
今天说说,我们为什么会选择从kibana4迁移到grafana,并选用grafana作为elasticsearch的图表展现工具。 文章中关于kinaba和grafana的对比会有些片面,勿喷.
最一开始使用kibana ElasticSearch的组合是为了集中式收集应用及系统日志. 后来由于业务方面的原因,现在各个业务的多数模块也选择依赖elasticsearch。除此之外,现在监控的数据也从opentsdb hbase迁移到elasticsearch里面。 目的 ? 只为更好的实时聚合计算,并快速的展现业务报表,展现监控数据。
文章写的不是很严谨,欢迎来喷,另外该文后续有更新的,请到原文地址查看更新.
先说下kibana方面的事,kibana往往在展现一条数据的时候效果是完美的,尤其是kibana4那种清淡的绿色让人心旷神怡。 但很多时候我们要做多维度数据图表展现, 这地方kibna貌似没有做图表样式的优化。当很多条数据拥挤在一起时,很难区分出每个点的数值,换句话说很不直观。 另外kibana更加适合日志类型的展现, 虽然他也可以kv结构,但配置起来有些麻烦.
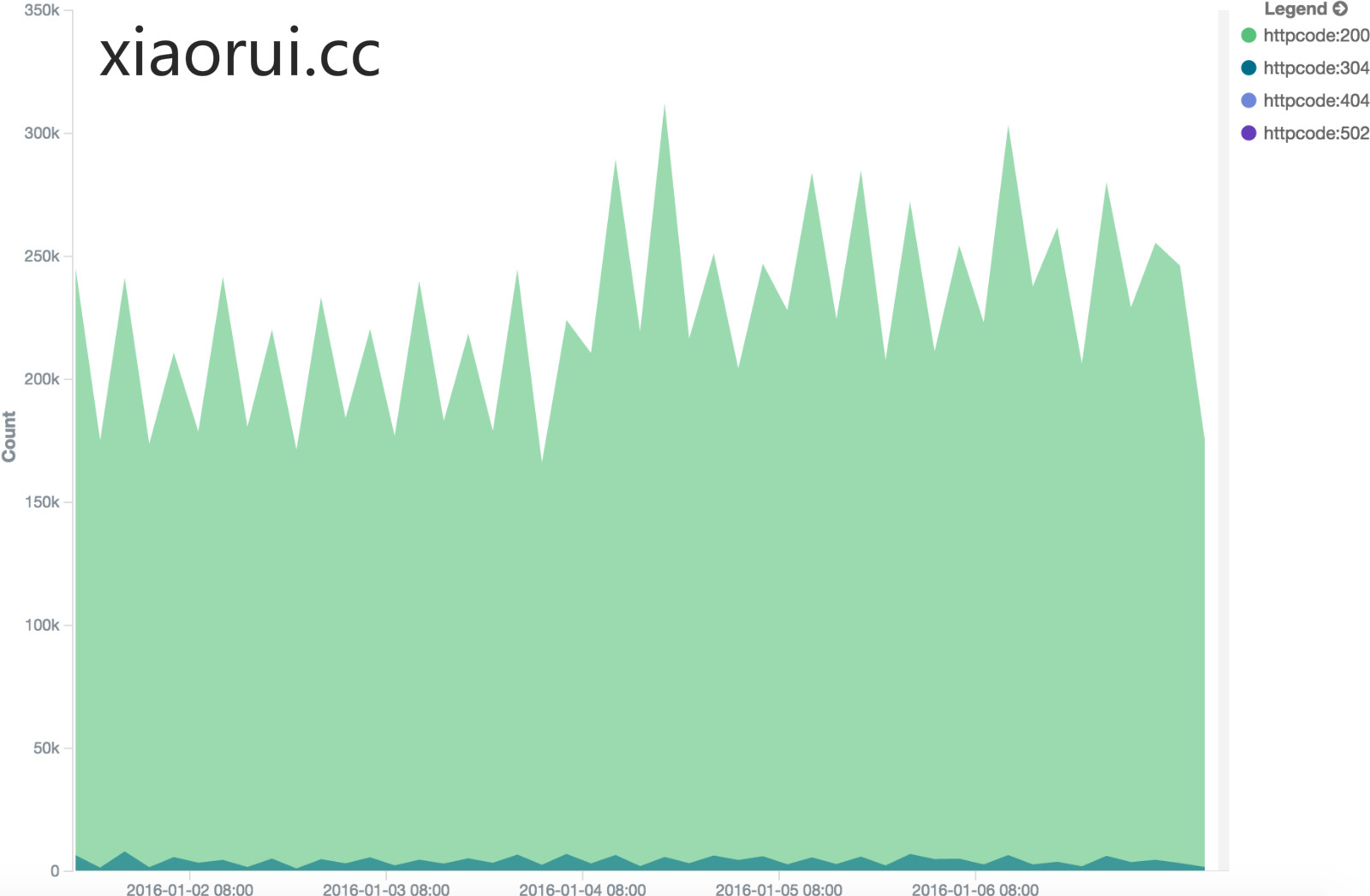
另外kibana没有管理的api, 只能点来点去. 在kibana4.x的版本里集成了一个node服务端,但就最新的版本来说,他只是被当成一个静态服务器使用,没有更多的动态功能,比如权限管理。
