
前言:
去年10月份建了一个python技术群,到现在为止人数已经涨到700人了。最一开始我经常在群里回应大家的问题,不管是简单还是困难的,我都会根据自己的经验来交流。 让人新奇的是一些初学者关注最多的话题不是怎么学好python,反而是高并发,高性能这类高大上的话题。
记得有次几个不懂网络io、io多路复用含义网友,居然在群里吵了有半个小时,说出来的理论实在是让人哭笑不得。 群里当然有人在反驳,后来越聊越欢。 群里不少人在问我 uwsgi、gevent、tornado的一些设计,先前我尽量详细的作答,后来发现问我这些问题的朋友,并没有实际网络编程的经验,而我的回答更偏重于底层的实现,其实这样的解答不利于别人的理解的。我常常自己也在想 如何更好的回答别人的问题,一方面让人听着好懂,另一方面不让人觉得是在装逼。
没有人喜欢被别人说装逼,我同样也不喜欢,我是个谦虚善良的人。 我现在算是找到了自己的路数,我在回答问题的时候,习惯性的问别人几个问题,这样能把握好对方的深浅。 记得以前在腾讯的时候,名叫 院长 的前辈总是跟我说一句话,没有场景瞎谈高并发流氓行为。 胡粗理不粗呀,要避免自己纸上谈兵。
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新. http://xiaorui.cc/?p=4264
上面有点偏远这次的话题,这次主要讲解 uwsgi 、gunicorn的网络方面的设计。我会围绕下面几个问题讲解uwsgi、gunicorn的设计。
uwsgi 、gunicorn 有啥区别?
uwsgi、gunicorn的Master Worker进程模型?
有这么多worker模型,我们应该怎么选择?
uwsgi、gunicorn作为网关角色的意义?
这类框架怎么组合性能最高 ?
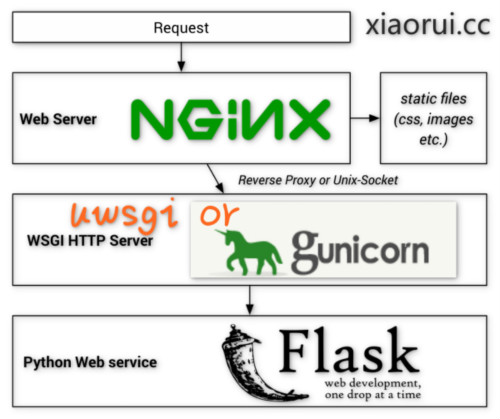
在架构上是这样的,nginx负责动态的转发和静态文件的直接访问,gunicorn和uwsgi作为网关服务用来解析http请求,后面的flask只是个application而已,没有server的服务特征。
先说简单干练的gunicorn讲起吧,下面是gunicorn的启动方式:
gunicorn -w 3 -b 127.0.0.1:5000 app:app -k gevent
通过strace得知 gunicorn 默认的网络模型是 select , 当我们worker 替换成 gevent 后, 改为 epoll 监听模型 . select 和 epoll之间的区别我们就不再啰嗦了。
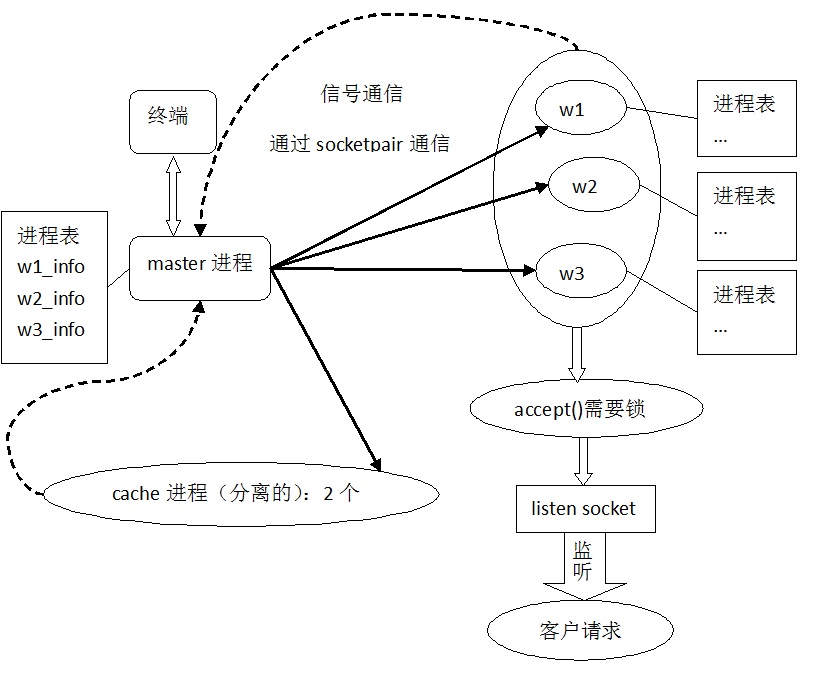
下面是gunicorn 、uwsgi 的 Master Worker的模型,大体实现是这样的。
如果我们的app是flask写得,那么用gevent做worker的意义在于什么?
