
源码分析 kubernetes apisix ingress crd 及缓存的实现原理 (二)
篇幅原因分成两个两篇, 第一篇主要分析了 apisix ingress controller 的架构实现以及对 k8s ingress 和 endpoints 进行分析.
源码分析 kubernetes apisix ingress controller 控制器的实现原理 (一)
本文也第二篇, 主要分析 apisix ingress 对自定义 CRD 资源的处理, 以及 apisix ingress 里如何建立多索引的缓存系统.
apisix 内置 crd provider 实现原理
前面分析了 apisix-ingress 对 k8s ingress 和 endpoints 资源处理的过程. 但 ingress 结构比较表现力有限, 通过 configmap 和 annotation 扩充的配置不够友好. 所有 apisix 也支持自定义的资源类型 ApisixRoute 和 ApisixUpstream. 这两个抽象过的 crd 的资源在配置上更加的灵活丰富, 也更好理解. 当前社区中除了 nginx-ingress 外, 其他有影响力的 ingress 都可通过自定义 CRD 来配置, 毕竟 ingerss 结构体略显简单.
不管使用 ingress 还是自定义 crd (ApisixRoute, ApisxiUpstream) , 控制器都会先把配置拆分组装成 apisix 自身的配置项. 比如会把 k8s ingress 对应到 apisix 的 routes/upstream/pulugin/ssl 四个配置, 而 apisixroute 会把配置拆分组合成 routes/stream_routes/upstream/plugin 四个配置. 在配置构建完成后, 依次向 apisix admin 发起变更请求.
实例化
ApisixRouteController 控制器内部实例化了 apisixRoute, service, apisixUpstream 这三个类型的 Informer. 在 apisixRouteInfomer 注册的 eventHandler 事件方法, 其逻辑就是根据增删改事件, 向 workqueue 发送不同的 event.
而在 service 和 apisixUpstream 注册的 eventHandler 事件方法, 其逻辑就是根据增删改事件, 向 relatedWorkqueue 发送不同的 event.
func newApisixRouteController(common *apisixCommon) *apisixRouteController {
c := &apisixRouteController{
// 只有一个协程
workers: 1,
// 索引关系, 通过 serviceName 找到 apisixroute key
svcMap: make(map[string]map[string]struct{}),
// 索引关系, 通过 upstream name 找到 apisixroute key
apisixUpstreamMap: make(map[string]map[string]struct{}),
}
// apisixRoute informer
c.ApisixRouteInformer.AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.onAdd,
UpdateFunc: c.onUpdate,
DeleteFunc: c.onDelete,
},
)
// service informer
c.SvcInformer.AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.onSvcAdd,
},
)
// apisix upstream informer
c.ApisixUpstreamInformer.AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.onApisixUpstreamAdd,
UpdateFunc: c.onApisixUpstreamUpdate,
},
)
return c
}
启动
启动两组协程, 分别是 runWorker 和 runRelatedWorker.
func (c *apisixRouteController) run(ctx context.Context) {
log.Info("ApisixRoute controller started")
defer log.Info("ApisixRoute controller exited")
defer c.workqueue.ShutDown()
defer c.relatedWorkqueue.ShutDown()
for i := 0; i < c.workers; i++ {
// 处理 apisixRoute 对象
go c.runWorker(ctx)
// 处理 service 和 apisixUpstream 对象
go c.runRelatedWorker(ctx)
}
<-ctx.Done()
}
runWorker() 方法监听 workqueue 队列, 然后处理 apisixRoute 的配置同步. 而 runRelatedWorker 则监听 relatedWorkqueue 队列, 处理 servcie 和 apisixUpstream 两个资源类型, 维护 service -> apisixroutekey 和 upstreamkey -> apisixroutekey 的映射关系, 还会往 workqueue 传递通知, 毕竟 apisixRoute 资源是跟 service 和 apisixUpstream 关联的, 当 service 和 apisixUpstream 发生变更时, apisix 的配置也需要变更下.
type apisixRouteController struct {
// service key -> apisix route key
svcMap map[string]map[string]struct{}
// apisix upstream key -> apisix route key
apisixUpstreamMap map[string]map[string]struct{}
}
func (c *apisixRouteController) runWorker(ctx context.Context) {
for {
obj, quit := c.workqueue.Get()
if quit {
return
}
switch val := obj.(type) {
case *types.Event:
err := c.sync(ctx, val)
c.workqueue.Done(obj)
}
}
}
func (c *apisixRouteController) runRelatedWorker(ctx context.Context) {
for {
obj, quit := c.relatedWorkqueue.Get()
if quit {
return
}
ev := obj.(*routeEvent)
switch ev.Type {
case "service":
err := c.handleSvcAdd(ev.Key)
...
case "ApisixUpstream":
err := c.handleApisixUpstreamChange(ev.Key)
...
