
话题内容 《 服务限流与服务降级那些事儿 》. 讲述下这方面的所谓经验和学习积累吧.
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新.
什么是限频和服务降级 ?
要保证一个大流量对外服务的稳定性, 通常我们很相当注意两个功能控制… 一个是请求的限流,一个是服务降级处理,他的意义在于不会让你的服务全瘫痪了,你可以适当的损失点东西利益,来保证最基础的功能, 这就是过载保护.
每个接口所能提供的单位时间服务能力是有限的。超过服务服务的承载能力,一般会造成整个接口服务停顿,或者应用 Crash毁掉,或者带来一系列未知已知的连锁反应,这样造成整个系统的服务能力丧失,SO 有必要在服务能力超限的情况下实时过载保护。 微信抢红包和小米抢购中,我们会遇到有人OK,有人被友好的deny了,这是因为服务过载保护了 .
为什么要做限流限频和降级?
首先假设几个有意思的场景,从用户访问的角度来看,如果设想有人想暴力碰撞网站的用户密码;或者黑客们尝试各种的sql注入;或者有人cc攻击某个很耗费资源的接口;或者有人想从某个接口大量抓取数据接口等等。 这时候标准的方法是加 应用级的防火墙,也就是咱们说的waf, waf是自带在线行为分析的.
除此之外,我们可以想象促销抢购的需求,当我们已知服务的只能应答约500qps, 但通过促销活动的力度推测可能要超过这个数,请求格外的多….
这时候就要做过载保护了,增加Rate limiting请求限速是个相当直接又易用的好办法。 请求增加限频后,我们后面有时间进一步解决这个问题,比如封堵来源或者特征… 也就是说 限速 是最根本的要求. 那么对于抢购的正常的请求遇到限速后,那么没办法,只能是粗暴的踢人了, 虽然损失了一部分超限的正常请求,但最少还能接客… 不至于请求都来了,后端服务因为处理不过来,直接hang住了,没得玩了…
可以想象成 村里的土鳖电闸安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏. 同理我们的接口也需要安装上“保险丝”,以防止非预期的请求对系统压力过大而引起的系统瘫痪,当流量过大时,可以采取拒绝或者引流等机制。
再回溯下刚才的电商促销场景,这对于 “服务降级” 的意义又是什么? 为啥又要用服务降级 ?
当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
假定可以分为一级服务,二级服务,三级服务,比如在紧急情况下,务必保证一级服务的稳定性,然后可以牺牲二级和三级服务,这个就是服务降级.
如果还是不懂,那么再举一些例子. 分级保护下 电商里面基本查询和支付可以用,至于评论、买家秀、聊天、收藏、评分等等可以先放放,最少保证买东西到付款这几步的api能正常. 又比如qq当带宽不够时 先砍视频通话,接着砍语音、传文件、群聊天、群图片、各信息推送. 最后最后至少能保留用户的在线状态. 以此类推,各种事例…
服务降级方式:
分级范围拒绝: 也就是我们上面说到的路数,根据uri来区分接处理口, 对于大量的接口适合走nginx lua redis, 当然你在后端做也可以.
增删改查接口拒绝:拒绝所有增删改动作,只允许查询, 错误页面内容可在CDN内获取。 如果是查询,那么直接走cache.
延迟持久化:页面访问照常,但是涉及记录变更,会提示稍晚能看到结果,将数据记录到异步队列或可回溯log,服务恢复后执行。
xxx: 还有几种….
说完服务降级后,再聊下服务请求的限频问题.
在哪里实现接口的限速限频 ? 限速限频的算法有多少?
接入层的限流:
- 基于nginx的limit_conn模块, 用来限制瞬时并发连接数.
- 基于nginx的limit_req模块, 限制每秒的平均速率.
-
基于nginx lua redis定制模块, 可实现多时间区间限速,具体uri限速、用户层限速等, 当然可分布式限速.
后端服务层限速:
- 基于用户级别的限速.
- 基于api的限速.
- 基于用户加api的限速.
- 基于流量限速
- 等等…
后端实现的限速明显更加细致灵活,前端因为是nginx所以性能肯定是最好的. 理论上来说后端能实现的复杂限速体系,我们可以复用在前端接入层. nginx lua可以足够我们构建复杂的接口限频体系了. 如果咱们是集群的场景,量级又不是吓人的. 用后端的限速完全可以支撑一个量级,多了不敢说,我们长期压测十几万的限频速度是没有问题, 注意 压测源和服务处理都是集群 !!!
我们知道分布式限速讲究的是快,那么redis就足够快的了,一个实例完全可以到7w稳定的ops. 那么一致性hash + redis多实例 .
当然共享的计数的nosql是快了,后端的性能又怎么保证? 你的后端如果是那种bio模式,比如php-fpm、uwsgi、早期apache prefork. 那就没得扯了.
为啥bio不行? 你在google去 !!! 当时后端是golang beego… 后来因各种情况变更成渣渣python,web框架是自己用libev撸的轮子, 支持多进程那种, 服务器加到5台左右, 也是可以压到十几万的限频速度.
接入层的限速相对来说粗暴呀. 像limit_conn、limit_req是可以用ip地址或request path限频的. 但如果你想要那种用户层的限速,可以通过cookie来控制,现存的limit_xxx模块有点粗,不能拆分cookie, 这时候只能上nginx lua了.
