前言:
go1.14版本中也更新了内存分配器。go先前的版本,在多GOMAXPROCS高频申请内存场景下会引起mheap.lock的锁竞争问题,所以在新版内存分配器着重解决这个问题。
go1.14内存分配器优化的逻辑简单说就是删除自由内存范围的概念,并使用位图跟踪自由内存,另外允许p缓存一部分bitmap。
该文章原文地址 http://xiaorui.cc/archives/6613
为什么mheap成为瓶颈?
虽然在go的内存设计中有多级缓存的概念 ( mcache、mcentral、mheap ),mcache由于绑定在P上,所以无锁的。central数组按照size class芬超了67个,每个mcentral都有一个锁,锁粒度在size class。但mheap结构是全局唯一,相关的内存分配及释放会独占mheap.lock。😅
go1.14内存分配器优化的逻辑简单说就是删除自由内存范围的概念,并使用位图跟踪自由内存,另外在p缓存一部分bitmap。
源码分析
(有空再写) …
go官方给出的内存分配器设计方案,go proposal,https://github.com/golang/proposal/blob/master/design/35112-scaling-the-page-allocator.md
性能测试
测试脚本,逻辑就是开协程不断的申请对象。
// xiaorui.cc
package main
import (
"fmt"
"sync"
"time"
)
type node struct {
ident string
context string
}
func run() {
iter := 100000
data := make(map[int]node, iter)
ts := time.Now().String()
for i := 0; i < iter; i++ {
data[i] = node{
ident: ts,
context: ts + ts + ts,
}
}
for i := 0; i < iter; i++ {
delete(data, i)
}
}
func batchRun() {
wg := sync.WaitGroup{}
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
run()
wg.Done()
}()
}
wg.Wait()
}
func main() {
start := time.Now()
for i := 0; i < 100; i++ {
batchRun()
}
cost := time.Since(start)
fmt.Printf("time cost: %+v \n", cost)
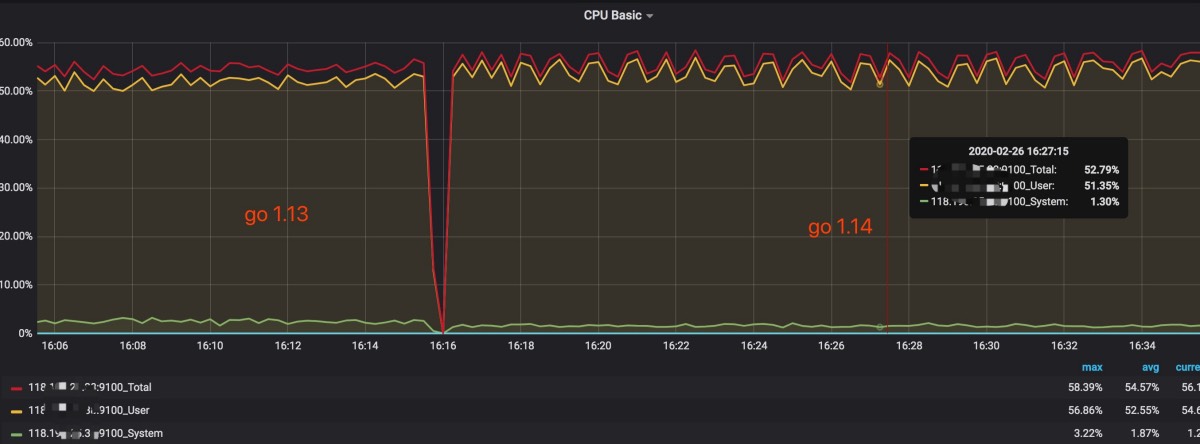
}在并发密集申请内存下,go1.14的内存分配性能是快了一些。(节字大小影响结果)
// xiaorui.cc
go 1.13 vs go 1.14
time cost: 1m11.458039901s
time cost: 57.242940201s
go 1.13 vs go 1.14
time cost: 2m27.298913751s
time cost: 1m56.458370589scpu消耗相差不大
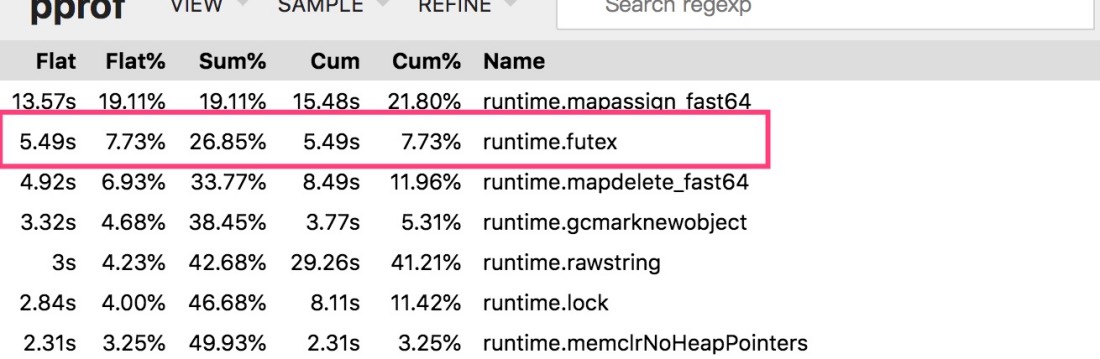
通过golang pprof top对比,go 1.14的runtime.futex调用少于go1.13。使用strace统计也是同样的结果。