去年写过一个文章专门描述kibana批量操作的问题. 当时的需求是有很多的图表及dashboard面板. 如果靠着手动点击不怎么现实. 后来发现Kibana的数据都存在elasticsearch里,
所以写了个较完整的python模块去直接操作elasticsearch,其实就是个.kibana的配置文件. 因为api跟公司的业务耦合一起了,所以暂不方便开源出来。 kibana es批量操作,http://xiaorui.cc/?p=1570 有兴趣看看.
kibana没有权限管理,用户管理。 大多数人都是使用nginx做为kibana的基本密码认证(HTTP Auth Basic),这样做也能保证一定的安全,但毕竟不和规矩.
刚才说的kibana的槽点, 在grafana里是可以解决的。对比kibana4来说,grafana支持更多数据源. grafana以前的1.x版本就支持不少的时序数据库,比如最风光的influxdb,适合大集群大存储的opentsdb, 单机存储的graphite . 后有老外把zabbix扩展到grafana里。现在新版的grafana也支持elasticsearch了。 感叹,elasticsearch是越来越火了,功能也越来越丰富.
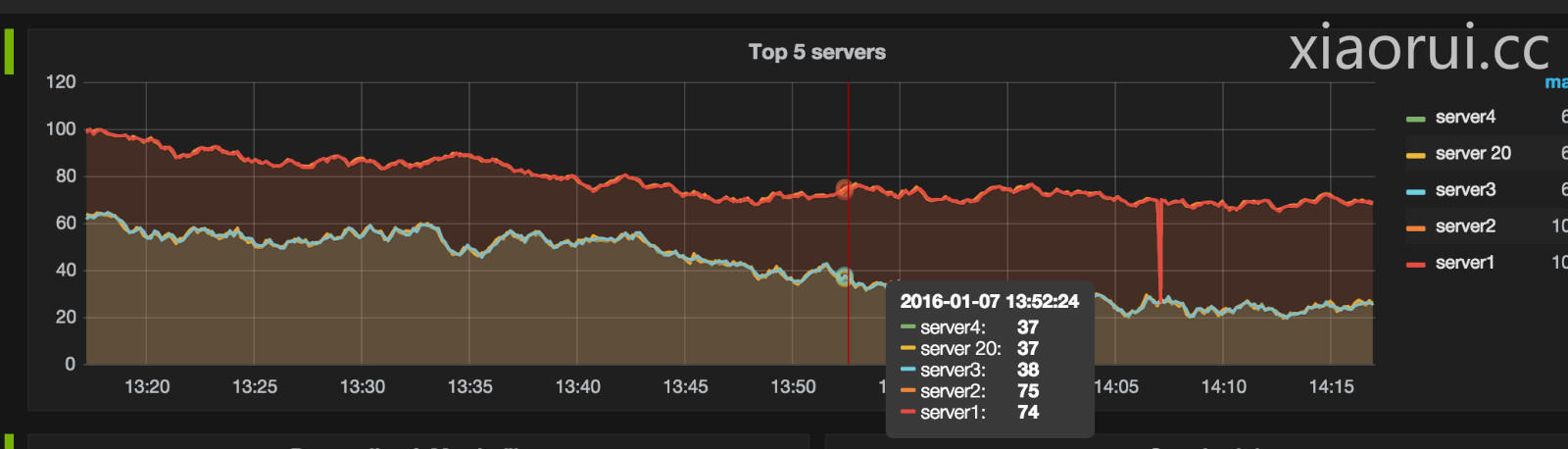
grafana官方有不少语言的控制api, 只是没有python的。 在github中找到一个老外开源的grafana python api , grafana_api_client。 grafana docs有详细的api使用文档,有兴趣的朋友看看.