我见过最复杂的限频是针对用户、uri、用户+uri、多时间区间分别来限速的… 特蛋疼…. 为了解决一次次的redis io时间消耗,我们上了redis内置lua. 但是redis lua又不支持跨多实例及机器. redis cluster也无法使用lua. 那么只能提前定义规则,尽量hash到一个redis.
服务限频限流有这么几种方法:
- 第一是 令牌桶限流算法
- 第二是 漏桶限流算法
- 第三个是 原子计数器的算法.
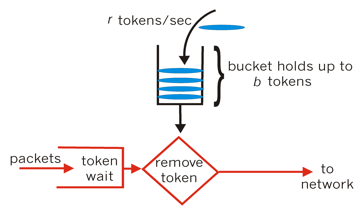
令牌桶算法:
1. 每秒会有 r 个令牌放入桶中,或者说,每过 1/r 秒桶中增加一个令牌
2. 桶中最多存放 b 个令牌,如果桶满了,新放入的令牌会被丢弃
3. 当一个 n 字节的数据包到达时,消耗 n 个令牌,然后发送该数据包
4. 如果桶中可用令牌小于 n,则该数据包将被缓存或丢弃
漏桶算法:
1. 数据被填充到桶中,并以固定速率注入网络中,而不管数据流的突发性
2. 如果桶是空的,不做任何事情
3. 主机在每一个时间片向网络注入一个数据包,因此产生一致的数据流
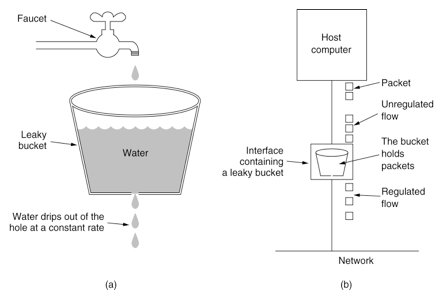
这两个算法是有区别的: 漏桶算法能够强行限制数据的传输速率, 而令牌桶算法在能够限制数据的平均传输速率外,还允许某种程度的突发传输.
计数器限频:
简单粗暴的累加计数, 超过就deny,没超过就pass. 我们可以用当前时间的某个单位及方法参数的md5做成key. value是Int数值,然后累加计数就可以了. 我个人还是比较喜欢计数器的限频,可以设置多个时间区间,比如一秒钟可以10个,一分钟只能200个,一小时只能8000个… 计数限频不单单是那种类似常量和length方法对比限频,比如说,数据库的连接数,协程池,秒杀并发. 而且也是可以实现 令牌桶及漏桶的算法的.
其实前两种限速限频算法更多的用于接入层,比如nginx,iptables mark tc, 网络设备qos 等等. . .
针对nginx limit_conn limit_req限速的配置,这里简单阐述下:
添加limit_conn 和limit_req 这个变量可以在http, server, location使用(如果你需要限制部分服务,可在nginx/conf/domains里面选择相应的server或者location添加上便可) 一般都是选择性的添加限频, 比如针对登陆、支付接口可以加 location层限频,针对普通增删改查的逻辑可共用一套限频. 针对翻页递归的查询应该独立一套限频. 类似的还有全文搜索,嵌套评论等等.
# xiaorui.cc
vi /export/servers/nginx/conf/nginx.conf
limit_zone one binary_remote_addr 20m;
limit_req_zonebinary_remote_addr zone=req_one:20m rate=100r/s;
limit_conn one 50;
limit_req zone=req_one burst=150;
参数详解( 数值按具体需要和服务器承载能力设置):
limit_zone,是针对每个变量(这里指IP,即$binary_remote_addr)定义一个存储session状态的容器。这个示例中定义了一个20m的容器,按照32bytes/session,可以处理640000个session。 limit_req_zone 与limit_zone类似。rate是请求频率. 每秒允许100个请求。 limit_conn one 50 : 表示一个IP能发起50个并发连接数 limit_req: 与limit_req_zone对应, burst表示缓存住的请求数。
有些时候我们不希望对搜索引擎的蜘蛛或者某些自己的代理机过来的请求进行限制, 对于特定的白名单ip我们可以借助geo指令实现。
http{
geo limited {
ranges;
default 1;
127.0.0.1/32 0;
10.12.212.1-10.12.212.255 0;
}
maplimited limit {
1binary_remote_addr;
0 "";
}
limit_zone one binary_remote_addr 20m;
limit_req_zonelimit zone=req_one:20m rate=100r/s;
limit_conn one 50;
limit_req zone=req_one burst=150;
}
1.geo指令定义了一个白名单limited变量,默认值为1,如果客户端ip在上面的范围内,limited的值为0
2.使用map指令映射搜索引擎客户端的ip为空串,如果不是搜索引擎就显示本身真实的ip,这样搜索引擎ip就不能存到limit_req_zone内存session中,所以不会限制搜索引擎的ip访问
根据上面的limit_req配置,当我们发起一个并发请求=151,那么漏桶算法会拒绝1个,处理100个,进入延迟队列的有50个:
14 #time request refuse sucess delay 15 #00:01.1 151 1 100 50 16 #00:01.2 0 0 50 0 17 #00:01.3 0 0 0 0
先这样,下篇文章会聊下这些降级和限频方法的具体实现.

