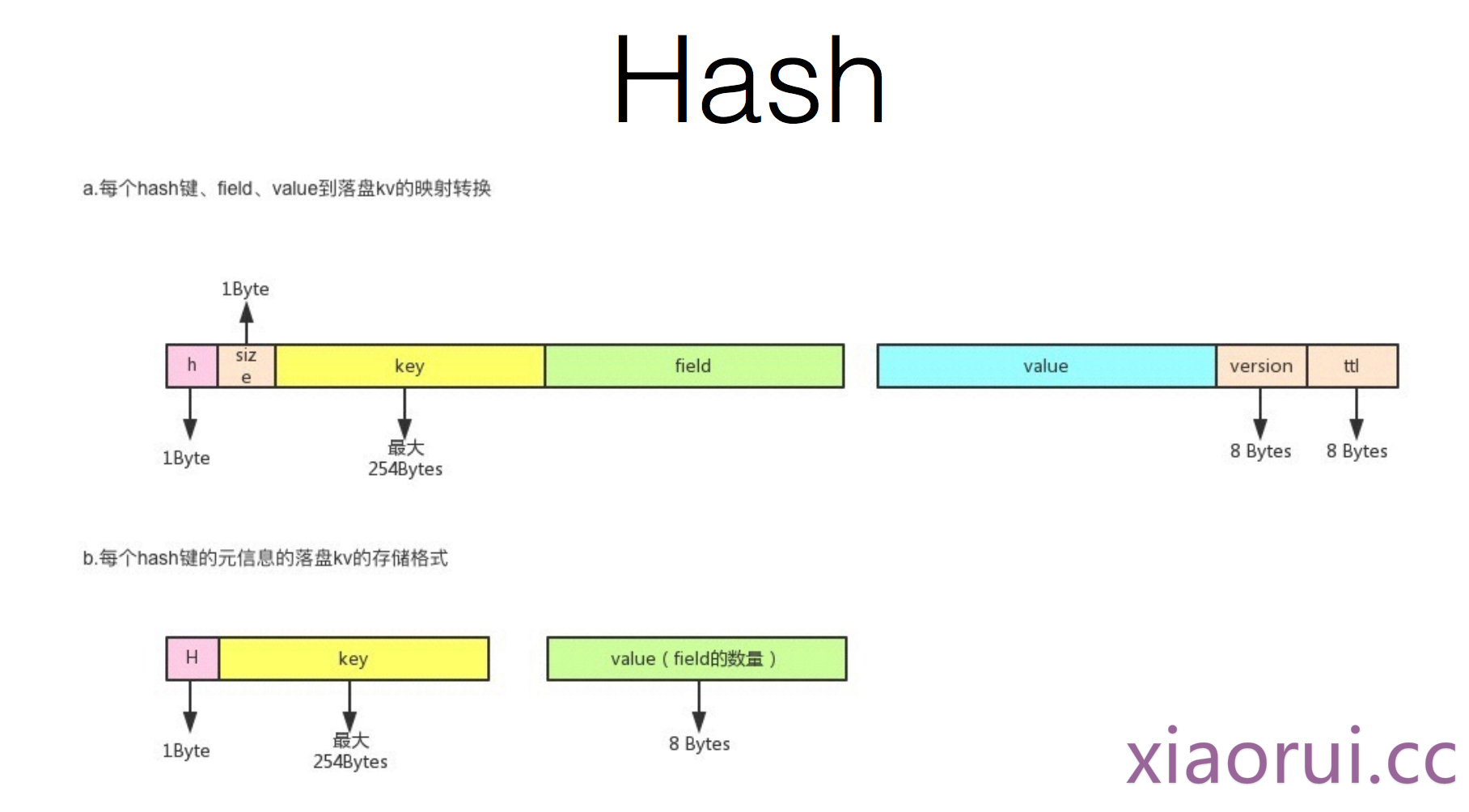
比如你要实现hash的这么几个功能,hset,hget,hkeys,hlen
hset article_776 url xiaoru.cc 对应到rocksdb的结构是 key: hash_article_776_url value: xiaorui.cc . 这么设计就很容易拿到article_776 url的value。
hash里有很多的二级key,那怎么求hlen ? 再set一个kv, key: hash_article_776 , value: length大小 .
