
前言:
前些日子完成了整个交易服务的缓存系统的构建,颇有些心得。就在公司组织了一场关于redis的技术分享,算是个我这几年对redis的经验总结。
这次主要分享redis的数据结构原理及缓存的方案。虽然公司内同事工作中时常用到redis,但对redis的底层结构及社区里的redis方案了解有限。😅 相信这次的分享对大家都有所帮忙,对我的kpi打分也有帮忙。😁
地址:
下面是ppt中的一些内容截图,另外完整的pdf已经推到github里,有兴趣的可以看下。https://github.com/rfyiamcool/share_ppt/blob/master/redis_qa.pdf





















文本 (for seo):
// xiaorui.cc
Redis经验之谈
xiaorui.cc
github.com/rfyiamcool
menu
数据结构
底层数据结构
功能点
使用经验
高级场景
Redis6
Redis数据结构
String 字符串
key value
List 列表
timeline
未读消息
简单消息队列
Hash 字典
一对多的关系映射
Set 集合
好友的交集, 并集, 差集
去重
Sorted Set 有序集合
排行榜
排序
Stream 流
类似kafka模型的消息队列
消费组, ack, 偏移量 …
Redis数据结构
bitmap 位图
用户签到
用户在线状态
geo 地理位置
查看附近的人
状态位标记
外卖
…
…
pubsub 发布订阅
不靠谱的发布订阅
hyperloglog 基数统计
每日访问的ip数统计
…
Redis底层数据结构
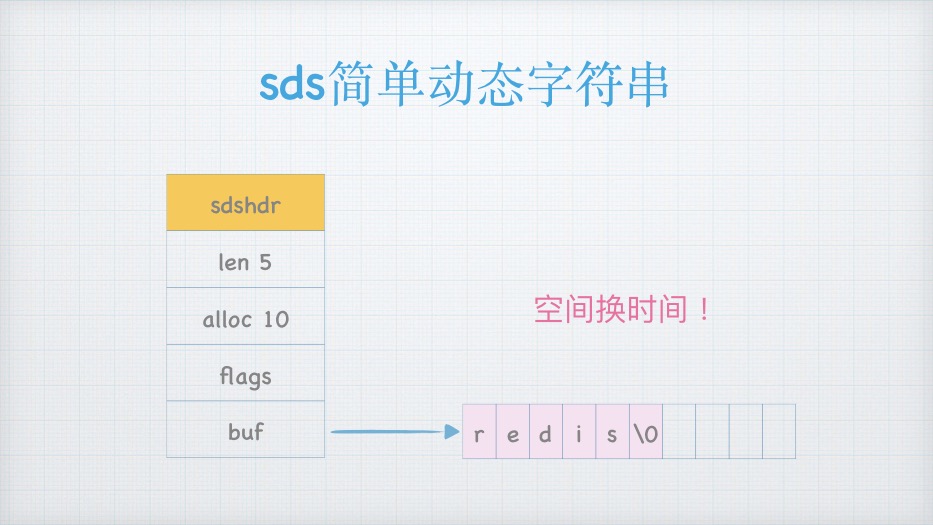
SDS
Dict
LinkedList
Inset
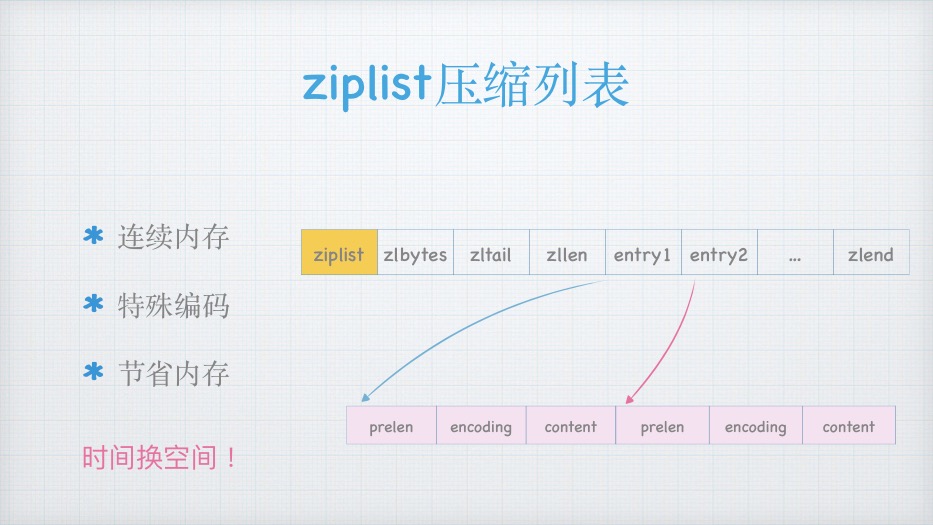
Ziplist
SkipTable
Quicklist
RadixTree
…
Redis数据结构组成
String
sds
Hash
ziplist
dict
Set
inset
dict
List
ziplist
quicklist
Sorted Set
hash + skiptable
Stream
radix-tree
key的规范
每个业务单独的database ( cluster不⽀持 )
加⼊项⽬的前缀
⼀级key不要超过千万
尽量都加⼊TTL
使⽤ { hashtag } 来绑定亲和性
Value的规范
选择合适的数据结构
长字符压缩存取 (snappy, msgpack, more…)
避免big key ( 删除和迁移时阻塞)
避免hot key (单点性能)
ziplist更省内存
hash (order_id_1000)
hash (order_id)
oid_1000
oid_1000
oid_1002
oid_1002
oid_1333
oid_1333
