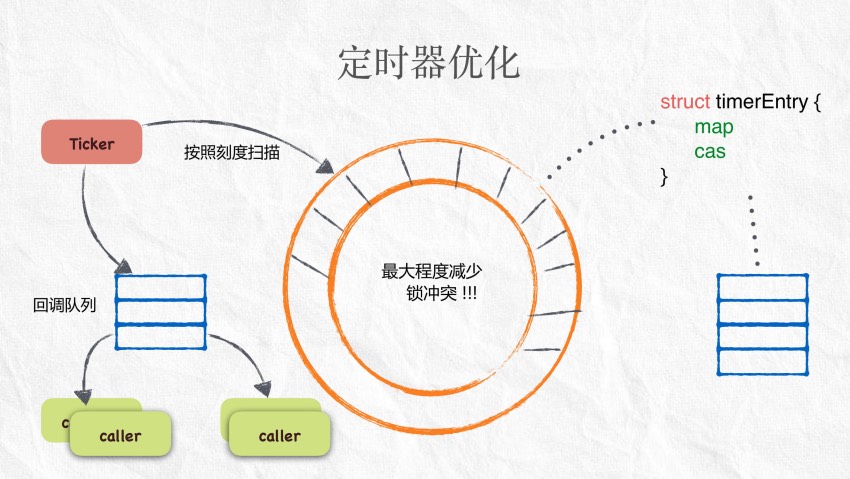
golang 基于 netpoll 优化 timer 定时器实现原理
golang1.14版的release已经发布有些时间了,在官方go1.14的介绍里有说优化了timer定时器。golang的定时器已经经历了几版的优化,但在依赖定时器的高性能场景,还是成为一个大的性能杀手。
看过我曾经做过技术分享的朋友会想到,我一直使用时间轮替换golang标准库中的timer。 想起了一个段子,不是你不够优秀,是哥对定时器的要求太高。
go1.13 和go1.14的区别?
废话不多说,来好好介绍下定时器在go 1.13 和 go1.14中的区别?
golang在1.10版本之前是由一个独立的timerproc通过小顶堆和futexsleep来管理定时任务。1.10之后采用的方案是把独立的timerproc和小顶堆分成最多64个timerproc协程和四叉堆,用来休眠就近时间的方法还是依赖futex timeout机制。默认timerproc数量会跟GOMAXPROCS一致的,但最大也就64个,因为会被64取摸。
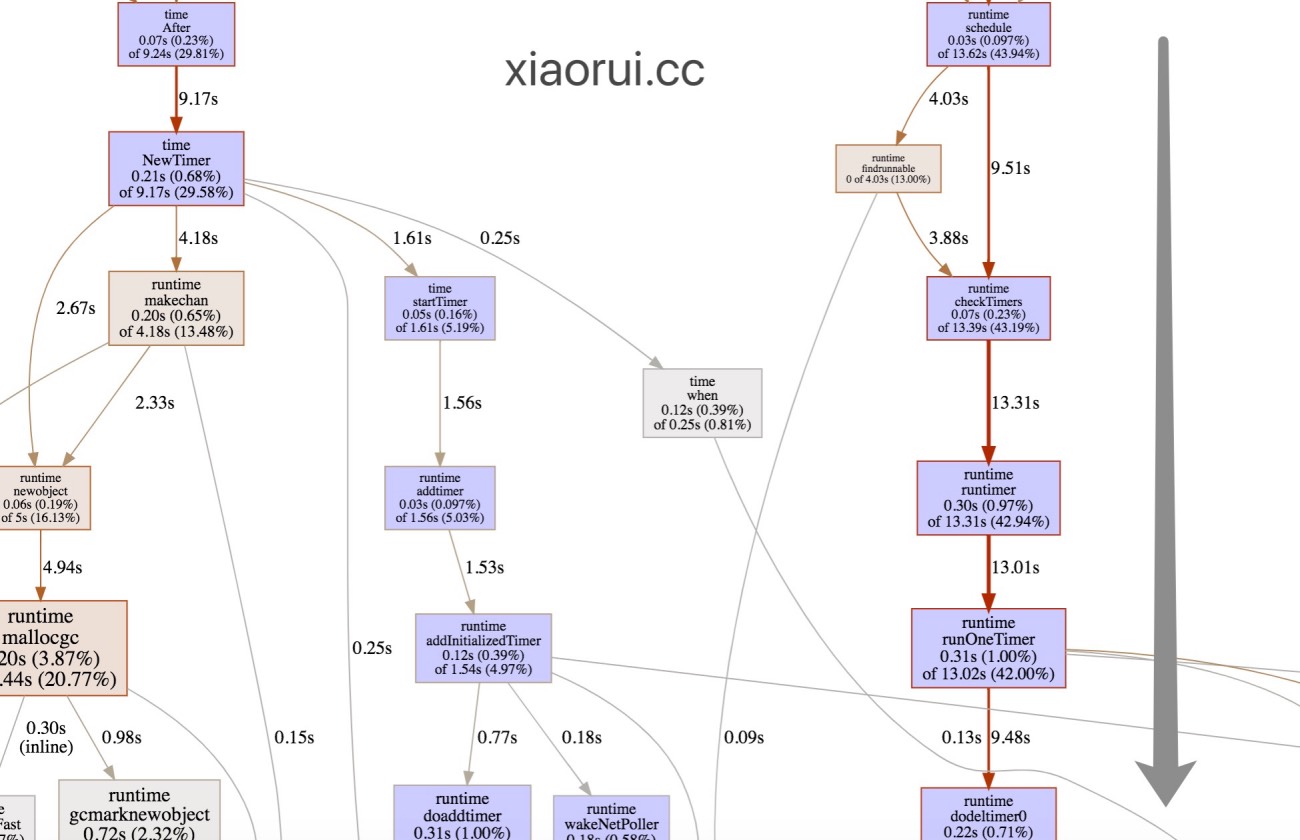
那么简单说go1.14版的timer是如何优化性能?首先把存放定时事件的四叉堆放到p结构中,另外取消了timerproc协程,转而使用netpoll的epoll wait来做就近时间的休眠等待。在每次runtime.schedule调度时都检查运行到期的定时器。
快速浏览go1.13的定时器实现原理
在这里简单的过一遍go1.13版定时器的实现,再细节可以看下我写过的文章。
不管是NewTimer、NewTicker、After等其实调用的都是addTimer来新增定时任务,assignBucket给当前协程分配一个timerBucket。go初始化时会预先实例化长度64的timers数组,通过协程的p跟64取摸来分配timerBucket。如果新的定时任务较新,那么使用notewakeup来激活唤醒timerproc的futex等待。如果发现没有实例化timerproc,则启动。
// xiaorui.cc
const timersLen = 64
var timers [timersLen]struct {
timersBucket
}
func addtimer(t *timer) {
tb := t.assignBucket()
lock(&tb.lock)
ok := tb.addtimerLocked(t)
unlock(&tb.lock)
,,,
}
func (t *timer) assignBucket() *timersBucket {
id := uint8(getg().m.p.ptr().id) % timersLen
t.tb = &timers[id].timersBucket
return t.tb
}
func (tb *timersBucket) addtimerLocked(t *timer) bool {
t.i = len(tb.t)
tb.t = append(tb.t, t)
if !siftupTimer(tb.t, t.i) {
return false
}
if t.i == 0 {
if tb.sleeping && tb.sleepUntil > t.when {
