
前言:
redis5.0发布了,在我看来这次最大的更新应该就是stream数据结构了。
简单说 redis stream 是干嘛的? stream是一个看起来比pubsub更可靠的消息队列。pubsub不靠谱? 很不靠谱,网络一断或buffer一大就会主动清理数据。stream的设计参考了kafka的消费组模型,redis作者antirez也专门写了篇短文说了这件事。
话说这个redis streams有些意思,其实Antirez在几年前开了一个新项目叫做disque, 也是用来做消息队列的,奈何没怎么有人关注。我作为antirez的粉丝,肯定是用过了,还tmd改过disque python的库。现在redis5的stream里有一些disque的影子。 更多streams的信息 https://redis.io/topics/streams-intro
在尝试用redis5.0 stream的时候,遇到了两个小bug, 一个还没提交就被修复了, 另一个issue是xdel删除消息id后,xlen的值没有变化的问题,git issue https://github.com/antirez/redis/issues/4989
该文章后续仍在不断的更新修改中, 请移步到原文地址 http://xiaorui.cc/?p=5285
redis stream 的设计思路
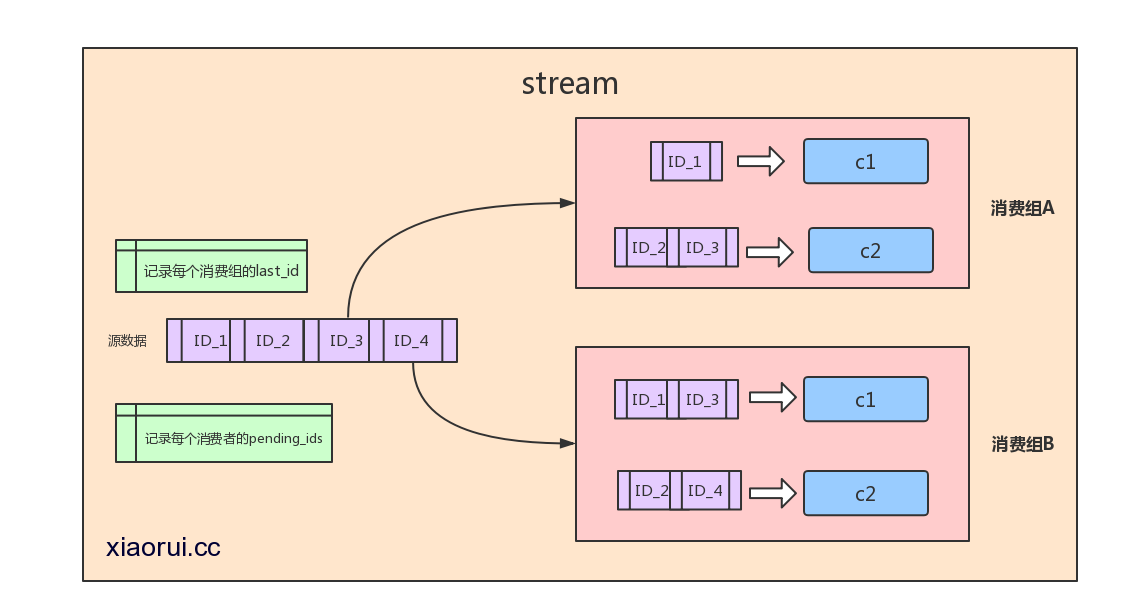
用过kafka的人再看这图就很好理解了。源数据用来存放stream数据,数据是按照有seq_id序排列的。 redis会记录stream里每个消费组最后消费的last_id及还没有返回ack确认的id数据。每个消费组都有一个last_id, 也就是说 每个消费组都可以消费同一条数据,每个消费组里可以有多个消费者,多个消费组的关系是相互竞争的。
比如同一条数据,a系统会用,b系统也会用到,那么这时候要用消费组了。 a系统如果只有一个消费者会造成吞吐不够的情况,redis stream consumer group可以在同一个消费组里有多个消费者,consumer消费者多了,吞吐自己就上来了。 redis stream是可以保证这些操作原子性的。
stream又维护了一个pending_ids的数据,他的作用是维护消费者的未确认的id,比如消费者get了数据,但是返回给你的时候网络异常了,crash了,又比如消费者收到了,但是crash掉了? redis stream维护了这些没有xack的id. 我们可以xpending来遍历这些数据,xpending是有时间信息的,我们可以在代码层过滤一个小时之前还未xack的id。
简单粗暴测试:
第一步,插入数据 stm是streams的key, * 代表的是redis帮生成序列id, stream的一条记录可以有多个字段及值,所以后面跟了 url和typo.
