
前言:
slack报警提示同事的线上系统爆出了大量的tcp time_wait。通过netstat可以判断出是postgreSQl引起的。初步分析像是连接池没有得到复用,一直在new pg连接和close连接。
我们的pg驱动是golang内置的database/sql库,该库不仅实现了sql基于使用,而且还自带连接池。database/sql库兼容mysql和postgre。
该文章后续仍在不断的更新修改中, 请移步到原文地 http://xiaorui.cc/?p=5771
排除问题
首先我们要知道谁去主动关闭连接,那么谁就会产生2ms时间的time wait。出问题的服务只有grpc server和postgre数据库两个类型的连接。
既然通过netstat可以看出问题出在postgre, 那么问题要么是我们database/sql,要么出在我们的用法上。
database/sql作为golang的标准库,不应该会有这类低级问题。
那么看我们的配置 maxIdle, maxConn, maxConn可以理解为最大的连接数,maxIdle是最大的空闲数。 我曾经看过一些框架的连接池实现,maxIdle的实现略有不同。有些框架会严格控制maxIdle,有些会放到free里,等待expire后淘汰。
那么database/sql是如何实现的? 研究下 database/sql的go源代码吧。
源代码分析
当我们使用query和begin事务操作sql的时候,会调用db.query()方法,该方法会return一个连接。
// xiaorui.cc
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
// maxBadConnRetries 默认是2
for i := 0; i < maxBadConnRetries; i++ {
// 从连接池中尝试获取连接
rows, err = db.query(ctx, query, args, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.query(ctx, query, args, alwaysNewConn)
}
return rows, err
}
func (db *DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error) {
var tx *Tx
var err error
// maxBadConnRetries 默认是2
for i := 0; i < maxBadConnRetries; i++ {
// 从连接池中尝试获取连接
tx, err = db.begin(ctx, opts, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.begin(ctx, opts, alwaysNewConn)
}
return tx, err
}
func (db *DB) begin(ctx context.Context, opts *TxOptions, strategy connReuseStrategy) (tx *Tx, err error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.beginDC(ctx, dc, dc.releaseConn, opts)
}
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}
调用db.conn()时,申请连接会传递一个参数, 该参数用来说明始终实例化新连接还是从缓存中获取。 sql默认就是一个连接池,开始会先用cachedOrNewConn来获取连接。
如果总是返回ErrBadConn,那么就再通过alwaysNewConn来申请。
const (
// xiaorui.cc
alwaysNewConn connReuseStrategy = iota
cachedOrNewConn
)
申请的连接的过程, 简单的说,配置了maxOpen,而且当前已经存在的连接超过maxOpen,那么就一直阻塞等待,等待别的协程来释放sql连接。不匹配前面的条件,那么就实例化新的连接。
// xiaorui.cc
func (db *DB) conn(ctx context.Context, strategy connReuseStrategy) (*driverConn, error) {
if db.closed {
db.mu.Unlock()
return nil, errDBClosed
}
lifetime := db.maxLifetime
// 获取空闲的连接,判断是否超时,无超时返回调用方,超时返回err, 调用方会重试,默认是重试2次
numFree := len(db.freeConn)
if strategy == cachedOrNewConn && numFree > 0 {
conn := db.freeConn[0]
if conn.expired(lifetime) {
conn.Close()
return nil, driver.ErrBadConn
}
if err == driver.ErrBadConn {
conn.Close()
return nil, driver.ErrBadConn
}
return conn, nil
}
// 等待别人释放归连接。
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
req := make(chan connRequest, 1)
reqKey := db.nextRequestKeyLocked()
db.connRequests[reqKey] = req
db.waitCount++
db.mu.Unlock()
waitStart := time.Now()
// Timeout the connection request with the context.
select {
case <-ctx.Done():
...