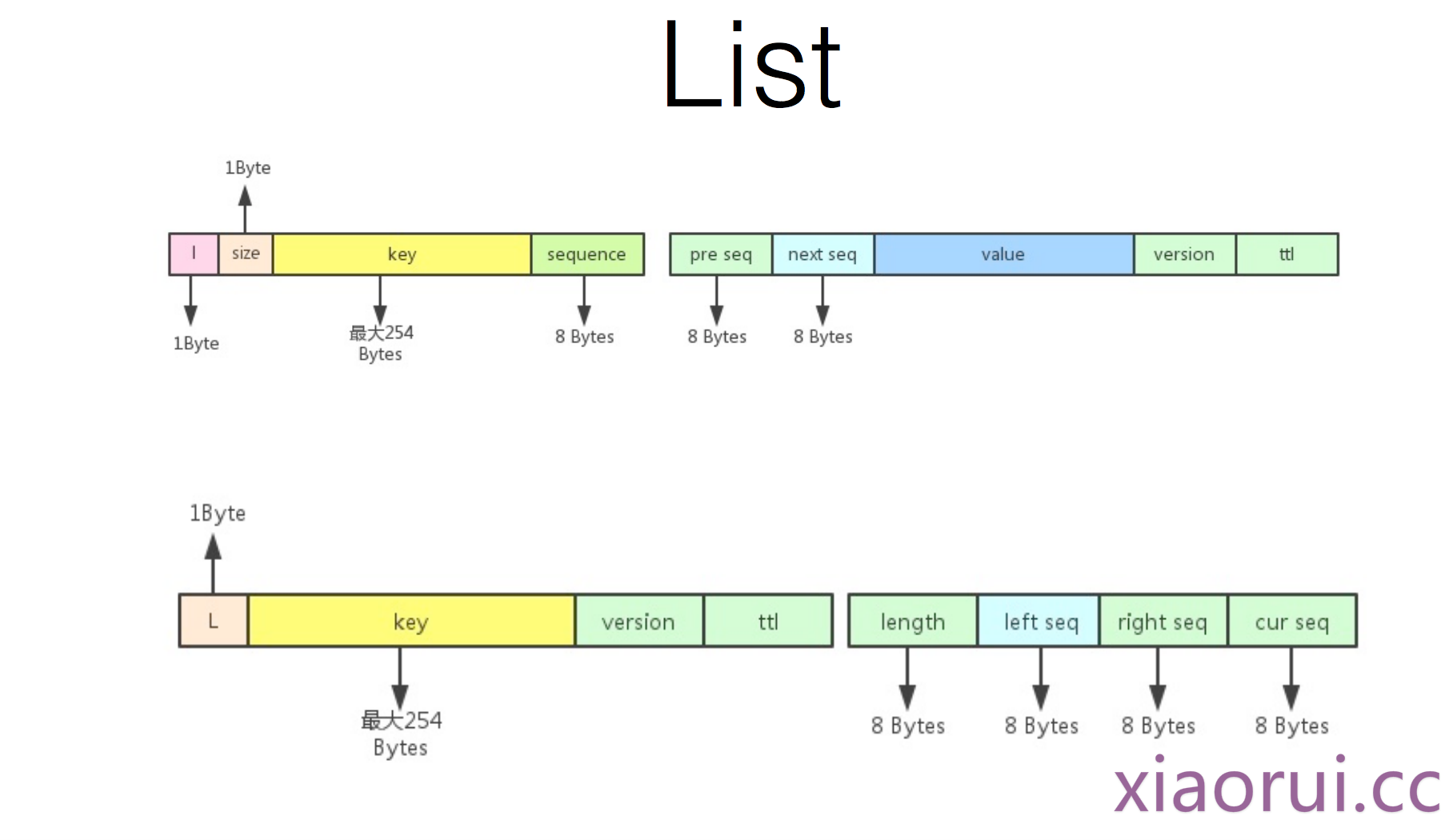
那么如何实现复杂的有序集合 zset 呢 ?
我们知道zset的操作不外乎有这么几种, zadd, zrank, zscore, zscard,zrangebyscore .
