
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,他不仅能做去重处理,更主要的是在海量的元素下,占用的内存空间要比redis集合要少的多,我后面有测试的结果……
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
标记下博客的原文地址…. http://xiaorui.cc/?p=1724

问题来了,什么是基数,基数估算?
就是类似集合一样,可以做大量的去除,并且可以计算总数. 基数估计就是在误差可接受的范围内,快速计算基数。 他跟redis set的区别区别其实还是很大的,Hyperloglog这种类型是取不出里面的结果的,set是可以的。
在搜redis hyperloglog的时候,看到有些人在用HyperLogLog做独立的IP的统计,算是个实时计算。 避免了后期需要跑mapreduce来计算网站的独立IP访问量。 另外他跟同样海量数据算法的bloomfilter有些相似,都可以做海量的元素集合判断… …
还有关于基数计数方面,HyperLogLog可以有计数的。 传统 BloomFilter 只能添加元素,不能对元素计数,也无法删除元素。如果把底层数组的 bit 换成 int,就可以支持计数和删除动作。每次插入元素时,将对应的 k 个 int 加一;查询时,返回 k 个 int 的最小值;删除时,将对应的 k 个 int 减一。
redis的文档上,对于hyperLogLog一共就开放了三个接口…
Redis HyperLogLog 命令
下表列出了 redis HyperLogLog 的基本命令:
序号 命令及描述
1 PFADD key element [element …]
添加指定元素到 HyperLogLog 中。
2 PFCOUNT key [key …]
返回给定 HyperLogLog 的基数估算值。
3 PFMERGE destkey sourcekey [sourcekey …]
将多个 HyperLogLog 合并为一个 HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。 如果你的版本不够的话,直接升级到redis3.0就可以了。
[ root@bj-buzz-docker05:/data/buzzMaster ]$ redis-server -v
Redis server v=2.8.4 sha=00000000:0 malloc=jemalloc-3.4.1 bits=64 build=a44a05d76f06a5d9
sudo apt-get remove redis-server
sudo apt-add-repository ppa:chris-lea/redis-server
sudo apt-get update
sudo apt-get install redis-server
[ root@bj-buzz-docker05:/data/buzzMaster ]$ redis-server -v
Redis server v=3.0.2 sha=00000000:0 malloc=jemalloc-3.6.0 bits=64 build=9a95cedf214a3630
[ root@bj-buzz-docker05:/data/buzzMaster ]$
下面是我在redis-cli的操作HyperLogLog的过程
127.0.0.1:6379> PFADD xiaorui ‘ansbile’
(integer) 1
127.0.0.1:6379> PFADD xiaorui ‘saltstack’
(integer) 1
127.0.0.1:6379> PFADD xiaorui ‘tornado’
(integer) 1
127.0.0.1:6379> PFADD xiaorui ‘python’
(integer) 1
127.0.0.1:6379> PFADD xiaorui ‘js’
(integer) 1
127.0.0.1:6379> PFCOUNT xiaorui
(integer) 5
127.0.0.1:6379> PFADD xiaorui ‘js’
(integer) 0
127.0.0.1:6379> PFCOUNT xiaorui
(integer) 5
127.0.0.1:6379>
为了更好的证明Hyperloglog和set集合的内存使用量对比,我这边用python写了个简单的脚本..
(这里的测试不是很严谨,如果在python的场景下测试,大家可以用python redis的批量接口,然后不要做这种随机串的计算..