tb.sleeping = false
notewakeup(&tb.waitnote)
}
,,,
if !tb.created {
tb.created = true
go timerproc(tb)
}
}
return true
}
timerproc协程运行时会从堆顶拿timer,然后判断是否到期,到期则直接执行,当bucket无任务时,调用runtime.goparkunlock来休眠该协程。当至少有一个timer任务时,则通过notetsleepg传入下次的到期时间来进行休眠。值得一说的是notetsleepg会调用entersyscallblock触发handoffp,这个问题我们在文章后有说明。
// xiaorui.cc
func timerproc(tb *timersBucket) {
tb.gp = getg()
for {
lock(&tb.lock)
now := nanotime()
delta := int64(-1)
for {
t := tb.t[0]
delta = t.when - now
if delta > 0 {
break
}
arg := t.arg
seq := t.seq
unlock(&tb.lock)
,,,
f(arg, seq)
lock(&tb.lock)
}
if delta < 0 || faketime > 0 {
// No timers left - put goroutine to sleep.
goparkunlock(&tb.lock, waitReasonTimerGoroutineIdle, traceEvGoBlock, 1)
continue
}
}
,,,
tb.sleepUntil = now + delta
unlock(&tb.lock)
notetsleepg(&tb.waitnote, delta)
}
timerproc的notetsleepg用来休眠,addTimerLocked的notewakeup用来唤醒。
// xiaorui.cc
// notetsleepg -> notetsleep_internal -> futexsleep
func futexsleep(addr *uint32, val uint32, ns int64) {
var ts timespec
ts.setNsec(ns)
futex(unsafe.Pointer(addr), _FUTEX_WAIT_PRIVATE, val, unsafe.Pointer(&ts), nil, 0)
}
// notewakeup -> futexwakeup
func futexwakeup(addr *uint32, cnt uint32) {
ret := futex(unsafe.Pointer(addr), _FUTEX_WAKE_PRIVATE, cnt, nil, nil, 0)
,,,
}
源码分析go1.14 timer
在struct p中定义了timer相关字段,timers数组用来做四叉堆数据结构。
// xiaorui.cc
type p struct {
// 保护timers堆读写安全
timersLock mutex
// 存放定时器任务
timers []*timer
,,,
}
定时器timer结构的定义.