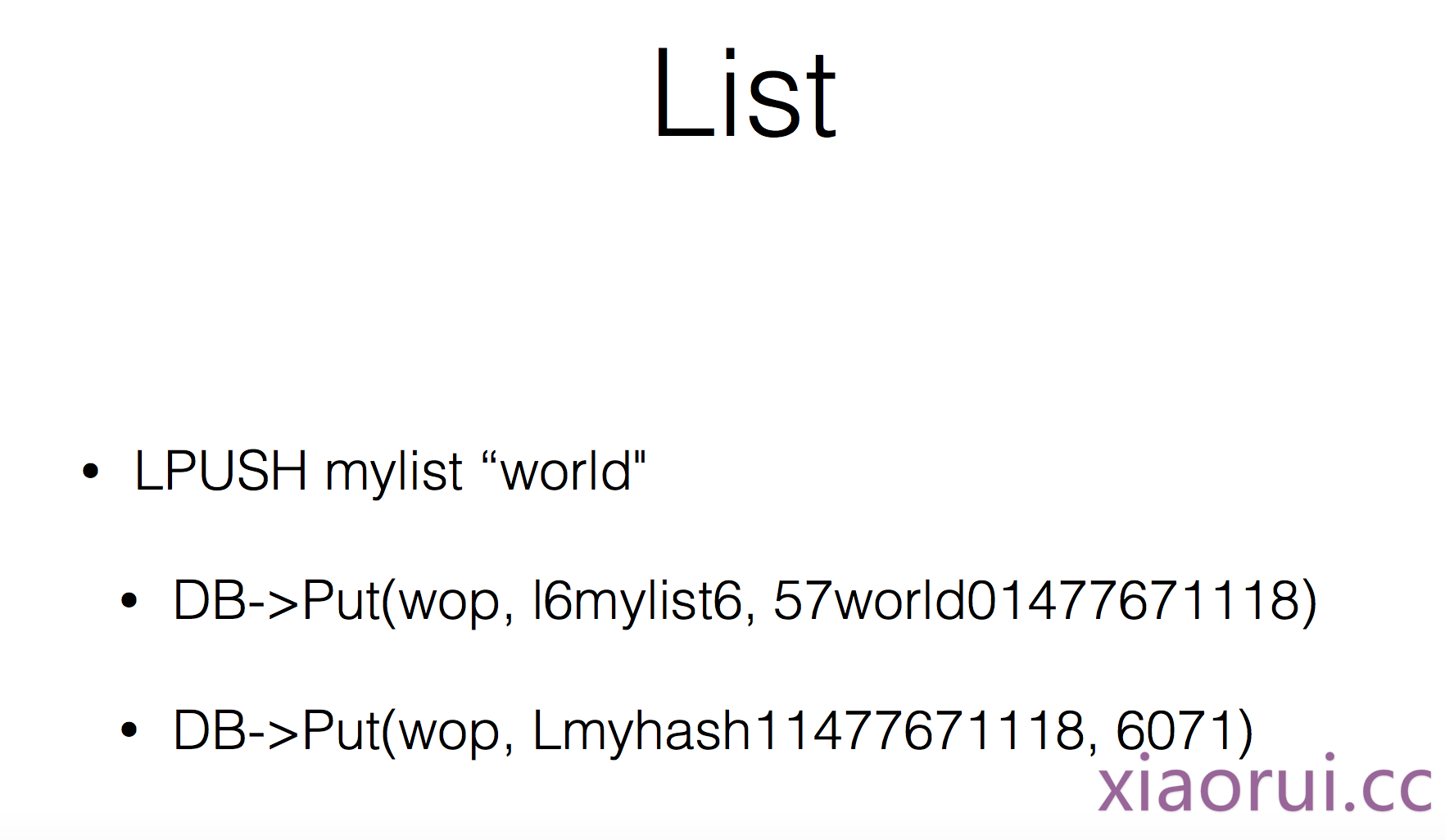
zadd article_776 1 k1 映射到rocksdb数据格式是下面几个。 这样我们满足了zscore, zscard 的需求. 但是zrank 怎么搞? 我们知道zrange是用来获取zset里的index范围,但是rocksdb本身也支持一个所谓的范围查找. 首先我们明确一点 rocksdb的底层lsm可以保证数据的有序… 那么就好办了,我们只要先匹配 prefix+ keyname之后,通过O(N)的复杂度往右面渐进查询就可以了。
# xiaorui.cc key: zset_article_776_1 value: k1 key: zset_article_776_k1 value: 1 key: zscard_article_776 ,value: 1

持续更新中>>>


棒棒的