}
}
}
sync 同步逻辑
sync 核心的同步配置流程. 先通过 apisix route lister 缓存中获取对象, 然后把结构转换成内部使用的结构, 最后调用 SyncManifests 方法, 把配置数据刷新到 apisix admin 里.
func (c *apisixRouteController) sync(ctx context.Context, ev *types.Event) error {
obj := ev.Object.(kube.ApisixRouteEvent)
namespace, name, err := cache.SplitMetaNamespaceKey(obj.Key)
if err != nil {
return err
}
var (
ar kube.ApisixRoute
tctx *translation.TranslateContext
)
switch obj.GroupVersion {
case config.ApisixV2beta3:
// 从 apisixRoute v2beta3 lister 缓存里获取对象
ar, err = c.ApisixRouteLister.V2beta3(namespace, name)
case config.ApisixV2:
// 从 apisixRoute v2 lister 缓存里获取对象
ar, err = c.ApisixRouteLister.V2(namespace, name)
default:
// 未知版本
return fmt.Errorf("unknown ApisixRoute version %v", obj.GroupVersion)
}
if err != nil {
return err
}
// 维护索引关系, apisix upstream key -> apisix route key
c.syncRelationship(ev, obj.Key, ar)
// 如果事件类型为删除, 则标记删除
if ev.Type == types.EventDelete {
ar = ev.Tombstone.(kube.ApisixRoute)
}
// 把当前的 apisixRoute 结构转成内部使用的 translation.TranslateContexT 结构
switch obj.GroupVersion {
case config.ApisixV2beta3:
...
case config.ApisixV2:
if ev.Type != types.EventDelete {
if err = c.checkPluginNameIfNotEmptyV2(ctx, ar.V2()); err == nil {
tctx, err = c.translator.TranslateRouteV2(ar.V2())
}
} else {
tctx, err = c.translator.GenerateRouteV2DeleteMark(ar.V2())
}
default:
// 未知版本
return fmt.Errorf("unknown ApisixRoute version %v", obj.GroupVersion)
}
// tctx 从 apisixRoute 结构中解析出 apisix 的 Route/Upstream/StreamRoutes/Plugin 配置.
m := &utils.Manifest{
Routes: tctx.Routes,
Upstreams: tctx.Upstreams,
StreamRoutes: tctx.StreamRoutes,
PluginConfigs: tctx.PluginConfigs,
}
var (
added *utils.Manifest
updated *utils.Manifest
deleted *utils.Manifest
)
// 判断事件类型赋值到不同的对象上.
if ev.Type == types.EventDelete {
deleted = m
} else if ev.Type == types.EventAdd {
added = m
} else {
oldCtx, _ := c.translator.TranslateOldRoute(obj.OldObject)
om := &utils.Manifest{
Routes: oldCtx.Routes,
Upstreams: oldCtx.Upstreams,
StreamRoutes: oldCtx.StreamRoutes,
PluginConfigs: oldCtx.PluginConfigs,
}
added, updated, deleted = m.Diff(om)
}
// 使用 http 把配置更新到 apisix
return c.SyncManifests(ctx, added, updated, deleted)
}
TranslateRouteV2 结构体转换
TranslateRouteV2 用来解析 ApisixRoute 数据结构到 TranslateContext 里.
func (t *translator) TranslateRouteV2(ar *configv2.ApisixRoute) (*translation.TranslateContext, error) {
ctx := translation.DefaultEmptyTranslateContext()
// 组装 http 数据结构
if err := t.translateHTTPRouteV2(ctx, ar); err != nil {
return nil, err
}
// 组装 tcp/udp 数据结构
if err := t.translateStreamRouteV2(ctx, ar); err != nil {
return nil, err
}
return ctx, nil
}
下面是 translateHTTPRouteV2 拼装结构的过程.
func (t *translator) translateHTTPRouteV2(ctx *translation.TranslateContext, ar *configv2.ApisixRoute) error {
ruleNameMap := make(map[string]struct{})
for _, part := range ar.Spec.HTTP {
if _, ok := ruleNameMap[part.Name]; ok {
return errors.New("duplicated route rule name")
}
ruleNameMap[part.Name] = struct{}{}
// 设置超时时间
var timeout *apisixv1.UpstreamTimeout
if part.Timeout != nil {
timeout = &apisixv1.UpstreamTimeout{
Connect: apisixv1.DefaultUpstreamTimeout,
Read: apisixv1.DefaultUpstreamTimeout,
Send: apisixv1.DefaultUpstreamTimeout,
}
...