case ret, ok := <-req:
atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))
if !ok {
return nil, errDBClosed
}
if ret.err == nil && ret.conn.expired(lifetime) {
ret.conn.Close()
return nil, driver.ErrBadConn
}
return ret.conn, ret.err
}
}
// 不满足上面的条件,那么就实例化新的连接, numOpen计数。
db.numOpen++ // optimistically
ci, err := db.connector.Connect(ctx)
if err != nil {
db.numOpen-- // correct for earlier optimism
db.maybeOpenNewConnections()
return nil, err
}
dc := &driverConn{
db: db,
createdAt: nowFunc(),
ci: ci,
inUse: true,
}
db.addDepLocked(dc, dc)
return dc, nil
}
上面是申请连接,下面是释放和归还连接到连接池,当我们执行Query()和手动commit和rollback的时候,都会触发db.releaseConn()方法。
func (dc *driverConn) releaseConn(err error) {
dc.db.putConn(dc, err, true)
}
当归还连接到连接池的时候,发现当前的连接数已经大于我们自己配置的maxOpen,那么就直接close连接。如果正常连接池,那么观察下db.connRequests是否有人等待连接。
如果在等待,那么就把连接通过channel传递过去。如果没有人正在等待获取sql连接,那么就把连接放到db.freeConn里。
// xiaorui.cc
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {
// 尝试把连接归还给连接池
added := db.putConnDBLocked(dc, nil)
if !added {
// 关闭连接
dc.Close()
return
}
...
if !resetSession {
return
}
...
}
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.closed {
return false
}
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey) // Remove from pending requests.
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
if db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
总结:
在分析go databse/sql的源代码的过程中,我们可以看到了tcp time wait的原因。我们的maxConn有100个, 而maxIdle确只有20个。
那么当用户请求上来的时候,每个协程都会从连接池获取连接,拿不到就实例化一个新的pg连接,用完了连接后尝试归还连接池不成功,那么就主动close连接。 谁先close,谁就有time wait。所以,原因找到了。
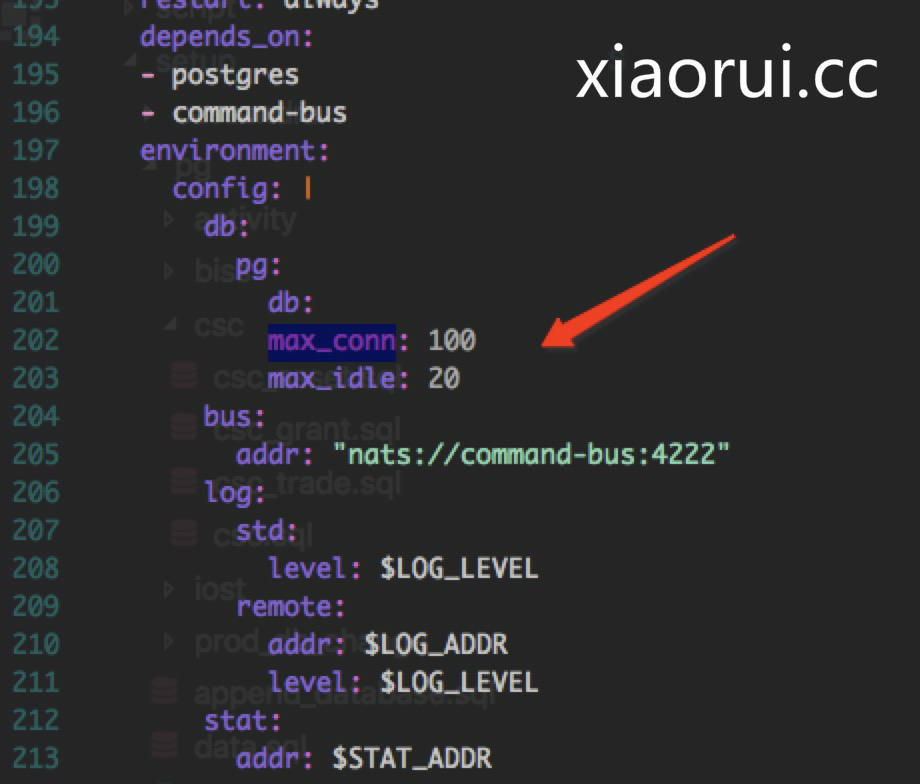
解决方法很简单,就是把maxIdle调大一点,其实我还是更喜欢go redis的连接池实现,不会立马把大于maxConn和小于maxIdle的连接给关掉,而是给个释放时间,相当于给一个缓冲池。不然每次都要实例化连接,然后close,调用耗时被延长。