hash (order_id_2000)
oid_2111
oid_2111
oid_2333
oid_2333
hash-max-ziplist-entries = 1000
hash-max-ziplist-value = 128
省内存
连续内存, 紧凑的编码, 减少了碎⽚, 减少了指针引⽤
ziplist⽀持的数据结构
hash-max-ziplist-entries && hash-max-ziplist-value
list-max-ziplist-size
zset-max-ziplist-entries && zset-max-ziplist-value
持久化
RDB
快照备份
加载顺序
先 AOF
AOF
日志追加
always
every sec
RewriteAOF
混合模式 RDB + AOF
后 RDB
加载速度
快 RDB
慢 AOF
持久化
RDB
AOF
redis-main
rdb snapshot
child-process
fork
注意事项
避免使⽤O(n)的指令
keys *, hgetall, smembers, zrange all, lrange all
直接在redis.conf⾥rename-command阻塞指令
使⽤scan, hscan, sscan, zscan
使⽤unlink异步删除key
提⾼吞吐
使⽤pipeline批量传输, 减少⽹络RTT
使⽤多值指令 (mset, hmset)
使⽤script lua
⼲掉aof ?
(big key) or (hot key)
big key
scan / small range get
unlink (redis 4.0 async del)
hash shard
hot key
hash shard
redis lua
减少RTT消耗
⾃定义函数
保证多指令原⼦性
注意阻塞问题
redis module
自定义注册新命令
自定义新数据结构
性能比redis lua更强劲
redis4.0 以上
RedisJson
RedisBloom
RedisTimeSeries
more …
排查问题
外部 (慎用)
redis-cli monitor
内部
keyspace
slow log
redis-cli —latency
内存碎片
- - bigkeys
string, bytes空间
set, list, zset, hash, 元素个数
redis-rdb-tool
分析内存分布
memory usage key_name
memory stats
memory purge
阻塞及延迟
redis-cli --intrinsic-latency 10
redis-cli --latency-history
info -> instantaneous_ops_per_sec
info -> used_memory_human
connected_clients
单线程 ?
