
前言:
celery这东西在任务调度方面,很有一套的,用了他也有几年了,下面就给大家介绍下我以前使用过celery的项目。
Hello ,最近总是被爬虫,标记下博客的原文地址 blog.xiaorui.cc
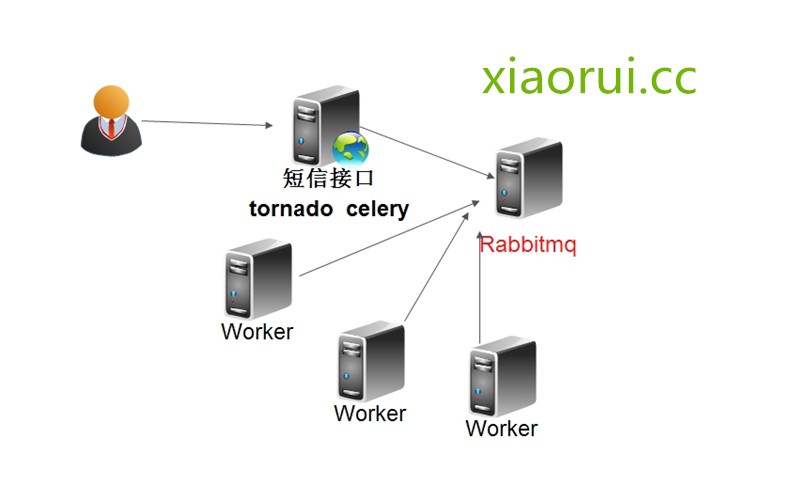
对于上面的场景,我曾经用tornado和gevent的方案解决,但是在我的理解范围下,感觉还是不算成熟。 tornado把任务异步后,总是影响了他的高性能。再说gevent,他是个模拟事件的东西,但是后面由于认识越来越多,有时候因为对调的其他接口不给力,导致我们一下子处理将近1000多个请求,这时候会出现莫名的bug,听说已经有patch解决了。
那么为啥要用celery ?
很简单,就是把堵塞的任务,扔到mq里面,让其他人来搞。搞的定、搞不定都回给你callback信息。
那问题来了 ! 这又和rabbitmq又有啥关系?
和rabbitmq的关系只是在于,celery没有消息存储功能,他需要介质,比如rabbitmq redis mysql mongodb 都是可以的。有这个可控的东西,你也可以在库里面搞搞。推荐使用rabbitmq,他的速度和可用性都很高。如果你想后期方面的处理broker,那还是用redis吧。 redis的语法相对的简单点。
Celery和RabbitMQ是两个层面的东西。
Celery是一个分布式的任务队列。它的基本工作就是管理分配任务到不同的服务器,并且取得结果。至于说服务器之间是如何进行通信的?这个Celery本身不能解决。
所以,RabbitMQ作为一个消息队列管理工具被引入到和Celery集成,负责处理服务器之间的通信任务。