// xiaorui.cc
type timer struct {
pp puintptr // p的位置
when int64 // 到期时间
period int64 // 周期时间,适合ticker
f func(interface{}, uintptr) // 回调方法
arg interface{} // 参数
seq uintptr // 序号
nextwhen int64 // 下次的到期时间
status uint32 // 状态
}
如何增加定时任务的?
我们调用NewTimer、After、AfterFunc时会构建runtimeTimer定时结构,然后通过runttime.startTimer来插入到时间堆里。另外在修改,重置定时器的逻辑都会尝试调用wakeNetPoller来唤醒netpoller。
注意,time/sleep.go里的runtimeTimer跟runtime的timer结构是一致的。
// xiaorui.cc
time/sleep.go
func NewTimer(d Duration) *Timer {
c := make(chan Time, 1)
t := &Timer{
C: c,
r: runtimeTimer{
when: when(d),
f: sendTime,
arg: c,
},
}
startTimer(&t.r)
return t
}
func After(d Duration) <-chan Time {
return NewTimer(d).C
}
func AfterFunc(d Duration, f func()) *Timer {
t := &Timer{
r: runtimeTimer{
when: when(d),
f: goFunc,
arg: f,
},
}
startTimer(&t.r)
return t
}
func goFunc(arg interface{}, seq uintptr) {
go arg.(func())()
}
func sendTime(c interface{}, seq uintptr) {
select {
case c.(chan Time) <- Now():
default:
}
}
下面是具体操作定时器添加的过程,time/sleep.go可以理解为应用层定时器的封装,runtime/time.go是定时器调度的封装。
// xiaorui.cc
// 通过link做方法映射,简单说time/sleep.go里调用的time.startTimer其实是runtime包里的。
//go:linkname startTimer time.startTimer
func startTimer(t *timer) {
addtimer(t)
}
// 把定时任务放到当前g关联的P里。
func addtimer(t *timer) {
if t.when < 0 {
t.when = maxWhen
}
t.status = timerWaiting // 状态为等待中
addInitializedTimer(t)
}
// 加锁来清理任务,并且增加定时任务,最后根据时间就近来唤醒netpoll
func addInitializedTimer(t *timer) {
when := t.when
pp := getg().m.p.ptr()
lock(&pp.timersLock)
ok := cleantimers(pp) && doaddtimer(pp, t)
unlock(&pp.timersLock)
if !ok {
badTimer()
}
wakeNetPoller(when)
}
当新添加的定时任务when小于netpoll等待的时间,那么wakeNetPoller会激活NetPoll的等待。激活的方法很简单,在findrunnable里的最后会使用超时阻塞的方法调用epollwait,这样既可监控了epfd红黑树上的fd,又可兼顾最近的定时任务的等待。
// xiaorui.cc
var (
epfd int32 = -1 // epoll descriptor
netpollBreakRd, netpollBreakWr uintptr // 用来给netpoll中断
)
// 初始化全局的epfd及break的两个读写管道
func netpollinit() {
epfd = epollcreate1(_EPOLL_CLOEXEC)
,,,
r, w, errno := nonblockingPipe() // r为管道的读端,w为写端
,,,
errno = epollctl(epfd, _EPOLL_CTL_ADD, r, &ev) // 把管道的r端加到epfd里进行监听
,,,
netpollBreakRd = uintptr(r)
netpollBreakWr = uintptr(w)
}
// 唤醒正在netpoll休眠的线程,前提是when的值小于pollUntil时间。
func wakeNetPoller(when int64) {
if atomic.Load64(&sched.lastpoll) == 0 {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > when {
netpollBreak()
}
}
}
// netpollBreakWr是一个管道,用write给netpollBreakWr写数据,这样netpoll自然就可被唤醒。
func netpollBreak() {
for {
var b byte
n := write(netpollBreakWr, unsafe.Pointer(&b), 1)
if n == 1 {
break
}
if n == -_EINTR {
continue
}
if n == -_EAGAIN {
return
}
println("runtime: netpollBreak write failed with", -n)
throw("runtime: netpollBreak write failed")
}
}
增加和修改的逻辑大同小异,但是删除不一样,删除更多的是标记timer结构中的status为timerDeleted状态。
// xiaorui.cc
// time/sleep.go的stopTimer用的是runtime.stopTimer方法
//go:linkname stopTimer time.stopTimer
func stopTimer(t *timer) bool {
return deltimer(t)
}
func deltimer(t *timer) bool {
for {
switch s := atomic.Load(&t.status); s {
case timerWaiting, timerModifiedLater:
// 原子更新为删除
if atomic.Cas(&t.status, s, timerDeleted) {
atomic.Xadd(&tpp.deletedTimers, 1)
return true
}
,,,
// 已经被删除
case timerDeleted, timerRemoving, timerRemoved:
return false
,,,