主线程
aof⽇志
bio线程
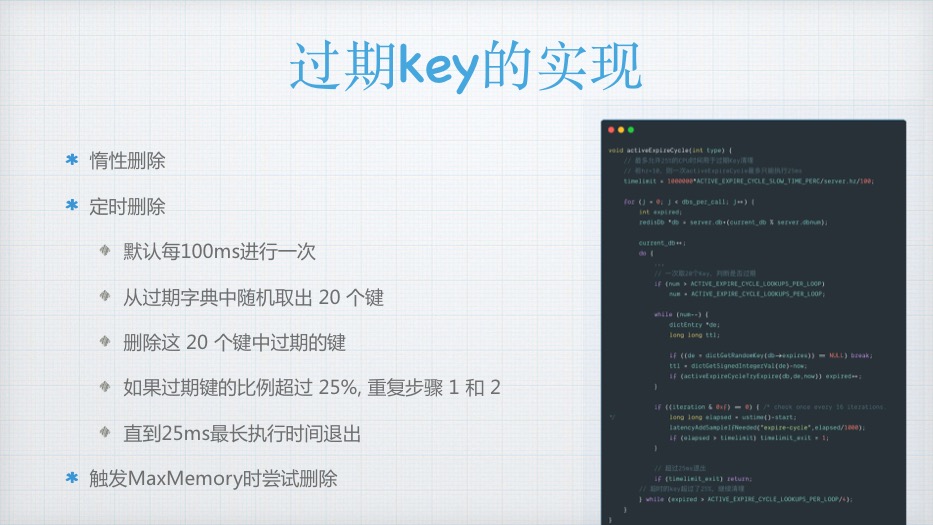
过期key的实现
惰性删除
定时删除
默认每100ms进行一次
从过期字典中随机取出 20 个键
删除这 20 个键中过期的键
如果过期键的比例超过 25%, 重复步骤 1 和 2
直到25ms最长执行时间退出
触发MaxMemory时尝试删除
缓存淘汰
CONFIG SET maxmemory 50 GB
volatile-lru (默认)
从设置过期数据集⾥查找最近最少使⽤
volatile-ttl
从设置过期的数据集⾥清理已经过期的
key.
volatile-random
从设置过期的数据集中任意选择数据淘汰
allkeys-lru
从数据集中挑选最近最少使⽤的数据淘汰
allkeys-random
从数据集中任意选择数据淘汰
no-enviction
不清理
事务
client
command
watch 监听key的变化
is
transaction
mutli 开启事务
exec 执⾏事务
discard 放弃事务
unwatch 放弃监听
pipeline vs 事务
watch/unwatch
watch
multi
queue
pipeline会被打断
事务不会被打断
redis不⽀持标准的acid事务
exec/discard
单机进化到多实例
什么是多实例
为什么要多实例化
多实例化需要注意什么?
单机多实例
what 多实例
6379
6380
6381
++
redis1
redis2
redis3
more
why 多实例
最⼤程度的使⽤内存
避免单实例RDB Write时
被kernel oom
使⽤swap造成阻塞.
copy on write will block
绕开redis单⼯作线程的问题
阻塞指令
系统调⽤
单实例启动太慢
busy event
扩展, 迁移, 内存随便整理
hashcrc & codec
more …
How 多实例
如 128G 内存
11G 为⼀个实例, 启动个10实例
redis server关闭⾃动rdb及aof
后台脚本来控制bgsave.
