
概念分析
LFU(Least Frequently Used)即最近最不常用.看名字就知道是个基于访问频次的一种算法。以前写过几篇关于用python实现lru算法的模块,有兴趣的朋友可以看看。 LRU是基于时间的,会将时间上最不常访问的数据给淘汰,在算法表现上是放到列表的顶部;LFU为将频率上最不常访问的数据淘汰.既然是基于频率的,就需要有存储每个数据访问的次数.从存储空间上,较LRU会多出一些持有计数的空间.
LFU算法认为”如果数据过去访问频率很高,那么将来被访问的频率也很高“. 其实我个人对于缓存用的最多的是 Lru和Fifo ,LFU更加偏向于随机性比较大的场景。
我擦,最近爬虫很是凶猛呀 标记下文章的原文 http://xiaorui.cc

下面的图我是从别人那边偷来的….别打我
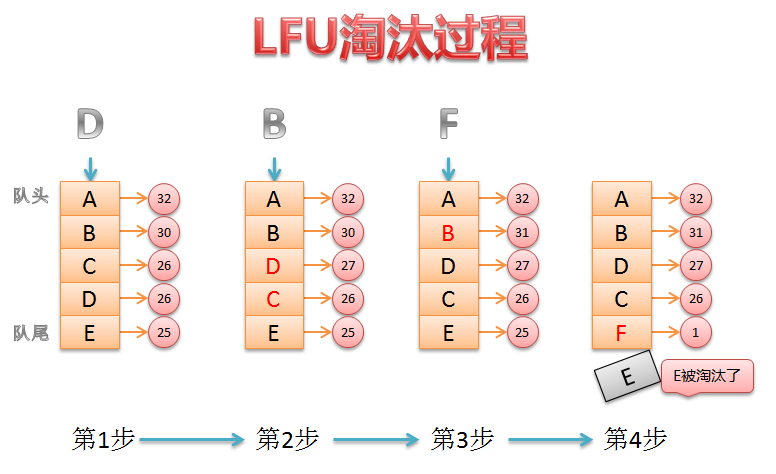
下面简单讲解一下:
- 假设我们的lfu最大的存储空间控制为5个,此时访问D,D现在的访问频率计数是26;
- 访问D后,D的频率+1,也就是27了。 此时需要调整缓存池数据需要重新排序,D和C交换;
- 访问B,B的频率+1,由于A的频率仍然比B大,所以不需要调整;
- 当新数据F插入缓存池之前,由于已经空间满了,需要干掉一个! 因为E的频率最低,故淘汰E,将F插入缓存池,缓存池重新排序,F放到队尾.
3.优略分析
【命中率】
命中率方面还是要看你的应用的场景 大多数的场景下,一旦访问内容发生较大变化,LFU需要用更长的时间来适应,因为他是往队列的下面塞入,如果一定时间内对于新数据的访问频次量不够的话,后面再继续的不断的推入新的数据,根据Lfu的算法,被干掉的肯定是那些刚刚被推进来的,还没有被多次访问的那堆数据了。(历史的频率记录会是这些污染数据保持较长的一段时间) ,这也是为啥大多数人用Lru的原因。
【复杂度】
需要维护所有的访问记录的频率数据结构,实现较LRU复杂.
【存储成本】
需要维护所有的访问记录的频率数据结构.
【缺陷】
仅仅从最近访问频率上考虑淘汰算法,可能会淘汰一些仍有价值的单元.内存和性能消耗较高.
下面的是用python实现Lfu缓存算法的装饰器。 脚本里面增加了随机的访问的概念统计,Lfu非常适合这种随机性比较大,跟时间没太多关系的缓存。代码我已经推送到了pypi里面,有兴趣的朋友可以直接安装
pylfu的安装: pip install pylfu
import collections
import functools
from itertools import ifilterfalse
from heapq import nsmallest
from operator import itemgetter
class Counter(dict):
'Mapping where default values are zero'
def __missing__(self, key):
return 0
def lfu_cache(maxsize=100):
'''Least-frequenty-used cache decorator.
Arguments to the cached function must be hashable.
Cache performance statistics stored in f.hits and f.misses.
Clear the cache with f.clear().
http://en.wikipedia.org/wiki/Least_Frequently_Used
'''
def decorating_function(user_function):
cache = {} # mapping of args to results
use_count = Counter() # times each key has been accessed
kwd_mark = object() # separate positional and keyword args
@functools.wraps(user_function)
def wrapper(*args, **kwds):
key = args
if kwds:
key += (kwd_mark,) + tuple(sorted(kwds.items()))
use_count[key] += 1
# get cache entry or compute if not found
try:
result = cache[key]
wrapper.hits += 1
except KeyError:
result = user_function(*args, **kwds)
cache[key] = result
wrapper.misses += 1
# purge least frequently used cache entry
if len(cache) > maxsize:
for key, _ in nsmallest(maxsize // 10,
use_count.iteritems(),
key=itemgetter(1)):
del cache[key], use_count[key]
return result
def clear():
cache.clear()
use_count.clear()
wrapper.hits = wrapper.misses = 0
wrapper.hits = wrapper.misses = 0
wrapper.clear = clear
return wrapper
return decorating_function
if __name__ == '__main__':
@lfu_cache(maxsize=20)
def f(x, y):
return 3*x+y
domain = range(5)
from random import choice
for i in range(1000):
r = f(choice(domain), choice(domain))
print(f.hits, f.misses)


我想不到用lfu的场景
我给你发邮件了,小哥看一下哈 。 文章不错,看过你以前写过的lru模块