// runtime/proc.go checkTimers -> runtime/time.go runtimer
func runtimer(pp *p, now int64) int64 {
for {
t := pp.timers[0]
,,,
switch s := atomic.Load(&t.status); s {
case timerWaiting:
runOneTimer(p, t, now) // 执行
case timerDeleted:
continue
,,,
}
}
下面是检测和执行定时器的入口
第一,通过findrunnable找任务时会检查timer事件。函数刚开始时会使用checkTimers检测运行本p的定时任务,后面再偷任务时不仅偷其他p的runq,而且还偷其他p到期的timers,具体使用的是checkTimers方法。
// xiaorui.cc
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
// 检测运行本p的定时任务
now, pollUntil, _ := checkTimers(_p_, 0)
// 从本p中获取goroutine
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 从全局p中获取goroutine
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 非阻塞的轮询网络事件
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list) // 把被唤醒跟fd关联的goroutine放到runq里。
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// 尝试4次轮。先从其他的p的runq偷,再从其他p的timers偷.
procs := uint32(gomaxprocs)
for i := 0; i < 4; i++ {
// 尽量规避p的锁竞争,随机访问所有的p。
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
// 偷其他p的runq
if gp := runqsteal(_p_, p2, stealRunNextG); gp != nil {
return gp, false
}
// 继续偷其他p的timers
if i > 2 && shouldStealTimers(p2) {
tnow, w, ran := checkTimers(p2, now) // 执行已经到期的定时任务
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w // 这个是重点 !!!
}
}
}
}
delta := int64(-1)
if pollUntil != 0 {
delta = pollUntil - now // 距离当前时间最近的时间点的时间差。
}
// 带超时的netpoll阻塞调用
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
list := netpoll(delta) // block until new work is available
,,,
}
}
netpoll这里分为阻塞和非阻塞方法,当delay小于则是阻塞模式,等于0为非阻塞模式,大于0是超时模式。delay的时间为纳秒,epoll wait的超时时间单位为毫秒,为了避免过度的系统调用,做了一些粒度上的合并。
另外,golang为了尽量规避epoll的惊群问题,所以同一时间只会有一个协程陷入epoll wait休眠。
// xiaorui.cc
// netpoll checks for ready network connections.
// Returns list of goroutines that become runnable.
// delay < 0: blocks indefinitely
// delay == 0: does not block, just polls
// delay > 0: block for up to that many nanoseconds
func netpoll(delay int64) gList {
if epfd == -1 { // epfd为全局对象,netpollinit时就会初始化
return gList{}
}
var waitms int32
if delay < 0 {
waitms = -1
} else if delay == 0 {
waitms = 0
} else if delay < 1e6 { // 1ms
waitms = 1
} else if delay < 1e15 { // 11.574 天
waitms = int32(delay / 1e6) // 最大 1s
} else {
// An arbitrary cap on how long to wait for a timer.
// 1e9 ms == ~11.5 days.
waitms = 1e9 // 1s
}
var events [128]epollevent
retry:
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
,,,
for i := int32(0); i < n; i++ {
,,,
// 如果fd为用来中断的netpollBreakRd则continue。
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
var tmp [16]byte
read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp)))
}
continue
}
,,,
}
epollwait函数的实现是汇编。
// xiaorui.cc
// int32 runtime·epollwait(int32 epfd, EpollEvent *ev, int32 nev, int32 timeout);
TEXT runtime·epollwait(SB),NOSPLIT,0
MOVL epfd+0(FP), DI
MOVQ ev+8(FP), SI
MOVL nev+16(FP), DX
MOVL timeout+20(FP), R10
MOVQ0, R8
MOVL $SYS_epoll_pwait, AX
SYSCALL
MOVL AX, ret+24(FP)
RET
第二,在go runtime的pmg调度模型下,当一个m执行完一个G的协程调度后,调用runtime.schedule方法来寻找可用的goroutine并执行。这里关键的方法也是checkTimers。
// xiaorui.cc
func schedule() {
,,,
pp := _g_.m.p.ptr()
checkTimers(pp, 0)
,,,
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
,,,
}
那么checkTimers是做什么的?