}
// 设置插件配置
pluginMap := make(apisixv1.Plugins)
// add route plugins
for _, plugin := range part.Plugins {
if !plugin.Enable {
continue
}
if plugin.Config != nil {
if plugin.SecretRef != "" {
sec, err := t.SecretLister.Secrets(ar.Namespace).Get(plugin.SecretRef)
if err != nil {
break
}
for key, value := range sec.Data {
plugin.Config[key] = string(value)
}
}
pluginMap[plugin.Name] = plugin.Config
} else {
pluginMap[plugin.Name] = make(map[string]interface{})
}
}
...
// 设置 remote addr
if err := translation.ValidateRemoteAddrs(part.Match.RemoteAddrs); err != nil {
return err
}
// 设置 route 对象的属性
route := apisixv1.NewDefaultRoute()
route.Name = apisixv1.ComposeRouteName(ar.Namespace, ar.Name, part.Name)
route.ID = id.GenID(route.Name)
route.Priority = part.Priority
route.RemoteAddrs = part.Match.RemoteAddrs
route.Vars = exprs
route.Hosts = part.Match.Hosts
route.Uris = part.Match.Paths
route.Methods = part.Match.Methods
route.EnableWebsocket = part.Websocket
route.Plugins = pluginMap
route.Timeout = timeout
if part.PluginConfigName != "" {
route.PluginConfigId = id.GenID(apisixv1.ComposePluginConfigName(ar.Namespace, part.PluginConfigName))
}
for k, v := range ar.ObjectMeta.Labels {
route.Metadata.Labels[k] = v
}
ctx.AddRoute(route)
backends := part.Backends
// 处理 backends 主机列表到 upstream 结构里.
if len(backends) > 0 {
backend := backends[0]
backends = backends[1:]
// 获取 service clusterip 和端口
svcClusterIP, svcPort, err := t.GetServiceClusterIPAndPort(&backend, ar.Namespace)
// 通过参数组件 upstream name
upstreamName := apisixv1.ComposeUpstreamName(ar.Namespace, backend.ServiceName, backend.Subset, svcPort, backend.ResolveGranularity)
// 通过 hash/crc32 生成 id
route.UpstreamId = id.GenID(upstreamName)
if len(backends) > 0 {
weight := translation.DefaultWeight // 默认为 100
// 配置自定义的 weight 权重值
if backend.Weight != nil {
weight = *backend.Weight
}
plugin, err := t.translateTrafficSplitPlugin(ctx, ar.Namespace, weight, backends)
if err != nil {
return err
}
// 配置自定义流量切分规则
route.Plugins["traffic-split"] = plugin
}
if !ctx.CheckUpstreamExist(upstreamName) {
// 生成 upstream 结构
ups, err := t.translateService(ar.Namespace, backend.ServiceName, backend.Subset, backend.ResolveGranularity, svcClusterIP, svcPort)
if err != nil {
return err
}
// 添加到 tctx 的 upstream 集合里
ctx.AddUpstream(ups)
}
}
// 下面忽略的代码是处理 externalName service 的场景, 忽略了.
...
}
return nil
}
至于 translateStreamRouteV2 的实现跟 translateHTTPRouteV2 大同小异, 不做分析.
SyncManifests
在第一篇中有详细的分析过 SyncManifests 实现原理, 这里不再详细复述.
简单说就是依次判断各个子配置是否为空, 对不为 nil 的配置进行处理, 处理的逻辑是通过 http restful 对 apifix admin 进行变更请求.
代码位置: pkg/providers/utils/manifest.go
func SyncManifests(ctx context.Context, apisix apisix.APISIX, clusterName string, added, updated, deleted *Manifest) error {
var merr *multierror.Error
if added != nil {
for _, u := range added.Upstreams {
if _, err := apisix.Cluster(clusterName).Upstream().Create(ctx, u); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, pc := range added.PluginConfigs {
if _, err := apisix.Cluster(clusterName).PluginConfig().Create(ctx, pc); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, r := range added.Routes {
if _, err := apisix.Cluster(clusterName).Route().Create(ctx, r); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, sr := range added.StreamRoutes {
if _, err := apisix.Cluster(clusterName).StreamRoute().Create(ctx, sr); err != nil {
merr = multierror.Append(merr, err)
}
}
}
if updated != nil {
for _, r := range updated.Upstreams {
if _, err := apisix.Cluster(clusterName).Upstream().Update(ctx, r); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, pc := range updated.PluginConfigs {
if _, err := apisix.Cluster(clusterName).PluginConfig().Update(ctx, pc); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, r := range updated.Routes {
if _, err := apisix.Cluster(clusterName).Route().Update(ctx, r); err != nil {
merr = multierror.Append(merr, err)
}
}
for _, sr := range updated.StreamRoutes {
if _, err := apisix.Cluster(clusterName).StreamRoute().Update(ctx, sr); err != nil {
merr = multierror.Append(merr, err)
}
}
}
if deleted != nil {
...