Gevent worker 它提供了一种机制,让你可以监听到多个事件,epoll wait调用是阻塞的,但是可以设置超时事件,在超时事件内,如果有事件准备好就返回。比如采用epoll事件处理模型,当事件没准备好时,放到epoll里面,事件准备好了,我们就去读写,当读写返回EAGAIN时,我们将它再次加入到epoll里面。这样,只要有事件准备好了,我们就去处理它,当所有fd没有发生读写时,epoll才会阻塞等待。这样,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。工作流之间会产生切换的,但这里的切换消耗远没有多线程上下文切换大。
gunicorn根据Master Worker来fork出子进程,Master在这里不用做处理对外的http请求,而用来管理这些子进程,比如 升级、重载配置、kill进程避免oom 等。这些worker(子进程)继承了主进程的listening fd,这时候从accept、parse http protocol、response 都是在一个gevent协程里面的,也就说 在协程池的数目允许下,每个连接就是一个gevent协程。 如果你的app的业务逻辑是阻塞模式的,又没兼容gevent的patch,那么可想而知,结果是同步阻塞了。
gunicorn框架对外服务的模式下有http、tcp socket和unix domain socket,这跟uwsgi的模式一样一样的。
对于高并发的场景下,如果支持unix domain socket 模式,最少可以省略tcp的计算校验,这样性能有不少的提升。gunicorn wsgi相比uwsgi的协议相比,可以使传输的协议层更加的紧凑。
下面是uwsgi的启动方式:
/usr/local/bin/uwsgi --gevent 500 --gevent-monkey-patch --http 127.0.0.1:5000 --callable app --wsgi-file app.py --http-keepalive --master
上面是 uwsgi http 服务模式,但是uwsgi会启动两组端口port, 一个是5000 ,一个是5300x , 端口5000是我们已知的,这个端口用来直接对外接收请求的,他在构建完一个请求协议包之后,会connect 到 5300x 端口, 平白的多消耗了一些网络io。这种模式是 rep req模型,我能想到的优点是,他避免了因为listen fd事件的到来把其他进程唤醒的问题。 也就是说,只有5000对外,5300x是真正的worker。 端口5000根据一定的算法来选择worker。 5000 和 5300x的数据交互方式是 可压缩可序列化的tcp报文,有兴趣的可以抓包看看。
在内核2.6就早没有accept惊群这个说法了,但是当我们多个进程各自把listen fd放到epoll监听池里面时,其实会造成事件的唤醒,虽然最终只会被一次accept,但平白无故唤醒了多个进程也不是值得骄傲的。
题外话,nginx是通过多个进程轮流持锁的方式来避免epoll accept唤醒问题。
改成 –socket :5000 , 只会监听5000 port , 因为uwsgi协议比较特殊,测试起来很是麻烦。 我这里开源了一个uwsgi客户端。uwsgi client http://xiaorui.cc/?p=4205
改成 –socket /path/to/xiaorui.cc.sock ,线上经验表明 unix domain socket 模式要比tcp socket性能有提升的。
uwsgi 和 gunicorn 是长连接么? 怎么测试uwsgi的长连接 ? uwsgi 长连接实现方法?
gunicorn是长连接的,uwsgi要启用 –http-keepalive 模式才是长连接请求。 不要用curl测试,因为当你curl关闭的时候,已经出发了tcp四次挥手。 你可以根据strace和tcpdump来分析,在curl获取打印数据后,会发起close请求。 正确的测试方法是,你写个python requests请求,当请求完毕后,不要急着退出脚本,加一个sleep等待后再次去请求。 我们会发现连接始终是一个,tcpdump没有抓到建立新连接的报文。 uwsgi、gunicorn如何实现的长连接 ? 不只是在 返回的http加入 Connection:keep-alive 字段就标明是长连接,还需要借助select、epoll这样的io多路复用模型,用来监听各个fd读写事件。 简单说只要server不主动去close(),客户端client也不去close(),既然没有人去close(),这个连接自然就是长连接了,反之就是短连接。
flask 是长连接么? 我负责的说 是,长连接。既然长连接是借助select、epoll模型来实现,那么为毛flask是阻塞模式,随意加一个 time.sleep(xxx) 就io阻塞了。
这是Python flask的框架介绍… Werkzeug 是 Flask的wsgi server ,gunicorn 跟 flask做结合时,gunicorn可以理解为是 flask 的wsgi server。
Flask is a microframework for Python based on Werkzeug, Jinja 2 and good intentions. And before you ask: It’s BSD licensed!