checkTimers该函数只检查传递进来的p,通过runtimer来运行到期的定时任务,并且返回下一次到期的时间及是否有定时任务到期。
// xiaorui.cc
func checkTimers(pp *p, now int64) (rnow, pollUntil int64, ran bool) {
...
lock(&pp.timersLock)
rnow = now
if len(pp.timers) > 0 {
if rnow == 0 {
rnow = nanotime()
}
for len(pp.timers) > 0 {
// 尝试执行任务
if tw := runtimer(pp, rnow); tw != 0 {
if tw > 0 {
pollUntil = tw
}
break
}
ran = true
}
}
unlock(&pp.timersLock)
return rnow, pollUntil, ran
}
runtimer遍历堆顶的任务时间是否到期,如到期回调执行,如是周期性会重新。
// xiaorui.cc
//go:systemstack
func runtimer(pp *p, now int64) int64 {
for {
t := pp.timers[0] // 获取四叉堆的堆顶
,,,
switch s := atomic.Load(&t.status); s {
case timerWaiting:
if t.when > now {
// Not ready to run.
return t.when
}
// 原子修改定时任务的状态
if !atomic.Cas(&t.status, s, timerRunning) {
continue
}
runOneTimer(pp, t, now)
return 0
,,,
// 直接执行该定时任务,如果是周期性任务会重新入队。
func runOneTimer(pp *p, t *timer, now int64) {
(...)
f := t.f
arg := t.arg
seq := t.seq
// 如果是 period > 0 则说明此时 timer 为 ticker,需要再次触发
if t.period > 0 {
delta := t.when - now
t.when += t.period * (1 + -delta/t.period)
if !siftdownTimer(pp.timers, 0) { // 调整堆
panic(...)
}
// 原子重置状态为tiemrWaiting
if !atomic.Cas(&t.status, timerRunning, timerWaiting) {
panic(...)
}
} else { // 否则为一次性 timer
// 从堆中移除
if !dodeltimer0(pp) {
panic(...)
}
if !atomic.Cas(&t.status, timerRunning, timerNoStatus) {
panic(...)
}
}
,,,
unlock(&pp.timersLock)
f(arg, seq) // 回调执行定时任务中的方法
lock(&pp.timersLock)
,,,
}
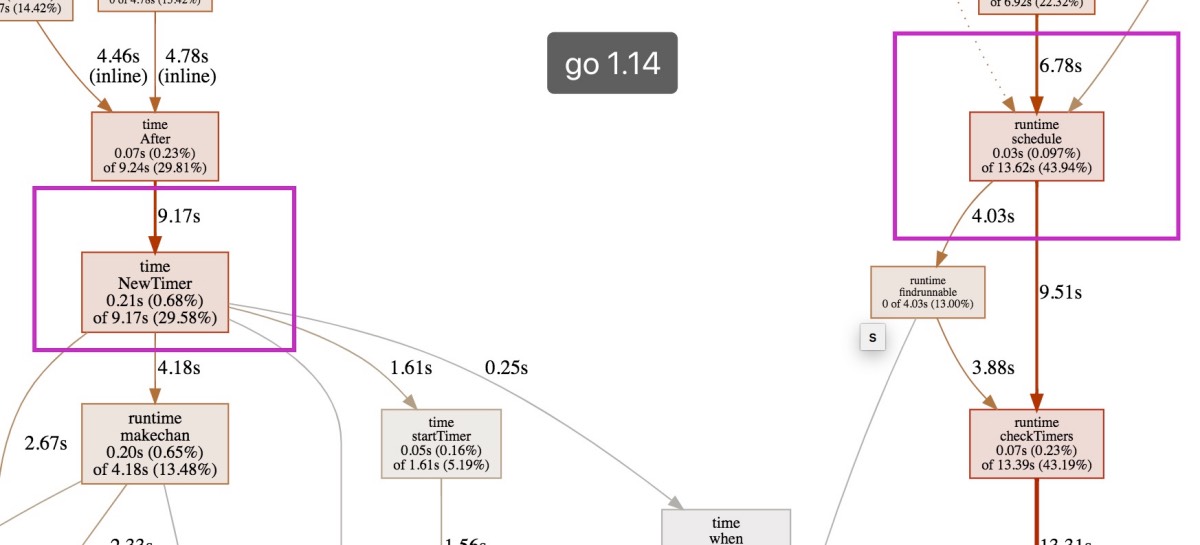
借用go pprof的图可以明显的跟踪定时函数的调用过程。
通过strace分析go1.14的变化
写个脚本大量的创建周期较长的定时器,但每组新的定时器要比上次小,最小的等待时间为5秒。
