
最近有看redis server的源码,想实现一个多线程的版本。在大多数场景下单个redis实例是满足需求的,但如果ops的量级过十几万,连接数超过几k,会有明显的cpu接近跑满情况。 时常会想起以前维护几百个redis实例的场景,很是痛苦… 痛苦的原因,主要因为没时间把redis服务抽象成自动化和资源化,后面会因为异常和增减节点而头疼。 后来,我们总结了下,redis本身是很稳定的,异常问题是出在我们项目设计上,比如 热点key问题,数据压缩,垃圾数据 …
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新. http://xiaorui.cc/?p=4568
可能的问题
由于redis的worker线程只有一个,跟client及数据结构打交道的工作线程就一个。 一个线程那么也就只能跑单核了。 另外你有大量的key插入及批量命令的注入会发现cpu也是很高的,大量的key插入会导致rehash(dt就是个大dict),zrange区间查询是从skiplist和hash里取数据,hgetall操作big key,时间复杂度也不低。这类情况都是在main worker thread来实现的,那么必然会让其他的client阻塞。介于这么一个情况,所以大胆的想做下redis server多线程方面的设计。
有看过微博和阿里的redis设计方案,也看过唯品会多线程redis的源码实现。 他们在文档中都有提过,线上业务的redis3.x 单实例的qps最多也就十几万的,这个数据不管在阿里和唯品会的分享中都有提过的。 我这边一个分布式系统中redis的ops也在这个量级左右,但随着后期的集群的应用,细致的迁移slot分层,在业务层解决hot key热点问题后,单个实例也就3w的ops。
道听途说
我在阿里云栖大会里看到了,有关阿里redis的性能介绍。阿里多线程的redis说是可以到百万级别的qps,唯品会说是可以干到30w的qps… 对的,单个实例… 先不考虑硬件问题,设计架构层面是否能支撑这个数据,这个就不知道了,毕竟大多数公司所谓的性能测试都有点… … ( 先前用过基于leveldb封装的influxdb,当时看到benchmark的测试数据很是经验,后来在各种机器上及调优下都没测出这个结果,最后在influxdb的邮件列表有个前员工爆出原因。这结果是在100%命中cache下的指标… … 你懂得)
另外,redis qps 和 ops,有不少人搞混,redis info的ops说的是执行的命令,qps这个数据在redis server中现存的统计数据里是无法得到的,咱们常说的qps是说从客户端到redis端,再返回客户端的流程为一个QPS。 QPS一般是由外部测试所得的。 你有可能一次pipeline十几个条命令,但是这一次请求才算一个qps,但是在redis内部来说,算十几个ops,这ops有点像TPS,事务数。
多线程redis的设计,我们应该最关注的是两个方面,一个是锁,数据同步。 另一个是网络框架…
网络框架
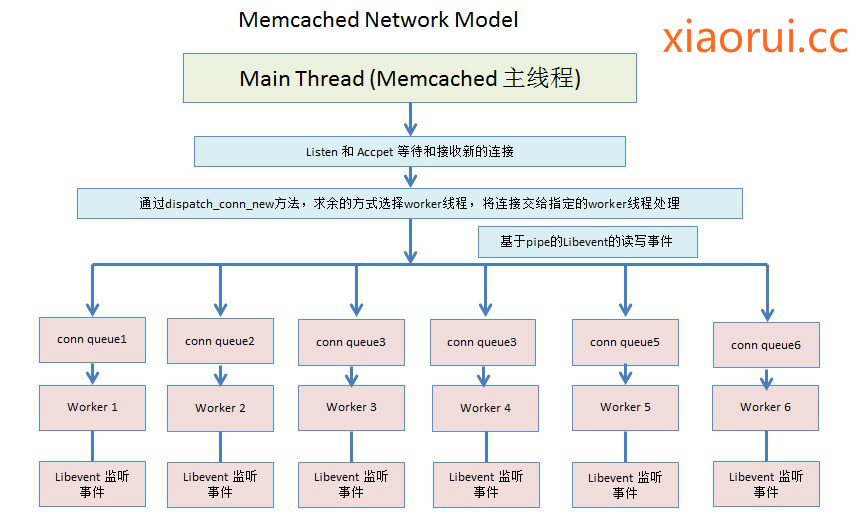