}
if merr != nil {
return merr
}
return nil
}
apisix ingress 多级索引缓存设计
apisix ingress 内部使用 go-memdb 来构建多索引的缓存. go-memdb 是 hashicorp 社区的一个项目, 该库实现了实现内存级数据库, 支持丰富的索引, 支持多表的事务和多版本控制 mvcc 等.
go-memdb 的项目地址:
https://github.com/hashicorp/go-memdb
为什么使用 go-memdb 实现缓存系统 ?
因为 go-memdb 作为数据库是支持索引的, 且索引类别很是丰富, 不仅单字段索引, 类似 mysql 的联合索引, 另外如果索引字段为数字, 还可以 range 范围查询.
可以想象如果不使用 go-memdb, 而使用自定义索引映射, 那会相当的麻烦. 比如你的 struct 有 3 个字段, 后面想通过这三个字段的值直接找到对应的对象, 当然不能粗暴遍历, 通常需要多个 map[struct]interface{} 自定义索引关系, 插入还好, 更麻烦的是当触发更新和删除时, 需要维护已建立的索引.
一句话, 手动维护索引关系会相当麻烦.
通过下面的对象映射图, 应该让大家对多索引缓存的设计有更好的理解.
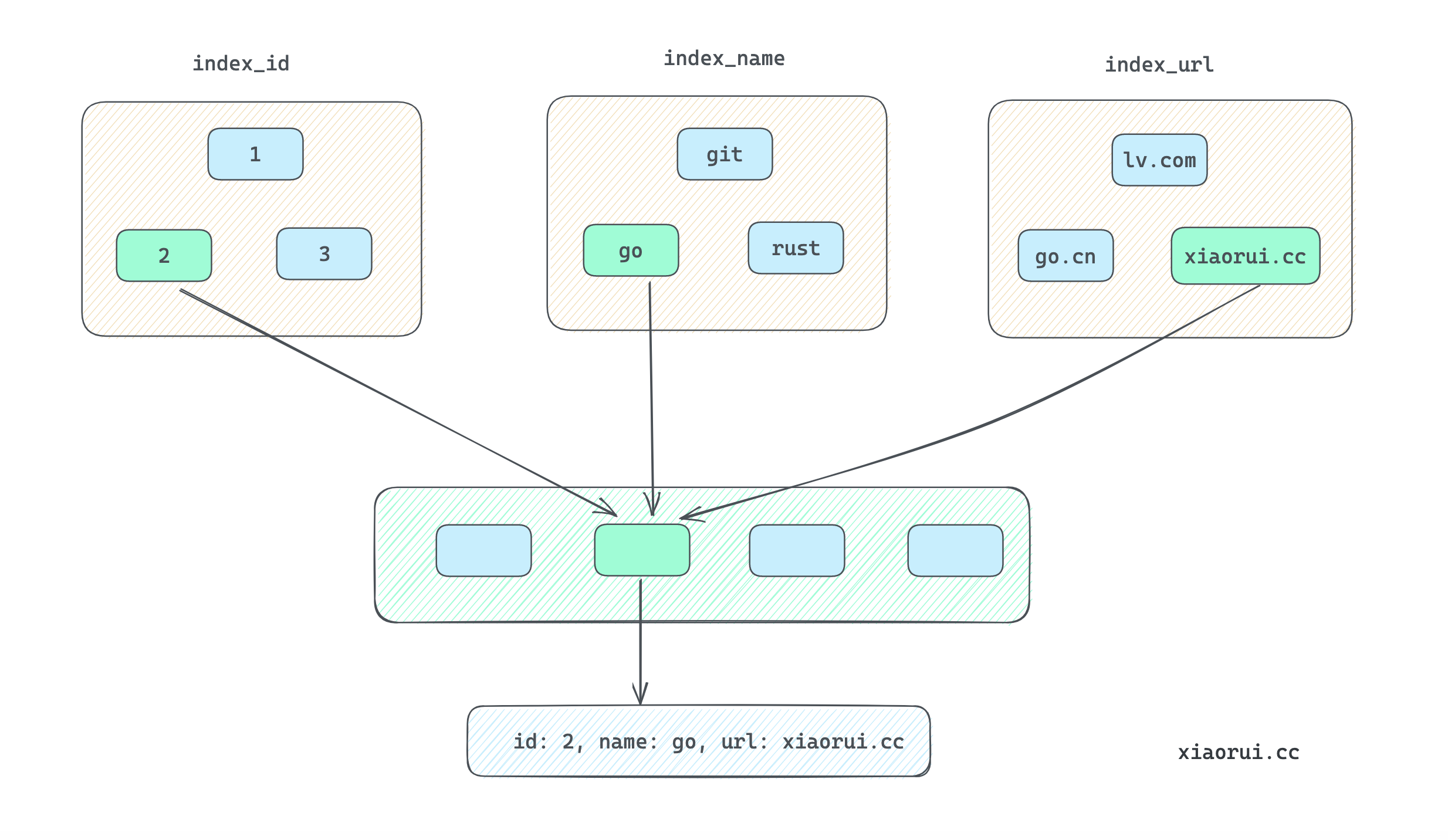
cache 实现原理
apisix ingress cache 的 schema 的代码位置.
在 db 里实例化了多个表结构, 每个表里又实例化多个索引映射. 当对 db 进行读写删操作时, go-memdb 会自动创建索引.
代码位置: pkg/apisix/cache/schema.go
_schema = &memdb.DBSchema{
Tables: map[string]*memdb.TableSchema{
"route": {
Name: "route",
Indexes: map[string]*memdb.IndexSchema{
"id": {
Name: "id",
Unique: true,
Indexer: &memdb.StringFieldIndex{Field: "ID"},
},
"name": {
Name: "name",
Unique: true,
Indexer: &memdb.StringFieldIndex{Field: "Name"},
AllowMissing: true,
},
"upstream_id": {
Name: "upstream_id",
Unique: false,
Indexer: &memdb.StringFieldIndex{Field: "UpstreamId"},
AllowMissing: true,
},
...
},
},
"upstream": {
Name: "upstream",
Indexes: map[string]*memdb.IndexSchema{
"id": {
Name: "id",
Unique: true,
Indexer: &memdb.StringFieldIndex{Field: "ID"},
},
"name": {
Name: "name",
Unique: true,
Indexer: &memdb.StringFieldIndex{Field: "Name"},