import redis
import time
import os
from random import Random
r = redis.Redis(connection_pool=redis.BlockingConnectionPool(max_connections=15, host='127.0.0.1', port=6370))
r.ping()
def random_str(num):
randomlength=num
str = ''
chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789'
length = len(chars) - 1
random = Random()
for i in range(randomlength):
str+=chars[random.randint(0, length)]
return str
def hyperloglog():
start = time.time()
for i in range(1000000):
chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789%s'%(str(i))
r.pfadd('xiaorui.cc',chars)
print time.time()-start
def test_set():
start = time.time()
for i in range(1000000):
chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789%s'%(str(i))
r.sadd('xiaorui.cc',chars)
print time.time()-start
test_set()
插入100w条记录进行测试,value大小在30个字符左右。
HyperLogLog的消耗时间是 135.461647034 (当然这个时间里面,是含有python计算随机字符串的消耗)
redis-cli info信息
# Memory
used_memory:831728
used_memory_human:812.23K
used_memory_rss:7475200
used_memory_peak:831728
used_memory_peak_human:812.23K
used_memory_lua:36864
mem_fragmentation_ratio:8.99
mem_allocator:jemalloc-3.6.0
set的消耗时间是 133.520848989s
# Memory
used_memory:137204320
used_memory_human:130.85M
used_memory_rss:148185088
used_memory_peak:137204320
used_memory_peak_human:130.85M
used_memory_lua:36864
mem_fragmentation_ratio:1.08
mem_allocator:jemalloc-3.6.0
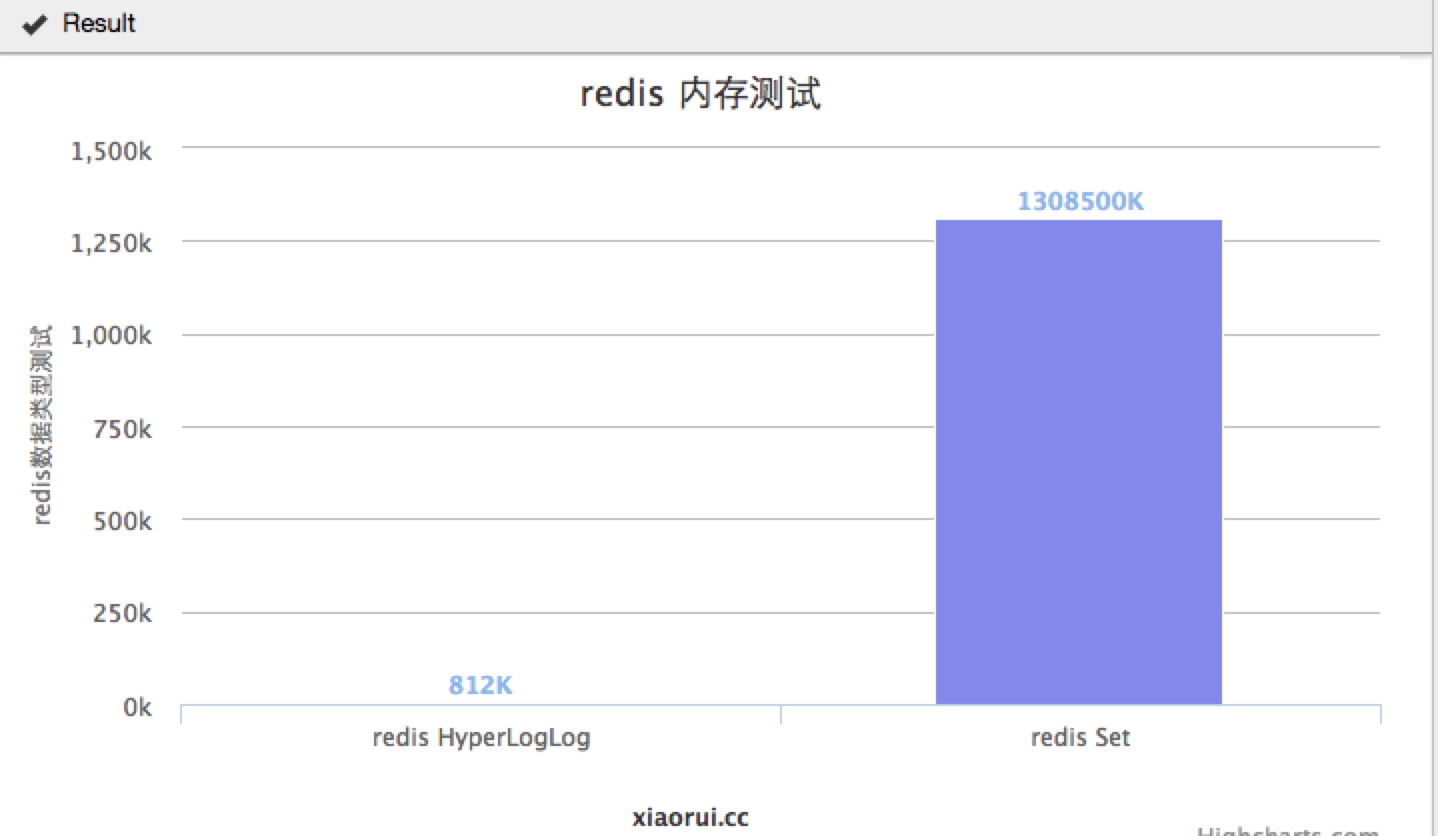
我们曾经在系统中加了层bloomfilter,用来解决各种去重的问题,但是经常会遇到被系统oom的情况… python的bitmap模块不是很稳定,也有内存泄露的情况 另外是对于我们这样的量级,用python来维持这样存有海量数据的结构不是很合理.. 考虑过把bloomfilter用golang或者c独立成一个api服务.. 但这开发毕竟还是有成本…. 最后我们改用了aerospike,用这种分布式的nosql来解决… 经过上面的测试,我们可以看出. redis HyperLogLog 100w条的数据,也才810K,那么1千万,1亿,十几亿? 没有经过大量测试,就不扯淡了…..


很适合做去重