启动时也是⼀个个的启动
简约集群
主从模式
vip多线程版 twemproxy
codis
redis cluster
集群
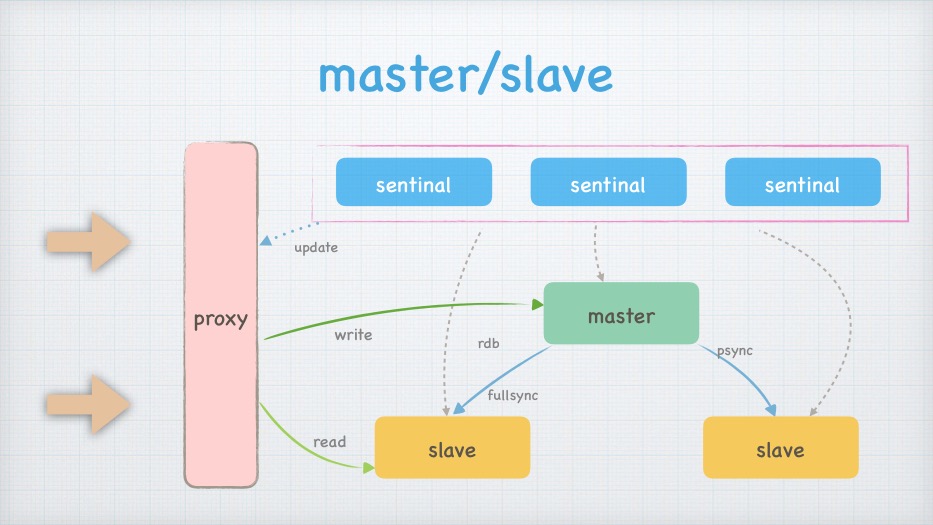
master/slave
sentinal
sentinal
sentinal
update
proxy
master
write
rdb
psync
fullsync
read
slave
slave
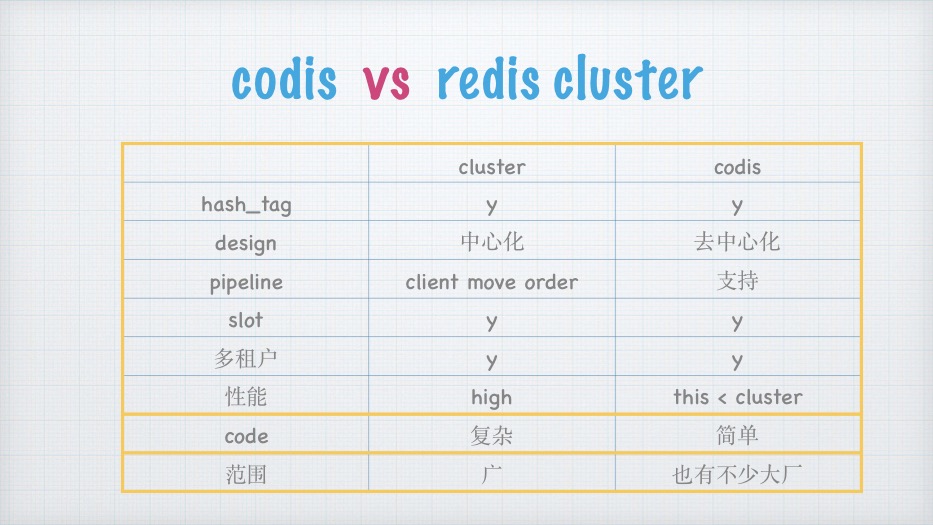
codis vs redis cluster
cluster
codis
hash_tag
y
y
design
中⼼化
去中⼼化
pipeline
client move order
⽀持
slot
y
y
多租户
y
y
性能
high
this < cluster
code
复杂
简单
范围
⼴
也有不少⼤⼚
codis
codis-proxy
codis-proxy
zookeeper
redis
redis-m
主机组
redis-s
dashboard
redis cluster
常⽤场景
缓存
缓存⼀致性
缓存穿透
缓存击穿
缓存雪崩
分布式锁
redlock
延迟队列
…
缓存⼀致性
write cache -> write db
write db -> write cache
evict cache -> write db
write db -> evict cache
evit cache -> write db ->
evit cache
缓存⼀致性
write db -> write cache
更新cache失败
write cache -> write db
更新db失败
并发引起脏数据
client1更新了DB
client2更新了DB
client2更新cache
但client1覆盖了client2的cache
缓存⼀致性
evict cache -> write db
延迟引起脏数据
write db -> evict cache
脏数据概率⼩于先evit cache
client1先删除缓存
client1查询数据库, 得⼀个旧值
client2查询发现缓存不存在
client2将新值写⼊数据库
client2数据库查询得到旧值
client2删除缓存
client2将旧值写⼊缓存
client1将查到的旧值写⼊缓存
client1将新值写⼊数据库
evit cache -> write db -> evit cache
脏数据概率更⼩
规避脏数据
TTL
定时更新
Binlog订阅更新
Delay Queue
sync-srv
缓存⼀致性
所以, 在更新策略上, 难以保证绝对⼀致性, 但可以最终⼀致性
拼概率, 减少产⽣脏数据的可能
write db; write cache; binlog or ttl 双写
多数公司的选择
write db; binlog更新
didi, iqiyi
write db; evct cache 也是个好选择 !