现在的Celery早已增加了一些对Redis,MongoDB之类的支持。原因是RabbitMQ尽管足够强大,但对于一些相对简单的业务环境来说可能太多(复杂)了一些。这样用户可以有多一些的选择。
celery的介绍 :
Celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度支持也很好。
celery是用Python编写的,但该协议可以在任何语言实现。它也可以与其他语言通过webhooks实现。
建议的消息代理RabbitMQ的,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, ,和数据库(使用SQLAlchemy的或Django的 ORM) 。
celery是易于集成Django, Pylons and Flask,使用 django-celery, celery-pylons and Flask-Celery 附加包即可。
安装:
pip install celery
对于消息的存储方案,可以用rabbitmq也可以用redis。 要过任务不是那么要命的话,我个人会用redis,毕竟这东西,学习成本很小的。
yum -y install rabbitmq-server
运行
rabbitmqctl rabbitmq-env rabbitmq-server
停止rabbitmq server的命令是
/usr/local/sbin/rabbitmqctl stop rabbitmqctl rabbitmq-env rabbitmq-server
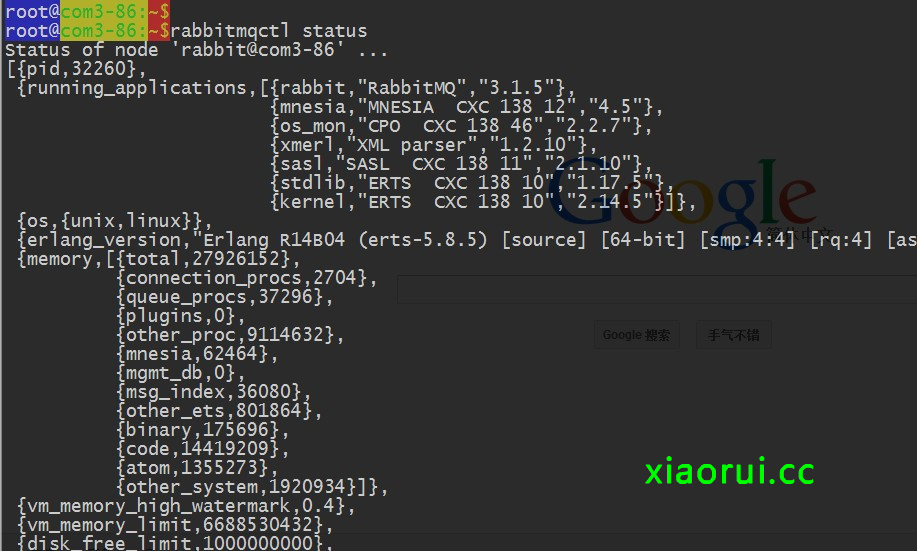
我们可以看看rabbitmq的状态:
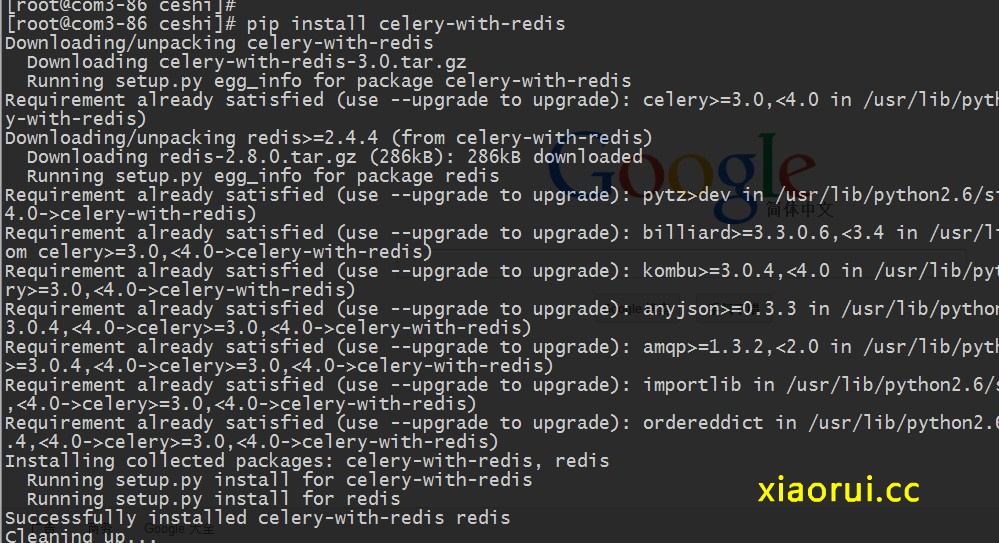
要是喜欢用redis,那就需要安装 celery redis相应的模块 !
