
那么话说,InfluxDB的查询语法是很给力的,很像SQL语句。下面我会一一介绍下,常用的InfluxDB里面常用的SQL语句。 话说 InfluxDB给与的搜索条件还是很丰富的,有时间分析下 他落地在leveldb的数据结构。
哎,最近爬虫有些猛,标记下原文地址 xiaorui.cc

表名都可以正则
select * from /.*/ limit 1
查询一个表里面的所有数据
select * from cpu_idle
查询数据大于200的。
select * from response_times where value > 200
查询数据里面含有下面字符串的。
select * from user_events where url_base = ‘friends#show’
约等于
select line from log_lines where line =~ /paul@influx.com/
按照30m分钟进行聚合,时间范围是大于昨天的 主机名是server1的。
select mean(value) from cpu_idle group by time(30m) where time > now() – 1d and hostName = ‘server1’
select column_one from foo where time > now() – 1h limit 1000;
select reqtime, url from web9999.httpd where reqtime > 2.5;
select reqtime, url from web9999.httpd where time > now() – 1h limit 1000;
url搜索里面含有login的字眼,还以login开头
select reqtime, url from web9999.httpd where url =~ /^\/login\//;
还可以做数据的merge
select reqtime, url from web9999.httpd merge web0001.httpd;
下面再说下数据的汇聚,聚合啥的。
Aggregate Functions
InfluxDB contains a number of functions that you can use for computing aggregates, rollups, or doing downsampling on the fly. These are always used in conjunction with a group by time(…) clause. If no group by clause is given, then a default will be applied from the start of the series to now().
Count
COUNT() takes a single column name, and counts the number of points that contains a non NULL value for the given column name in the group by interval.
SELECT COUNT(column_name) FROM series_name group by time(10m) …
Min
MIN() returns the lowest value from the specified column over a given interval. The column must contain int64 or float64 values.
SELECT MIN(column_name) FROM series_name group by time(10m) …
Max
MAX() returns the highest value from the specified column over a given interval. The column must be of type int64 or float64.
SELECT MAX(column_name) FROM series_name group by time(10m) …
Mean
MEAN() returns the arithmetic mean (average) of the specified column over a given interval. The column must be of type int64 or float64.
SELECT MEAN(column_name) FROM series_name group by time(10m) …
这里提一下,Influxdb和rrdtool最大的区别在于,rrdtool是可以做汇聚 聚合的,也就是预先的计算,而不是等准备要获取的时候,再进行汇聚的计算。 哎 ···
我这里做了一些压力的测试,Influxdb在5s内100个线程的插入和平均数的计算,进程占用了150% …. 对的,是150%左右。 io方面倒是很小,内存方面也不是很大。
记录了 求平均值的消耗时间,基本是2s左右。 个人觉得还是可以忍受的。
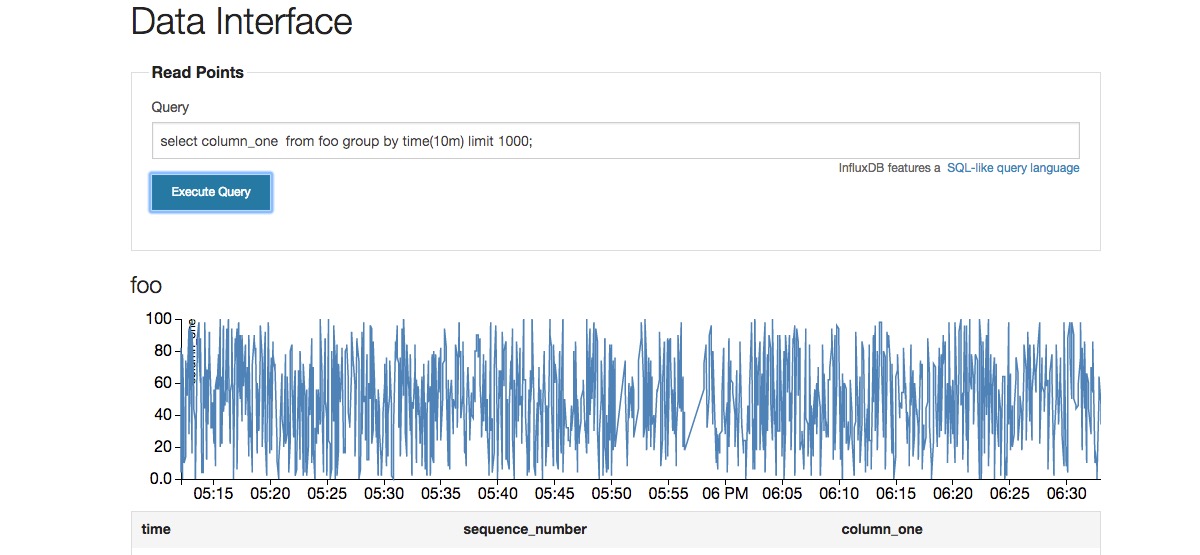
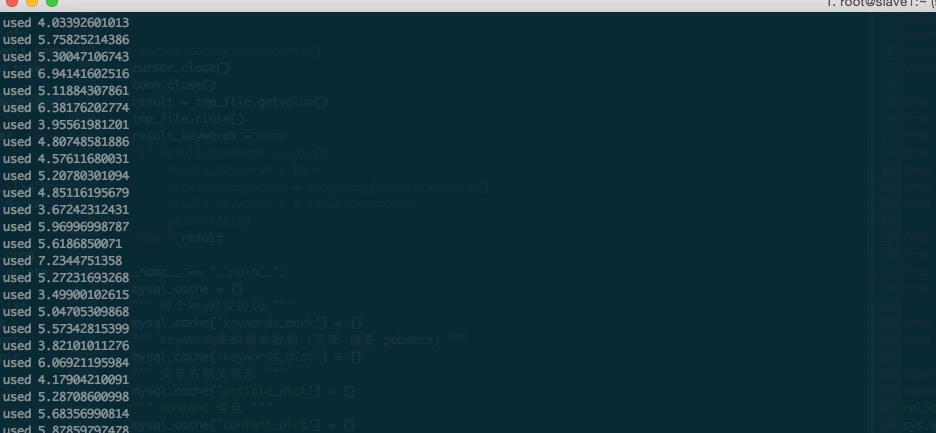


这玩意性能不行
哥们有详细的测试报告么?
我会针对InfluxDB写个测试报告