以前讲过wsgi server的设计实现,这里就不多扯淡了,有兴趣的可以看看该文 http://xiaorui.cc/2016/04/16/%E6%89%93%E9%80%A0mvc%E6%A1%86%E6%9E%B6%E4%B9%8Bwsgi%E5%8D%8F%E8%AE%AE%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9%E5%8F%8A%E6%8E%A5%E5%8F%A3%E5%AE%9E%E7%8E%B0/。
简单说作为 wsgi server 他的意义在于 让我们专心去写web application,而不用专注于网络底层实现。 我们拿 flask 的Werkzeug来说,Werkzeug使用 Thread Local来实现的,所以才会有flask.request 、 flask.g 、 flask.session 这么便利的模块。引用的时候就像使用单例对象一样,但实际上对它们的所有赋值操作都只会影响到当前请求(当前线程),另外生存的周期也仅仅是这次请求而已。Thread Local 模式的实现一定要有一个 Thread Identity 作为标识。 为了测试我写一个测试发包程序,一个完整的http请求报文被切分成好几份,特意缓慢的发给Werkzeug服务端,直到结束,期间另开几个线程用来不断模拟正常的并发请求访问,可以成功获取结果。 接着我们在Flask的业务逻辑里加入io阻塞,发现这时候阻塞了。 通过不断strace追查查明,Werkzeug 在接收http请求和返回response结果的时候是异步非阻塞的。 随着我们单步调试的数据报文的到达,可以看到epoll wait由阻塞变为成功返回。
我通过阅读gunicorn、uwsgi 的代码得知,他们在单进程单线程下是和Werkzeug一样的。默认情况下,gunicorn会异步非阻塞的积攒tcp报文,通过http协议来解决tcp粘包的问题,当构建出一个完整http包,才会让这些worker来处理下一步的逻辑,也就是业务逻辑。 到此为止,我已经解释了 flask 使用Werkzeug epoll还是会发生阻塞的原因,也解释情况了gunicorn、uwsgi如何处理http请求 。
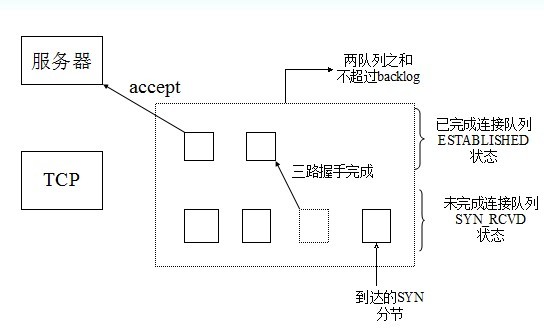
gunicorn、uwsgi遇到普遍的问题是502 504问题, 一说到502 ,我们知道后端处理过慢需要扩展worker,一说到504,我们知道处理超时,一般调整timeout就可以。那么502,504该问题的根本原因是什么? socket 内部是有两个队列,一个syn队列,一个是accept队列,这两个队列都在accept()之间就有了。 backlog是syn和accept队列之和,当你后端处理不及时,backlog又到限制时,会出现502,也就是说新的客户端不能建立,因为没有syn的槽位供你三次握手。 504 就很好理解了,处理超时,中断处理,直接范围错误信息。
# xiaorui.cc [program:test] command = /usr/bin/gunicorn -w 16 app:app -b localhost:8100 timeout = 60*60 backlog = 10000
Uwsgi、gunicorn 应该如何做选择? 这里需要注意的是 uwsgi http模式一定要慎用,这个rep req模式实在是奇葩呀。试想一想,linux做请求发起时,往大里说一共可以创建65535-1000的连接。Nginx通常是跟uwsgi一台服务器的,那么nginx收到一个请求时,会主动跟uwsgi建立连接,然后uwsgi跟worker又发起连接,那么连接数降到3w的理论值 。 又因为uwsgi转发了一个请求造成时间消耗。
uwsgi的功能是要比gunicorn丰富的多,通过丰富的配置参数就知道了。 但根据我几个项目的线上测试结果,gunicorn要比uwsgi稳定。 单笔性能的化,gevent性能是最好的。 推荐的配置是 unix domain socket、多进程、gevent协程池 组合。 线程池的方式不太推荐使用,pyhton的线程是内核的pthread线程,在繁多的线程数目下,对比协程的消耗可想而知。
后面我会依次分析下 uwsgi、gunicorn实现的源码,你会发现这些实现还是很精妙的。
没写完。。。。