# xiaorui.cc
xadd stm * url xiaorui.cc typo 1
xadd stm * url xiaorui.cc typo 2
xadd stm * url xiaorui.cc typo 3
xadd stm * url xiaorui.cc typo 4
xadd stm * url xiaorui.cc typo 5
xadd stm * url xiaorui.cc typo 6
xadd stm * url xiaorui.cc typo 7
xadd stm * url xiaorui.cc typo 8
xadd stm * url xiaorui.cc typo 9
xadd stm * url xiaorui.cc typo 10第二步, 查询最小到最大的数据,- 是最小,+ 是最大
127.0.0.1:6379> xrange stm - +
1) 1) 1528271957975-0
2) 1) "url"
2) "xiaorui.cc"
3) "typo"
4) "1"
2) 1) 1528271958716-0
2) 1) "url"
2) "xiaorui.cc"
3) "typo"
4) "2"
....
....
....第三步,创建一个消费组
127.0.0.1:6379> xgroup create stm cg1 0-0
OK第四步,创建一个消费者并且消费
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams stm >
1) 1) "stm"
2) 1) 1) 1528271957975-0
2) 1) "url"
2) "xiaorui.cc"
3) "typo"
4) "1"第五步,查看redis里的stream消费状态, 可以看到当前只有一个消费者c1, pending状态的id只有一个。
127.0.0.1:6379> xinfo groups stm
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1
5) pending
6) (integer) 1
127.0.0.1:6379> xinfo consumers stm cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 1
5) idle
6) (integer) 46018第六步,使用xack来确认该消息id,之后我们在通过xinfo groups发现pending为0了。
127.0.0.1:6379> xack stm cg1 1528271957975-0
(integer) 1
127.0.0.1:6379> xinfo groups stm
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1
5) pending
6) (integer) 0上面说了基本的用法,我们再试试在一个consumer group里,多个消费者并发去消费请求会出现了什么?
# xiaorui.cc
127.0.0.1:6379> xreadgroup GROUP cg1 c2 count 1 streams stm >
1) 1) "stm"
2) 1) 1) 1528271958716-0
2) 1) "url"
2) "xiaorui.cc"
3) "typo"
4) "2"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams stm >
1) 1) "stm"
2) 1) 1) 1528271960027-0
2) 1) "url"
2) "xiaorui.cc"
3) "typo"
4) "3"通过上面的result可以看到,两个消费者不会消费到同一个消息id, ‘ > ‘ 表示从当前消费组的last_delivered_id后面开始读, 每当消费者读取一条消息,last_delivered_id变量就会前进. 这个get消息和set偏移量的过程是原子的,redis会帮你保证该组合指令的原子性。
既然是消费队列,当消费端没有数据的时候,肯定不能忙轮询吧 ? 所以说redis streams也支持类似long poll事件唤醒机制。 block 0 等于一直等待读事件,block 10 等待10s的意思。
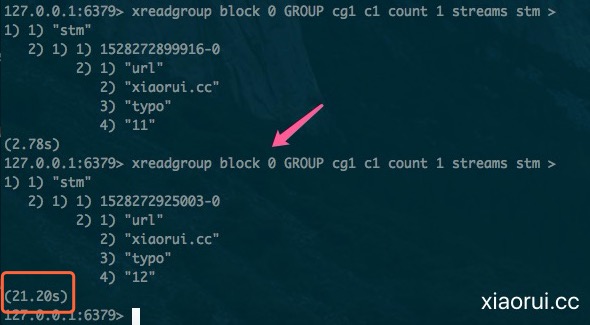
redis5 stream靠谱不?
在5.0的分支里没有找到关于streams的redis-benchmark的测试。另外 5.0 放出来的版本身就是个beta版,可以先试用下。redis stream现在还少了几个功能,比如删除消费组,删除消费者,手动重新设置last_id ! 可以看到t_stream.c里有几个方法还是空着。

stream适用于允许丢失数据的业务场景,因为redis本身是不支持数据的绝对可靠的,哪怕aof调成always, 在crash后也会丢失一两条。因为写aof日志不是同步写入的。 性能和可靠性很难兼得。
现在Redis server 5.0出beta了,但是各个语言的客户端还没有开发stream的方法, 最少python和golang还没有。
>>> r.xadd
Traceback (most recent call last):
File "<input>", line 1, in <module>
r.xadd
AttributeError: 'Redis' object has no attribute 'xadd'当然,你可以使用各个语言redis库自带的命令模式。比如,python的execute_command()方法。
>>> r.execute_command("xadd", "stm", "*", "url", "xiaorui.cc", "typo", "13")
'1528274402382-0stream如何清理数据?
直接全部删除
DEL stream key通过strim来删除和限制最大条目.
XTRIM stm maxlen 2最多只保留10条数据在stream里面
XADD stm MAXLEN 10 * url xiaorui.cc typo 100删除一个消息从stream里
XDEL stm 1528274353972-0总结:
有点好奇stream在redis cluster里表现如何,给我感觉要成big key的感觉。过两天写一篇关于stream源码分析