AllowMissing: true,
},
},
},
...
}
}
dbcache 里面实现了很多 apisix 内置对象的缓存管理, 下面拿 upstream 结构的缓存举例说明.
源码位置: pkg/apisix/cache/memdb.go
type dbCache struct {
db *memdb.MemDB
}
func NewMemDBCache() (Cache, error) {
db, err := memdb.NewMemDB(_schema)
if err != nil {
return nil, err
}
return &dbCache{
db: db,
}, nil
}
// 往 upstream 表里写对象
func (c *dbCache) InsertUpstream(u *v1.Upstream) error {
return c.insert("upstream", u.DeepCopy())
}
// 调用 memdb 的 insert 写数据
func (c *dbCache) insert(table string, obj interface{}) error {
txn := c.db.Txn(true)
defer txn.Abort()
if err := txn.Insert(table, obj); err != nil {
return err
}
txn.Commit()
return nil
}
// 从 upstream 表里获取数据
func (c *dbCache) GetUpstream(id string) (*v1.Upstream, error) {
obj, err := c.get("upstream", id)
if err != nil {
return nil, err
}
return obj.(*v1.Upstream).DeepCopy(), nil
}
// tnx.first 是获取第一条数据
func (c *dbCache) get(table, id string) (interface{}, error) {
txn := c.db.Txn(false)
defer txn.Abort()
obj, err := txn.First(table, "id", id)
if err != nil {
if err == memdb.ErrNotFound {
return nil, ErrNotFound
}
return nil, err
}
if obj == nil {
return nil, ErrNotFound
}
return obj, nil
}
// txn.get 可以获取多条数据
func (c *dbCache) list(table string) ([]interface{}, error) {
txn := c.db.Txn(false)
defer txn.Abort()
iter, err := txn.Get(table, "id")
if err != nil {
return nil, err
}
var objs []interface{}
for obj := iter.Next(); obj != nil; obj = iter.Next() {
objs = append(objs, obj)
}
return objs, nil
}
...

