
前言:
大部门下面的测试部,也就是子键他们在搞大批量的硬件信息数据抓取,这次不能用那些高端的saltstack ansible了。因为我们要远程的用ipmitool的接口来抓取信息,要是用在client搞的话,还要给他们密码,这个是很不安全的。 so,要搞一套基于自己的一套密码认证及数据抓取的平台。
他们最后决定用gearman,虽然我也用过这东西,但是总感觉缺点啥,用着不顺畅。
其实我个人还是推荐用mq的东西。我用zeromq实现了分布式的任务的派发,性能很是强劲,在可用性上也做了很多的监控。
虽然不能推荐他们用rabbitmq,但我还是把rabbitmq在实际中的小应用,分享出来。希望对大家有些帮助。
rabbitmq redis的对比
rabbitMQ和redis等都可以做队列,但是他们还是有区别的,比如,redis的消息队列,如果在从队列pop出去的时候,worker处理失败的话,数据不会回到队列中,需要从业务中手动把失败的处理数据push到队列中,而rabbmitMQ可以自动处理失败的worker使数据不丢失;rabbitMQ还可以保证数据在传输过程中持久化,在通道和队列中的数据可以设置为持久化。
rabbitmq zeromq的对比
rabbitmq 虽然没有zeromq那样的速度,但是他在一定的程度上提供了更加可靠的mq,有持久化和防止崩溃的处理。
下面还有详细的对比的。
烦人的官方化介绍:
RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然
先来理解他的一些个专有的名词 ~
概念:
channel:通道,amqp支持一个tcp连接上启用多个mq通信通道,每个通道都可以被作为通信流。
producer:生产者,是消息产生的源头。
exchange:交换机,可以理解为具有路由表的路由规则。
queues:队列,装载消息的缓存容器。
consumer:消费者,连接到队列并取走消息的客户端。
核心思想:在RabbitMQ中,生产者从不直接将消息发送给队列。
事实上,有些生产者甚至不知道消息是否被送到某个队列中去了。生产者只负责将消息送给交换机,而交换机确切地知道什么消息应该送到哪。
bind:绑定,实际上可以理解为交换机的路由规则。每个消息都有一个称为路由键的属性(routing key),就是一个简单的字符串。一个绑定将【交换机,路由键,消息送达队列】三者绑定在一起,形成一条路由规则。
exchange type:交换机类型:
fanout:不处理路由键,转发到所有绑定的队列上
direct:处理路由键,必须完全匹配,即路由键字符串相同才会转发
topic:路由键模式匹配,此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.*” 只会匹配到“audit.irs”

关于传说中的性能~
下图是一些个大牛做的综合的测试。
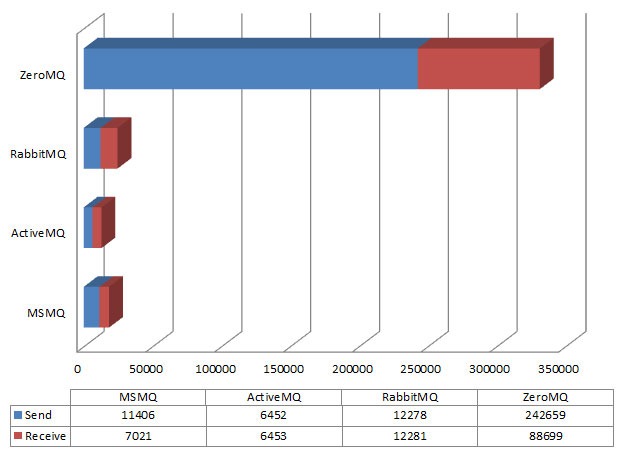
对于rabbitmq zeromq,我自己虽然没有专门的测试,但是实际应用中都有应用的。 zeromq的速度不用质疑,确实很快很快,但是他不做数据的存储持久化和可用性,要是client没有开启的话,他照样会把信息pub出去,不管你存不存在。但是rabbitmq就考虑了很多,看下图大家就知道了。
对头,rabbitmq虽然性能不能和zeromq相比,但是在项目中应用还算不错的。

那么,rabbitmq server的安装很是简单
yum -y install rabbitmq-server
我们可以看到他所依赖的那些关联包~ 大家应该知道他是erlang写的吧 !
写的一个小demo 发送端【生产者】,可以想成一个老板,把这次要做的事情到分给大家。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pika
import sys
import random
def makepassword(rang = "23456789qwertyupasdfghjkzxcvbnm", size = 8):
return string.join(random.sample(rang, size)).replace(" ","")
parameters = pika.ConnectionParameters(host = 'localhost' )
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
channel.queue_declare(queue = 'task_queue' , durable = True )
message=makepassword()
channel.basic_publish(exchange = '',
routing_key = 'task_queue' ,
body = message,
properties = pika.BasicProperties(
delivery_mode = 2 , # make message persistent
))
接收端【消费者】,可以想成是工人的角色。有几个工人,就几个工人,就几个工人一块干活。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost' ))
channel = connection.channel()
channel.queue_declare(queue = 'task_queue' , durable = True )
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count = 1 )
channel.basic_consume(callback,
queue = 'task_queue' )
channel.start_consuming()
默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。试着添加三个或更多得工作者(workers)。
从上面来看,每个工作者,都会依次分配到任务。那么如果一个工作者,在处理任务的时候挂掉,这个任务就没有完成,应当交由其他工作者处理。所以应当有一种机制,当一个工作者完成任务时,会反馈消息。
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
print “正在搞呀”
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
运行上面的代码,我们发现即使使用CTRL+C杀掉了一个工作者(worker)进程,消息也不会丢失。当工作者(worker)挂掉这后,所有没有响应的消息都会重新发送。
如果你没有特意告诉RabbitMQ,那么在它退出或者崩溃的时候,它将会流失所有的队列和消息。为了确保信息不会丢失,有两个事情是需要注意的:我们必须把“队列”和“消息”设为持久化。
channel.queue_declare(queue='task_queue', durable=True)
这两条就是为啥rabbitmq比zeromq更可靠的原因 !
还有一个就是针对消费者的分发的策略。
实现负载均衡,可以在消费者端通知RabbitMQ,一个消息处理完之后才会接受下一个消息。

channel.basic_qos(prefetch_count=1)
总结,用rabbitmq不错的选择。


有个问题请教,为什么例子里面的生产者中没有使用到exchange呢,不是说生产者是把消息发送给exchange而不是Queue吗