先从网络框架说起,我们完全可以参照memcached的网络模型。据我所知,唯品会的redis模型是参照memcached,邮件列表里一些国外的大厂也有这么干的。 思路很简单,由master来listen fd的监听,然后调用sendmsg把accept的client fd传给worker… 特意说明下sendmsg,socketpair都是可以的传递fd文件描述符。
先来一张简单易懂的图,他跟nginx通过算法策略拿accept锁的方法有些不一样,memcached是由master主动分配的,而nginx是worker竞争获取一个accept lock,当然通过设计上的优化,减少了锁竞争问题。
(简单图)
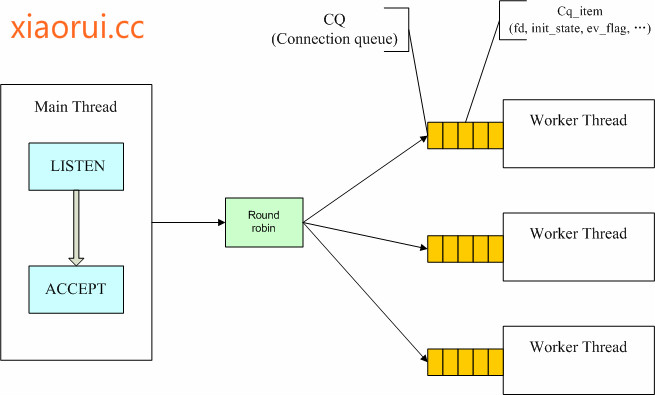
在这种模型下摸个工作线程都有一个event base,(这里跟nginx一样的)多线程不是监听同一组client fd事件,而是各自监听是不同的fd! 这里很重要的! master会把client fd按照rr轮询的方式分配给一个线程的cq队列里,那么worker thread如何得这个cq_queue的状态,得知有任务到来的状态 !
我们可以给cq_item分配一个pipe管道,然后把这个pipe管道也放到event base做监听,还需要pipe做一个跟function的映射,说白了就是 callback。
(复杂图)
线程安全和锁
涉及到多线程的读写,那么必然就有个线程安全的问题。为了避免多线程在同一块区域读写,我们可以设计多个db,另外还需要使用分段锁,每个db对应一个锁。redis启动的时候就抽象出几个是锁,当请求来时,根据key的hash去试图拿不同的db锁。 分段锁的锁粒度降低到db维度,对比单一的锁减少了锁等待…. 那么有没有必要做到单个key级别的锁呢? 个人觉得没必要…
另外还需要注意死锁的问题,我们可以在业务端顺序化流程,减少因为多线程下资源的互斥造成死锁情况。 但这样还是有死锁的产生,我们可以分解pipeline和multi事物的命令集,执行完一个操作后,立马释放锁
持久化的问题
另外发现阿里的redis不仅做了多线程,而且在这基础上修改了持久化的结构,抽象了一个hash db的概念,这里的hash db对用户无感,每个db同样对应一个lock,只为线程安全。 但在持久化的时候,只需要lock一个逻辑db,然后持久化,这里避免了redis rdb fork cow的内存多一份问题,但是会db lock,这样方式必然是阻塞的。 其实我们参照一下redis rehash的思路,做成渐进方式。 通过scan的方式来持续入库,有个数据不一致的问题,因为是分片入库,可能后面数据变动了,业务数据状态不一致。
当然用redis不会考虑这类的一致性问题,如需要可以在业务上规避这类异常。另外,异常崩溃的事件的出现几率很低,所以简单粗暴才是硬道理。
那么对于持久化有这么三种方法:
第一:redis server默认的cow,多了一份内存,copy on write是基于进程的,没法线程操作。 线程的堆栈是从进程空间获取的。
第二:渐进方式持久化,最大的方式节省了内存。
第三:持久化锁住相关的逻辑db ?没必要… redis的应用应用场景大多是cache,穿透缓存的后果可是不能容忍的。
没有写完….

