
上下文环境
先废话连篇,老生常谈说下Thrift 是什么? 他是个功能强大的通信协议组件,附带了各级socket服务,自成RPC服务. 我们知道大多数所谓的RPC远程调用服务都是基于http来开发的,为毛? 因为够简单呀。 对于server端 和 客户端来说,我只需要把函数名及参数序列化扔到对端就可以了。
那么http和tcp封装rpc最大的区别在于什么?
开发难度, 使用直接tcp server需要考虑粘包的问题,还要自定义通信协议。 HTTP明显开发简单的多,高性能的框架选择余地也贼多,只是http协议在RPC场景下显得有些冗余了。 当然你可以自己裁剪下http协议.
工作到现在以来,我自己开发的高性能rpc就有两个,也写过rpc的文章。 我这么喜欢造轮子的人,为什么会选用通用的thrift做协议层. 这次要重构一个调度模块,因为不仅仅是python来访问你,还有其他语言来调用,所以这个时候就不好再用自己造的轮子了, 难不成我还要画心思告诉别人RPC的客户端怎么写?协议各方面需要注意什么? 算了吧, 我还是用 thrift协议来兼容各个语言的通信吧。
我这边其实有用过thrift的服务,比如 Hbase的thrift server,监控系统。 说实话这性能,我始终不是很满意,我们每天也就几千万的量,虽然每条的数据在200KB左右。 其实归根到底不是Thrift不行,而是他默认的几个IO服务模型不给力。 像 Hbase Thrfit Server使用的就是BIO阻塞模式,只能开更多的线程来接客 ….
我曾经测试过thrift的nio模型,nio是java的New io, 最后的结果还是可以的,单机可以抗住 3W 的请求量 . 不管怎么说,正好也没有写过thrift的文章, 趁着有点时间,跟大家聊聊。
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新.
Thrift有简洁的四层接口抽象,每一层都可以独立的扩展增强或替换. 如果你有定制的需求,可以直接在现存的thrift框架上修改. 比如我很想把thrift的server改成multiprocessing gevent模式.
下图是thrift的结构图:
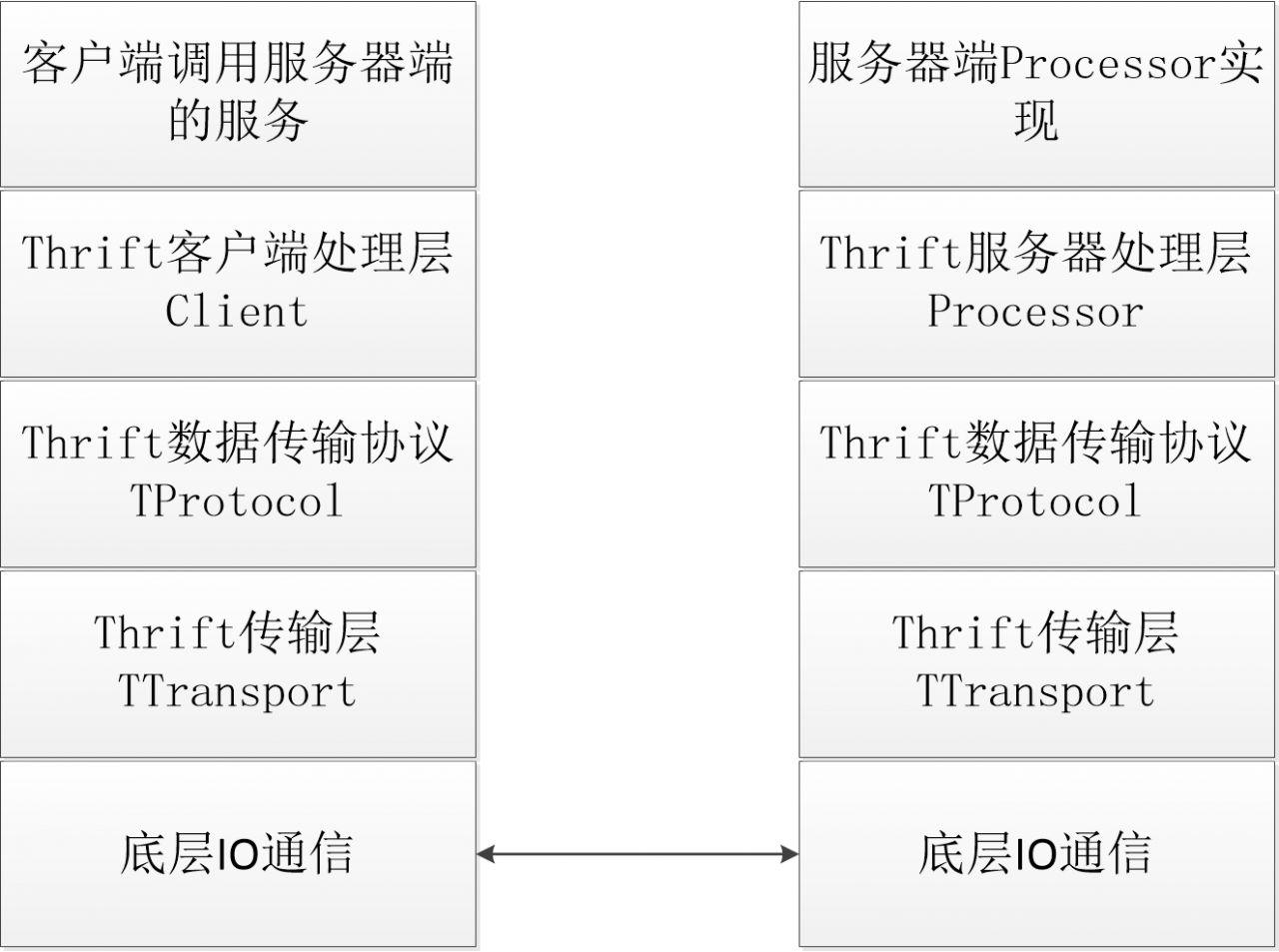
我们先说下thrift的通信协议,有下面这么几种.