celery启动配置文件:
#coding:utf-8
import sys
import os
sys.path.insert(0, os.getcwd())
CELERY_IMPORTS = ("tasks", )
CELERY_RESULT_BACKEND = "amqp"
BROKER_HOST = "localhost"
BROKER_PORT = 5672
BROKER_USER = "guest"
BROKER_PASSWORD = "guest"
BROKER_VHOST = "/"
一个简单的测试,这个模块里面的内容也就是需要异步起来的任务。
from celery.task import task
import time
@task()
def add(x, y):
time.sleep(5)
return x + y
我们来测试下 ~
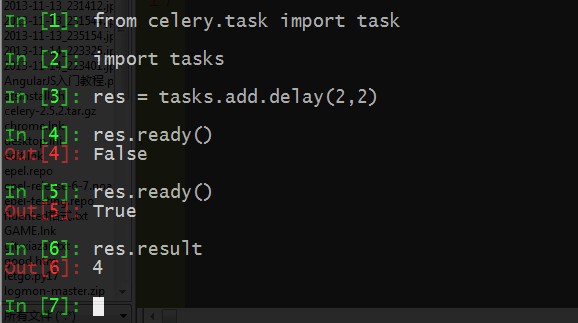
大家有注意那个False吗? 为啥会出现,因为我的tasks.py里面定义了让他sleep 5秒钟,我马上要数据,肯定是没有的,等5秒过了后,我再去提取数据,就可以了。
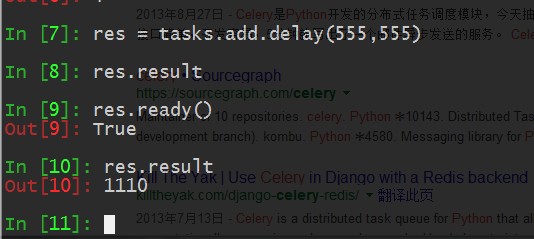
celery的参数众多的 ~
你可以等待结果来完成,但这不是因为它的异步调用同步使用
result.get(timeout=1)
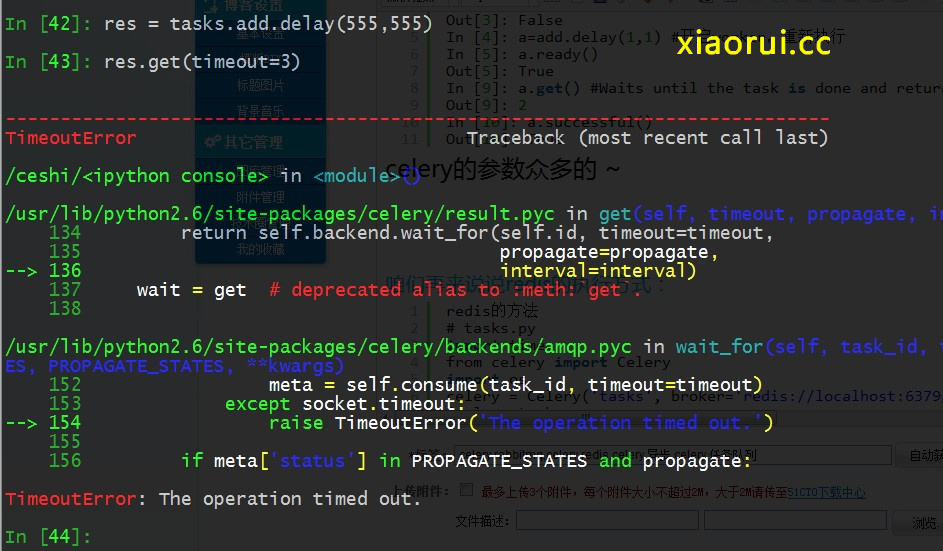
咱们可以让他返回json串
app.conf.update(
CELERY_TASK_SERIALIZER='json',
CELERY_ACCEPT_CONTENT=['json'], # Ignore other content
CELERY_RESULT_SERIALIZER='json',
CELERY_TIMEZONE='Europe/Oslo',
CELERY_ENABLE_UTC=True,
)
咱们再来说说redis的执行方式:
redis的方法
# tasks.py
import time
from celery import Celery
import os
celery = Celery('tasks', broker='redis://localhost:6379/0')
@celery.task
def osrun(good):
reok=os.popen(good).read()
return reok
启动celery
celery -A tasks worker --loglevel=info
总结:
以后有他,我再也不怕堵塞了。但是我对他的理解还是有限,后期再更新下高级方面的功能。