from grafana_api_client import GrafanaClient
client = GrafanaClient(("admin", "admin"), host="127.0.0.1", port=3000) # or, alternatively:
client = GrafanaClient("yourapikey", host="127.0.0.1", port=3000)
client.org()
#{"id":1,"name":"Main Org."}
client.org.replace(name="Your Org Ltd.")
#{"id":1,"name":"Your Org Ltd."}
client.dashboards.db.create(dashboard={...}, overwrite=False)
#{"dashboard": {...}, "overwrite": False}
kibana vs grafana功能对比:
单纯的日志,我还是推荐大家把日志报表放在elk ( kibana )里面的,因为kibana的模板有针对日志的search语法,有的query_string ,match 全文匹配。 如果kibana本身的搜索需求不能满足你,你可以使用JSON Input来实现自定义的搜索语法。 grafana用的则都是类似term这样的精确匹配.
监控方面的数据,尤其是那种metrics监控类型数据,非常适合用Elasticsearch Grafana组合. 题外说下,对于监控数据的落地我们走了不少的坑,从rrdtool, mysql, Influxdb, OpenTsdb到最后的Elasticsearch,其中的db选型失败也有我们自身能力的原因. Opentsdb没有想象中的那么好.
修正上面的说法,grafana的新增图表里面,会有elasticsearch和ES LOG两项. 对于metric names字段也是有正则匹配的模式,对于具体的value是可以模糊匹配,正则匹配,lucene全文索引匹配规则.
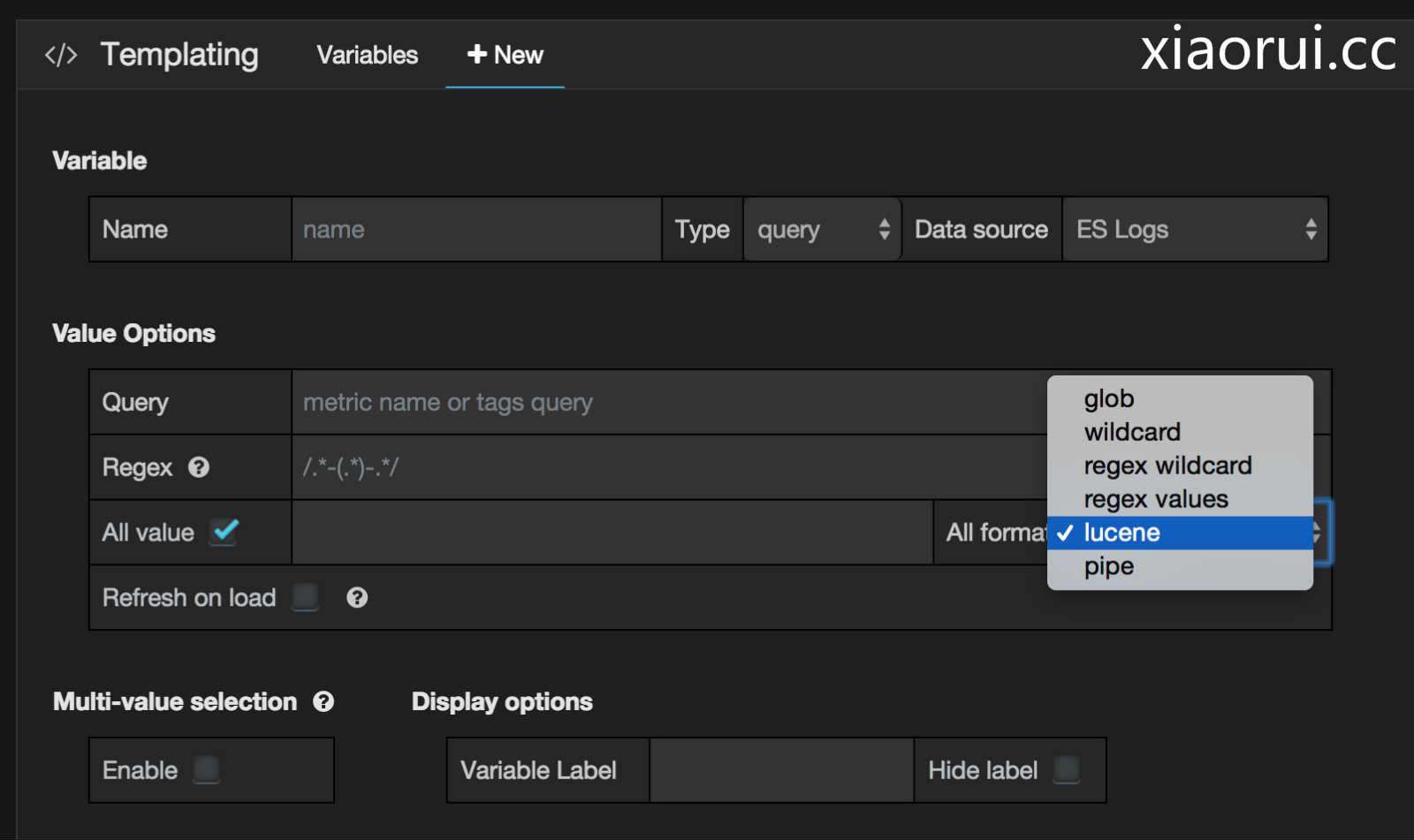
原谅我桀骜不羁说kibana的不是,我这也是因爱生恨. 我用过kibana的好多版本, 我曾经在Kibana Issue问过他们为什么不把kibana的node.js后端做的丰富一点,作者给我的答复是, 他们本来就不想做太复杂,只是想单纯的做前端图表显示.
END.
问: 不知道监控数据存储为什么最后选择的是Elasticsearch 不是Influxdb
答: 首先我没有否定influxdb的意思. 我曾经多方面测试过influxdb可能会存在的瓶颈,当他的数据在超过几百G的时候,绕开cache做随机range聚合查询会发现性能有明显的下滑,有些难以忍受.


Q:ELK中能在哪个阶段做算术运算,比如有连续两条数据,我想做前后两者相减再除以他们之间的时间差,最后再给个标签给它成为一个新的filed
grafana datasource 怎么配置呢
es 越来越火了
请问,es节点是3个,grafana datasource那里应该怎么配置呢?
kibana里, 一直有个时间戳多8小时的问题, UTC…
这个是深坑
经验总结的不错,我们也在做业务报表系统,广告已点 :)
感谢! 哈哈
感谢分享。。
infludb的集群性能不靠谱,在写压力大时会出现各种传输error
不知道,监控数据存储为什么最后选择的是Elasticsearch 不是Influxdb
首先我没有否定influxdb的意思. 我曾经多方面测试过influxdb可能会存在的瓶颈,当他的数据在超过几百G的时候,绕开cache做随机range聚合查询会发现性能有明显的下滑,有些难以忍受.
哦,是这样,那目前对于我们的影响比较小.