下面是go1.13定时器的表现,通过strace可以看到空闲期出现多个线程挂在futex系统调用上。futex主要有两个flag,FUTEX_WAIT_PRIVATE为休眠,FUTEX_WAIT_PRIVATE为唤醒,futex的第四个参数为超时时间。
// xiaorui.cc
[pid 21518] 09:14:34 futex(0xc0000ba4c8, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
[pid 21517] 09:14:34 futex(0xc00033a4c8, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
[pid 21516] 09:14:34 futex(0xc0000aa4c8, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
[pid 21496] 09:14:34 futex(0x96bb20, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
[pid 21493] 09:14:34 futex(0x96bb40, FUTEX_WAIT_PRIVATE, 0, {4, 939313694} <unfinished ...>
[pid 21496] 09:14:34 <... futex resumed> ) = 0 <0.000021>
[pid 21496] 09:14:34 futex(0xc0000ba148, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
// 等待了将近5秒后被唤醒.
[pid 21491] 09:14:34 futex(0x967d30, FUTEX_WAIT_PRIVATE, 0, {60, 0} <unfinished ...>
[pid 21493] 09:14:39 futex(0x967d30, FUTEX_WAKE_PRIVATE, 1) = 1 <0.000013>
[pid 21491] 09:14:39 <... futex resumed> ) = 0 <4.937629>
[pid 21493] 09:14:39 futex(0xc0000ba148, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
[pid 21496] 09:14:39 <... futex resumed> ) = 0 <4.939627>
[pid 21493] 09:14:39 futex(0xc0000aa4c8, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
[pid 21516] 09:14:39 <... futex resumed> ) = 0 <4.939849>
下面是go1.14的定时器表现,可以看到只有一个线程陷入epoll_pwait超时休眠,epoll wait的时间单位是毫秒,那么4877将近5s。
// xiaorui.cc
[pid 22039] 09:16:42 epoll_pwait(3, {{EPOLLIN, {u32=10005312, u64=10005312}}}, 128, 4877, NULL) = 1 <0.000004>
// 等待了5s ...
[pid 22039] 09:16:47 <... epoll_pwait resumed> {}, 128, 4876, NULL) = 0 <4.877084>