#xiaorui.cc TBinaryProtocol 二进制传输协议 TCompactProtocol 使用VLQ编码进行压缩的数据传输协议 TJSONProtocol JSON格式的数据传输协议 TSimpleJSONProtocol 简单的JSON格式数据传输协议 TDebugProtocol 调试时使用的文本传输协议
再来看看thrift的通信方式.
TFramedTransport 按块的大小进行传输 TFileTransport 按照文件的方式进行传输 TMemoryTransport 使用内存IO方式进行传输 TZlibTransport 执行zlib压缩方式传输
我们这次不讲thrift的使用方法,有需要的朋友直接看官方的实例,这次主要通过看Thrift的源码学习thrift的设计的一些事. 主要是python的thrift源码.
看看python thrift server 是怎么一回事?
thrift server默认的模式是单线程堵塞的模型, TThreadPoolServer 是线程池的模型。 在python环境下大家还是选用TProcessPoolServer多进程版本。毕竟gil限制了并行,同时只能跑一个任务, 这里就不多扯在python下线程 vs 进程的选择了.
TServer.TSimpleServer 单进程单线程... TServer.TThreadedServer 每个请求独立的线程 TServer.TThreadPoolServer 线程池模型 TServer.TForkingServer 每个请求独立的进程 TServer.TProcessPoolServer 进程池方案
下面是thrift的进程池的模式代码,实现的原理倒是很简单,就是fork了几个子进程,子进程都针对 listen fd进行accept .
#xiaorui.cc
def serve(self):
"""Start a fixed number of worker threads and put client into a queue"""
#this is a shared state that can tell the workers to exit when set as false
self.isRunning.value = True
#first bind and listen to the port
self.serverTransport.listen()
#fork the children
for i in range(self.numWorkers):
try:
w = Process(target=self.workerProcess)
w.daemon = True
w.start()
self.workers.append(w)
except Exception, x:
logging.exception(x)
#wait until the condition is set by stop()
while True:
self.stopCondition.acquire()
try:
self.stopCondition.wait()
break
except (SystemExit, KeyboardInterrupt):
break
except Exception, x:
logging.exception(x)
self.isRunning.value = False
def workerProcess(self):
"""Loop around getting clients from the shared queue and process them."""
if self.postForkCallback:
self.postForkCallback()
while self.isRunning.value == True:
try:
client = self.serverTransport.accept()
self.serveClient(client)
except (KeyboardInterrupt, SystemExit):
return 0
except Exception, x:
再来看看thrift怎么实现函数映射的. 这个是个黑魔法,比如你有个类实例对象 a , 然后你想 a.ping() ,但是他没有 ping这个函数,直接调用会出现异常。 不想异常的调用有两种方法,第一个,你写个函数,第二个是你可以使用python的魔法函数来接受ping这个字符串,然后协议封装后,扔给thrfit服务端.
#xiaorui.cc
class TProtocolDecorator():
def __init__(self, protocol):
TProtocolBase(protocol)
self.protocol = protocol
def __getattr__(self, name):
if hasattr(self.protocol, name):
member = getattr(self.protocol, name)
if type(member) in [MethodType, UnboundMethodType, FunctionType, LambdaType, BuiltinFunctionType, BuiltinMethodType]:
return lambda *args, **kwargs: self._wrap(member, args, kwargs)
else:
return member
raise AttributeError(name)
再就是TCP服务的粘包问题
粘包本身就是个伪命题,因为他就是个数据边界的问题,你只要把边界定义清晰,就不会出现tcp粘包问题.
首先客户端把数据封装成帧的形式,即“数据长度+数据内容”,然后将处理之后的数据通过网络发送给Thrift服务器;此处也需要注意:要与Thrift服务器程序所采用的传输层的实现类一致,否则Thrift的传输层也无法将数据进行逆向的处理;
每Frame的前4字节会记录Frame的长度(少于16M)。读的时候按长度预先将整Frame数据读入Buffer,再从Buffer慢慢读取。写的时候,每次flush将Buffer中的所有数据写成一个Frame。
有长度信息的TFramedTransport是后面NonBlockingServer粘包拆包的基础。
Thrift vs Protocol Buffers 区别是什么?
Protocol Buffers 更适合做序列化,反序列化,像是 Msgpack那样,但是Thrift可以说是一个合集组件,他的传输可以是tcp,http,他的协议可以是http,json,二进制,服务器类型可以有多线程,多进程等.
话说回来, 任何rpc框架的实现都要做下面这些事.
1. 基本的网络通信,http,socket,异步框架tornado,netty等。
2. 通信数据的序列化与反序列化, json, msgpack
3. 程序内部的反射自省模式.
END.

