
最近在折腾metric监控的东西,再加上到这里后逼格提升了不少,所以想写点关于构建metric系统的文章,用来装逼,找喷… …
能不能别把文章转走,标记下原文地址 xiaorui.cc
我自己是个臭屁的人,尝尝装逼为乐!正题开始, 我工位左面的那个同事以前是在阿里和高德负责过开发和改进监控系统的。 说实话他对于从头开发监控系统和常见系统的优缺点比我这个曾经专业的运维了解的多的多…. …. 尤其是关于数据量到了一个级别后,架构的调优及其数据落地存储的改进… … 话说,我以前也是开发过监控系统的人,虽然有打杂的嫌疑,但是一直都没有他遇到的那个量级所能遇到的问题和考虑到的问题…. ….
有一种监控叫做metric监控平台,看过我以前文章的朋友,应该清楚metric监控的意义,他其实更多的不是在于报警,而是在于性能的监控. 如果你非要做成包含报警,那我也没得说…. O(∩_∩)O~

opentsdb用的是hbase做底层的存储,没有坏点的问题 。如果你用mysql存数据,在数据量大了后,会出现各种各样的问题,这是很烦恼的, 以前就经常针对mysql进行分库分表,还要自己改程序加一层关于key的分片。 十分的蛋疼…. … 如果你用的是Mongdb这样的文档型数据库,那问题也不小,虽然mongodb的副本集可以很容易的扩展成集群,但是他的坑,是你需要了解的…. …
前段时间用了Influxdb时序数据库,是golang语言开发的,底层数据存数用的是leveldb或者是rocksdb, 但是还不支持存储hbase,跟influxdb有过邮件的交流,他们没有考虑hbase的原因是不太想把监控系统做的太复杂,毕竟像leveldb和rocksdb安装特简单,hbase不是那种随意rpm就可以了,还是需要整个hadoop集群进行配合的。
还有ganglia是个不错的东西,一直也很喜欢… … rrdtool是可以预先聚合计算的,这样极大的提高了mean效率. 缺点就是因为是用rrdtool存入的,不方便做分布式,当然你可以把rrdtool分离在不同的server上,我个人懒的动弹,所以我放弃… …
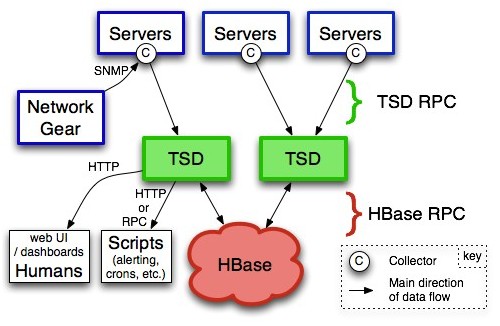
shell 模式很简单….
cat >loadavg-collector.sh <<\EOF
#!/bin/bash
set -e
while true; do
awk -v now=`date +%s` -v host=`hostname` \
'{ print "put proc.loadavg.1m " now " " 1 " host=" host;
print "put proc.loadavg.5m " now " "2 " host=" host }' /proc/loadavg
sleep 15
done | nc -w 30 host.name.of.tsd PORT
EOF
chmod +x loadavg-collector.sh
nohup ./loadavg-collector.sh &
下面的是github中使用potsdb模块操作的opentsdb的一个demo ~
import potsdb
# minimum is hostname. port is defaulted to 4242:
metrics = potsdb.Client('hostname.local')
# all options:
metrics = potsdb.Client('hostname.local', port=4242, qsize=1000, host_tag=True, mps=100, check_host=True)
# qsize: Max Size of Queue
# host_tag: True for automatic, string value for override, None for nothing
# mps: Metrics Per Second rate limiting
# check_host: change to false to skip startup connectivity checking
# Bare minimum is metric name, metric value
metrics.send('test.metric2', 100)
# tags can also be specified
metrics.send('test.metric5', 100, extratag1='tagvalue', extratag2='tagvalue')
# host tag is set automatically, but can be overwritten
metrics.send('test.metric6', 34, host='app1.local')
# waits for all outstanding metrics to be sent and background thread closes
metrics.wait()
大家可以看看potsdb的python源码,其实真的很简练,没啥东西…. …. 主要就是利用socket模块进行数据的send 。
sock = None
retry_line = None
#while (daemon == False and not done.is_set()) or parent_thread.is_alive():
while not ( stop.is_set() or ( done.is_set() and retry_line == None and q.empty()) ):
stime = time.time()
if sock == None:
sock = _mksocket(host, port, q, done, stop)
if sock == None:
break
if retry_line:
line = retry_line
retry_line = None
else:
try:
line = q.get(True, 1) # blocking, with 1 second timeout
except:
if done.is_set(): # no items in queue, and parent finished
break
else: # no items in queue, but parent might send more
continue
try:
sock.send(line)
写不下去了,要出去健身了,回来再写 ~


好文章,啥公司呀?
呵呵