facebook, 58
穿透&雪崩
穿透 (访问⼀个不存在的key)
在缓存中加⼊该key的null值
bloomfilter
雪崩 (⼤量key的失效)
不主动配置TTL
后台同步缓存时, 加⼊jitter ttl
击穿
击穿 (⼤量请求未缓存的key)
实现redis分段锁, 同样的请求争夺⼀把锁
拿到锁的去数据库查询
未拿到锁的等待, 再尝试访问缓存
缓存中还没有数据, 尝试数据库拿取
分布式锁
安全可靠
lua make ( compare and set ) !!!
say no
可重⼊锁
set + nx + ex
client_1
Redis
true
say yes
公平调度
say hard
{ bll_lock_key: ident }
client_2
set + nx + ex
false
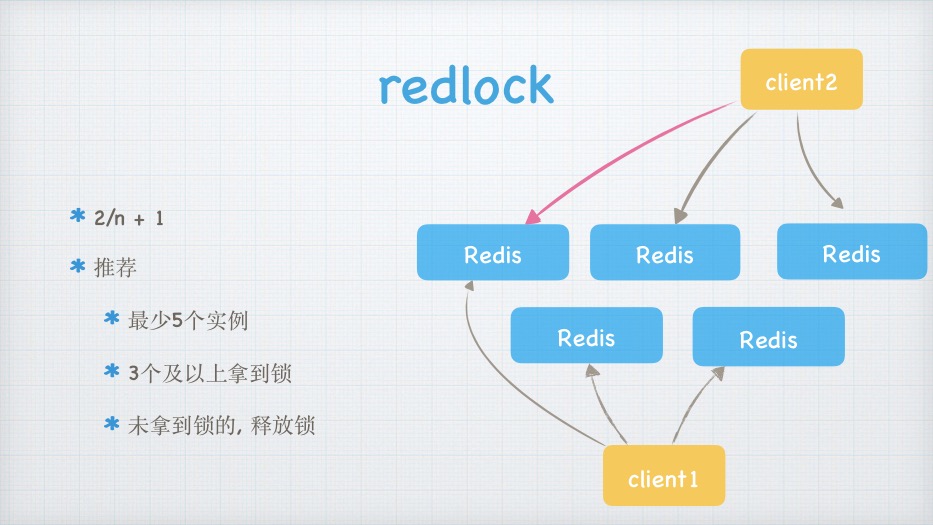
redlock
client2
2/n + 1
推荐
最少5个实例
Redis
Redis
Redis
Redis
Redis
3个及以上拿到锁
未拿到锁的, 释放锁
client1
redis单节点性能
⼤约
单命令并发可达 10w TPS
管道及多指令可达 50w TPS
单命令时延在 150 us 左右
单节点
经历过的性能指标
1w 的稳定长连接
10w TPS
队列千万级别
百万数量key
单节点
维护经验
300个redis实例
30台服务器 (混部)
每个实例10G
约 3T 内存
集群
redis6
新增的resp3加⼊缓存特性
返回key的属性, ⽐如频率
更新范围
acl⽤户权限控制
控制命令及key
redis cluster proxy
兼容各类sdk
io多线程
io线程负责read, decode, encode, write
操作内存还是主线程
other ppt
redis cluster那些事⼉
https://github.com/rfyiamcool/share_ppt/blob/master/redis_cluster.pdf
redis之⾼级应⽤
https://github.com/rfyiamcool/share_ppt/blob/master/redis_advance.pdf
⼤话redis设计与实现
https://github.com/rfyiamcool/share_ppt/blob/master/rediscode.pdf
“Q&A!”
–峰云就她了