[pid 22039] 09:16:47 epoll_pwait(3, <unfinished ...>
[pid 22039] 09:16:47 <... epoll_pwait resumed> {}, 128, 0, NULL) = 0 <0.000029>
[pid 22040] 09:16:47 epoll_pwait(3, <unfinished ...>
go1.14性能优化
性能怎么就提高了?
锁竞争冲突减少?go1.14虽然把timers放到了p结构中,但本p操作堆依然也需要加锁。因为1.14的findrunnable方法会偷其他p的timers任务,为了写安全必然是加锁的。另外,1.13的锁的粒度范围跟1.14是差不多的,每个timerproc有指定的timers和lock,最大拆分64。可以想象操作timers结构的锁貌似没减少。
但问题来了,go1.13会有更多的线程去处理timerproc操作notetsleepg,继而引发entersyscallblock调用,该方法会主动解绑handoffp。那么当下一个定时事件到来时,又尝试去pmg绑定,绑定时有涉及到sched.lock锁。
通过下面的系统调用统计数据来看,go1.13不单是futex百分比大,而且还相当的耗时。
// xiaorui.cc
go1.13
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
84.00 12.007993 459 26148 3874 futex
11.43 1.634512 146 11180 nanosleep
4.45 0.635987 32 20185 sched_yield
go1.14
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
58.78 4.837332 174 27770 4662 futex
19.50 1.605189 440 3646 nanosleep
11.55 0.950730 44 21569 epoll_pwait
9.75 0.802715 36 22181 sched_yield
runtime调度开销?go1.13最多可以开到GOMAXPROCS数量的timerproc协程,当然不超过64。但我们要知道timerproc自身就是协程,也需要runtime pmg的调度。反而go 1.14把检查到期定时任务的工作交给了runtime.schedule,不需要额外的调度,每次runtime.schedule和findrunable时直接运行到期的定时任务。
线程上下文切换开销?新添加的定时任务的到期时间更小时,不管是使用futex还是epoll_wait系统调用都会被唤醒重新休眠,被唤醒的线程会产生上下文切换。但由于go1.14没有timerproc的存在,新定时任务可直接插入或多次插入后再考虑是否休眠。
结论,golang 1.13的定时器在任务繁多时,必然会造成更多的上线文切换及runtime pmg调度,而golang 1.14做了更好的优化。
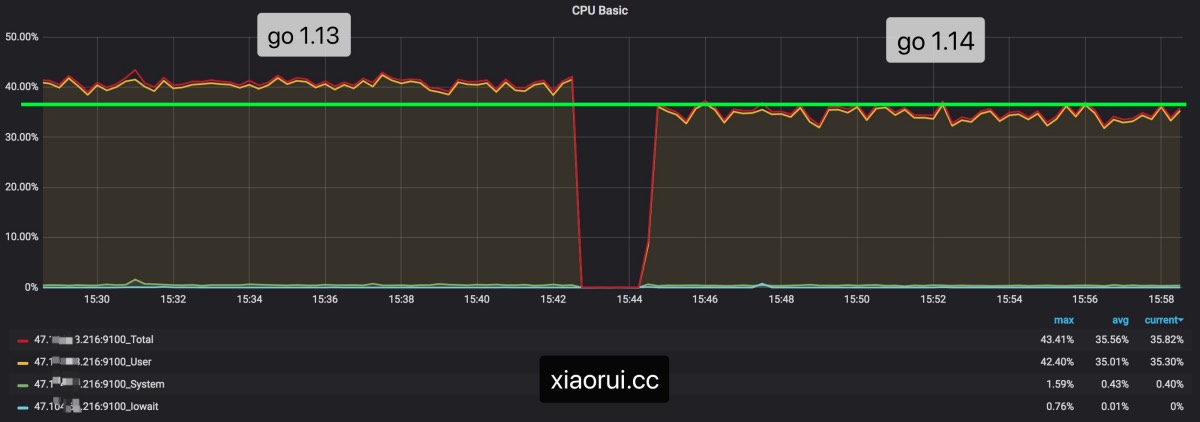
通过prometheus监控可以看到两个版本cpu的使用率对比,go1.14要比go1.13是节省了一些资源。
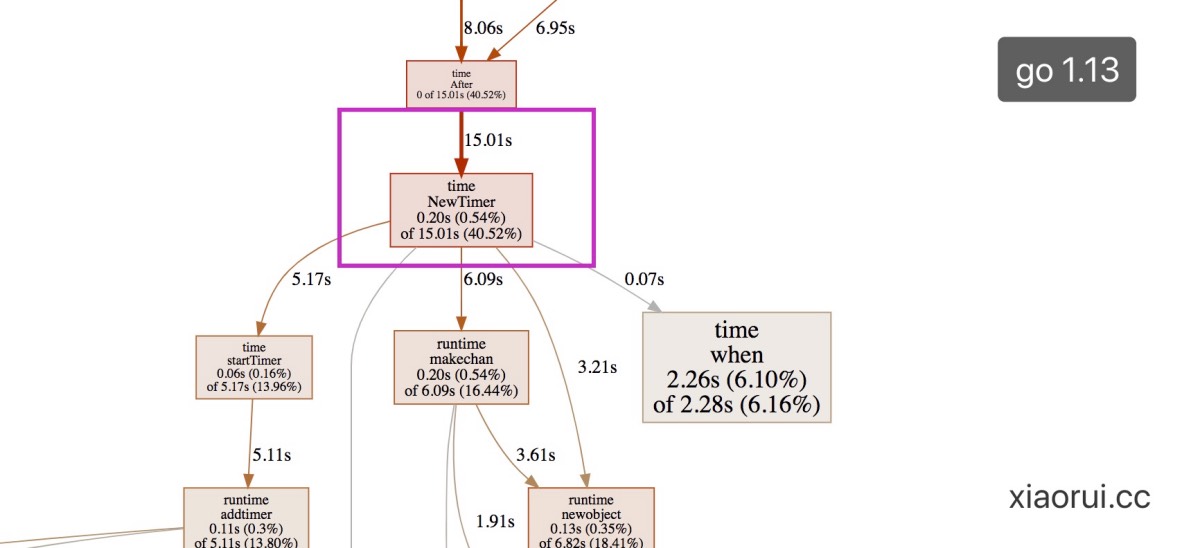
加入go tool pprof的性能表现,可以看到新任务的添加确实快了。
1.13
1.14
1.13 vs 1.14性能对比?
这是官方给出的go1.14 vs 1.13定时器性能测试,看结果随着gomaxprocs的增多,性能表现也越来越好。 官方没有提供完整的测试方法。
https://github.com/golang/go/commit/76f4fd8a5251b4f63ea14a3c1e2fe2e78eb74f81
Below are relevant benchmark results for various GOMAXPROCS values
on linux/amd64:
context package:
name old time/op new time/op delta
WithTimeout/concurrency=40 4.92µs ± 0% 5.17µs ± 1% +5.07% (p=0.000 n=9+9)
WithTimeout/concurrency=4000 6.03µs ± 1% 6.49µs ± 0% +7.63% (p=0.000 n=8+10)
WithTimeout/concurrency=400000 8.58µs ± 7% 9.02µs ± 4% +5.02% (p=0.019 n=10+10)
name old time/op new time/op delta
WithTimeout/concurrency=40-2 3.70µs ± 1% 2.78µs ± 4% -24.90% (p=0.000 n=8+9)
WithTimeout/concurrency=4000-2 4.49µs ± 4% 3.67µs ± 5% -18.26% (p=0.000 n=10+10)
WithTimeout/concurrency=400000-2 6.16µs ±10% 5.15µs ±13% -16.30% (p=0.000 n=10+10)
name old time/op new time/op delta
WithTimeout/concurrency=40-4 3.58µs ± 1% 2.64µs ± 2% -26.13% (p=0.000 n=9+10)
WithTimeout/concurrency=4000-4 4.17µs ± 0% 3.32µs ± 1% -20.36% (p=0.000 n=10+10)
WithTimeout/concurrency=400000-4 5.57µs ± 9% 4.83µs ±10% -13.27% (p=0.001 n=10+10)
time package:
name old time/op new time/op delta
AfterFunc 6.15ms ± 3% 6.07ms ± 2% ~ (p=0.133 n=10+9)
AfterFunc-2 3.43ms ± 1% 3.56ms ± 1% +3.91% (p=0.000 n=10+9)
AfterFunc-4 5.04ms ± 2% 2.36ms ± 0% -53.20% (p=0.000 n=10+9)
After 6.54ms ± 2% 6.49ms ± 3% ~ (p=0.393 n=10+10)
After-2 3.68ms ± 1% 3.87ms ± 0% +5.14% (p=0.000 n=9+9)
After-4 6.66ms ± 1% 2.87ms ± 1% -56.89% (p=0.000 n=10+10)
Stop 698µs ± 2% 689µs ± 1% -1.26% (p=0.011 n=10+10)
Stop-2 729µs ± 2% 434µs ± 3% -40.49% (p=0.000 n=10+10)
Stop-4 837µs ± 3% 333µs ± 2% -60.20% (p=0.000 n=10+10)
SimultaneousAfterFunc 694µs ± 1% 692µs ± 7% ~ (p=0.481 n=10+10)
SimultaneousAfterFunc-2 714µs ± 3% 569µs ± 2% -20.33% (p=0.000 n=10+10)
SimultaneousAfterFunc-4 782µs ± 2% 386µs ± 2% -50.67% (p=0.000 n=10+10)
StartStop 267µs ± 3% 274µs ± 0% +2.64% (p=0.000 n=8+9)
StartStop-2 238µs ± 2% 140µs ± 3% -40.95% (p=0.000 n=10+8)
StartStop-4 320µs ± 1% 125µs ± 1% -61.02% (p=0.000 n=9+9)
Reset 75.0µs ± 1% 77.5µs ± 2% +3.38% (p=0.000 n=10+10)
Reset-2 150µs ± 2% 40µs ± 5% -73.09% (p=0.000 n=10+9)
Reset-4 226µs ± 1% 33µs ± 1% -85.42% (p=0.000 n=10+10)
Sleep 857µs ± 6% 878µs ± 9% ~ (p=0.079 n=10+9)
Sleep-2 617µs ± 4% 585µs ± 2% -5.21% (p=0.000 n=10+10)
Sleep-4 689µs ± 3% 465µs ± 4% -32.53% (p=0.000 n=10+10)
Ticker 55.9ms ± 2% 55.9ms ± 2% ~ (p=0.971 n=10+10)
Ticker-2 28.7ms ± 2% 28.1ms ± 1% -2.06% (p=0.000 n=10+10)
Ticker-4 14.6ms ± 0% 13.6ms ± 1% -6.80% (p=0.000 n=9+10)
总结:
go1.14的定时器虽然做了不少性能优化,让这个所谓的性能杀手也得以”喘息”,但从设计模型上来说,还是跟粗精度的时间轮有性能差距。