
关于如何快速开发一套属于自己的运维监控系统。
(这次更多的是架构方面的,下次有时间会讲开发中遇到的头疼的问题,比如 数据间隔的时间优先级队列,历史数据hbase的使用,数据层面的缓存等等)
记得刚入行的时候,对于监控方面,用的是nagios和cacti,现在大多数中小公司好多都开始搞zabbix了,熟悉zabbix的人,知道他的性能的瓶颈其实主要还是在数据库上,尤其是zabbx_server 针对数据库一些不高效逻辑的查询和写入引起的。
同事针对zabbix开发也搞了半年了,和他交流了下,有很多的想法。 zabbix 有些查询完全可以从缓存里面取值,比如redis、memcached,不用非要从数据库里面来搞个消耗性能的大查询,有些监控是触发三次后,才真的去报警,这些可以暂时放到缓存里面,感觉在技术上不是难度,但个人看不太懂zabbix_server服务端的代码。。。 唉 ! 一些历史数据的查询可以放到mongodb来搞,可以做副本集还有mongodb做了索引后,速度是很快的。
原文地址,blog.xiaorui.cc
我在想,zabbix现在是个商业技术公司,他的收费方案,肯定会有这些相关的patch的。咱们这些用户看zabbix的源码有些蒙头,但是zabbix那些开发着,熟悉代码,没有道理解决不了数据库的问题。
这都是钱闹的,但是话说回来,人家给你开源了这么好的产品,你就偷着乐呵吧。
上面这是个人的吐槽,zabbix选用mysql还是有他的道理的,毕竟mongodb在一定程度上,还不算太稳定,虽然他很高效 。 对于各种链表的查询,mongodb表示他很难搞。 对于一些有可能造成表锁lock的sql,为什么不用个队列支撑。 同事看了下源码,对于批量的写入,zabbix是没有做队列的控制的。 这也是造成,为什么服务器到达 万级别 后,用zabbix总是时不时的出现问题的主要原因之一。
有朋友说,这可能是磁盘io的问题造成了锁,好吧,需要说明的是,我们已经换了高性 能的ssd,速度是比以前sas快好几倍,但问题依旧,每个月都会出现数据库锁死的问题 , 这让人甚是纠结。
圈子里交流了下,各自公司监控系统,二次开发的一般是nagios和zabbix开发,zabbix 的多点。 还有一些是用ganglia和graphite做的。但这两个着重与性能的监控,至于用来做触发告警,说实话他不在行! 官方是推荐他俩可以配合nagios来搞报警,但这有些麻烦。
这里讲解下,以前公司做监控系统的一些个案例和经验,这次主要关注点是架构,一些算法和具体的实现下次有时间再讲下。
先说下,什么是主动监控和被动监控。 看了国外一些监控开发的资料和国内监控公司的一些技术方案:
主动请求式是客户机把自己的监控信息主动发送给监控机,监控机只要接收这些信息处理即可。
被动探测式是监控机把监控请求发送到客户机,客户机接到请求把需要的监控信息返回给监控结点。
其实我有时候也觉得别扭,主动监控和被动监控,应该是可以互相定义的。 上面的是主流的说法 ! 也是zabbix官方的定义。 其实我个人真觉得别扭, 应该master到客户端,叫主动,从客户端到master叫被动 。 咱们也别搞特殊,也跟着zabbix那帮人这么叫吧。
因为它要不断的发请求去获取信息,所以,被动探测式会给监控机带来很大的压力!
这里简单阐述下nagios的监控,当我们启动Nagios后,它会周期性的自动调用插件去检测服务器状态,当然nagios有nrpe和nsca主动。同时Nagios会维持一个队列,所有插件返回来的状态信息都进入队列,Nagios每次都从队首开始读取信息,对比信息,然后进行处理后,把状态结果通过web显示出来。
最开始监控的框架:
开发的语言是python,当时也有人建议用perl,为了以后好招人,还是采用了python,现在会perl的大多数都是资深的运维和开发了。这里是用gevent撑起并发,redis\zeromq的mq通信,tornado做的web,mysql做的库,微信做的报警。
请认准原文地址,blog.xiaorui.cc
当时遇到了几个问题,再用zeromq的时候,Req/Rep模式下,如果rep端recv后崩溃,req端需要重新的绑定conn,当时真心搞了很久。
还有一个问题,pubsub的时候,虽然虽然针对sub端的ping机制是正常的,但是数据还是无法真的接收数据。所以这个时候,间隔性的探测他是否可以真的ok。
zeromq有些理想化了,不知道现在zeromq的版本有没有搞定网络异常引起的问题。zeromq在网络环境很好的情况,他是很给力的,但是网络不好的时候,经过测试还没有redis的pubsub来的实在。其实最初选用zeromq,也是因为他用法很全,在国外已经有些公司在用0mq做监控平台,zeromq有个push pull可以很好的做分布式的任务派发。
最后也不用那些封装的mq,直接用socket重新写。
下图的框架,性能瓶颈很明显,一直去主动抓数据,时常因为服务器和监控项目多而造成任务崩溃。
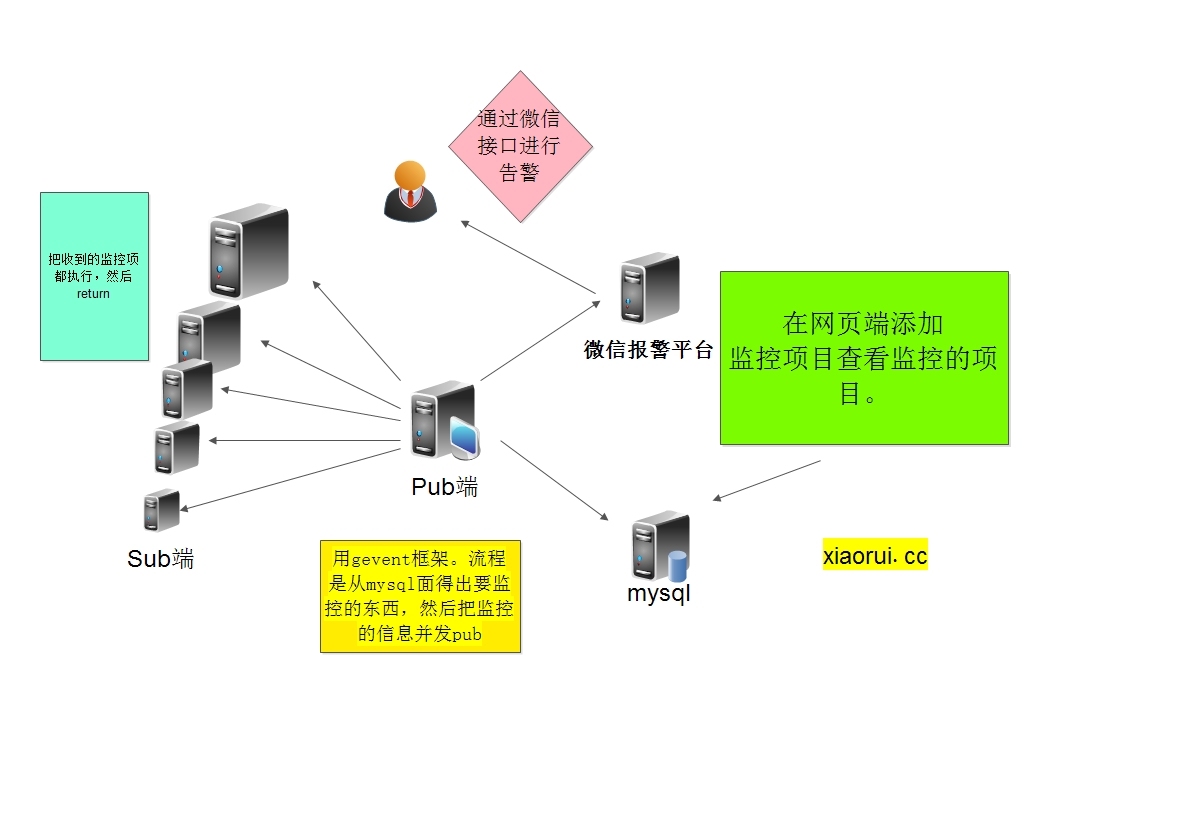
因为时常会堵塞,后期做了队列任务,防止行为的堵塞和超多任务进程崩溃,一个进程是吐任务,一个进程是执行任务。。。存储方面用了mongodb。 考虑到微信接口的不稳定,又加了邮件告警。
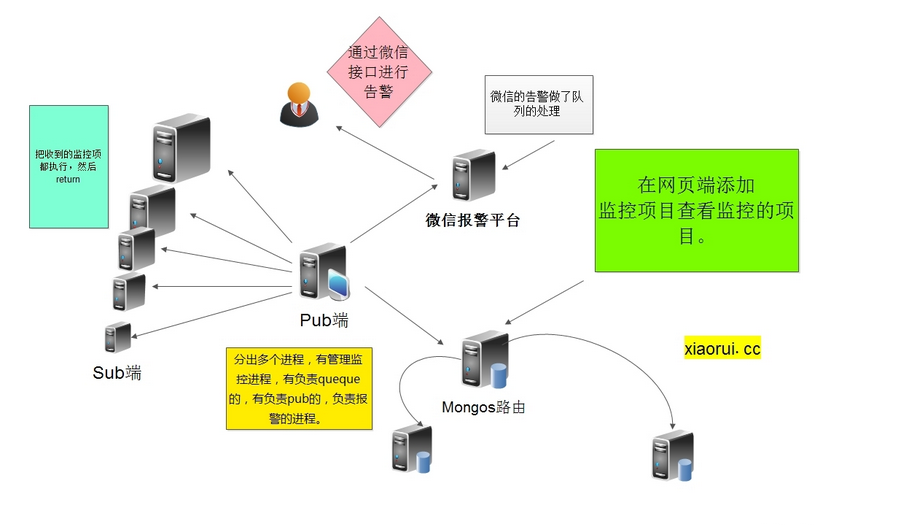
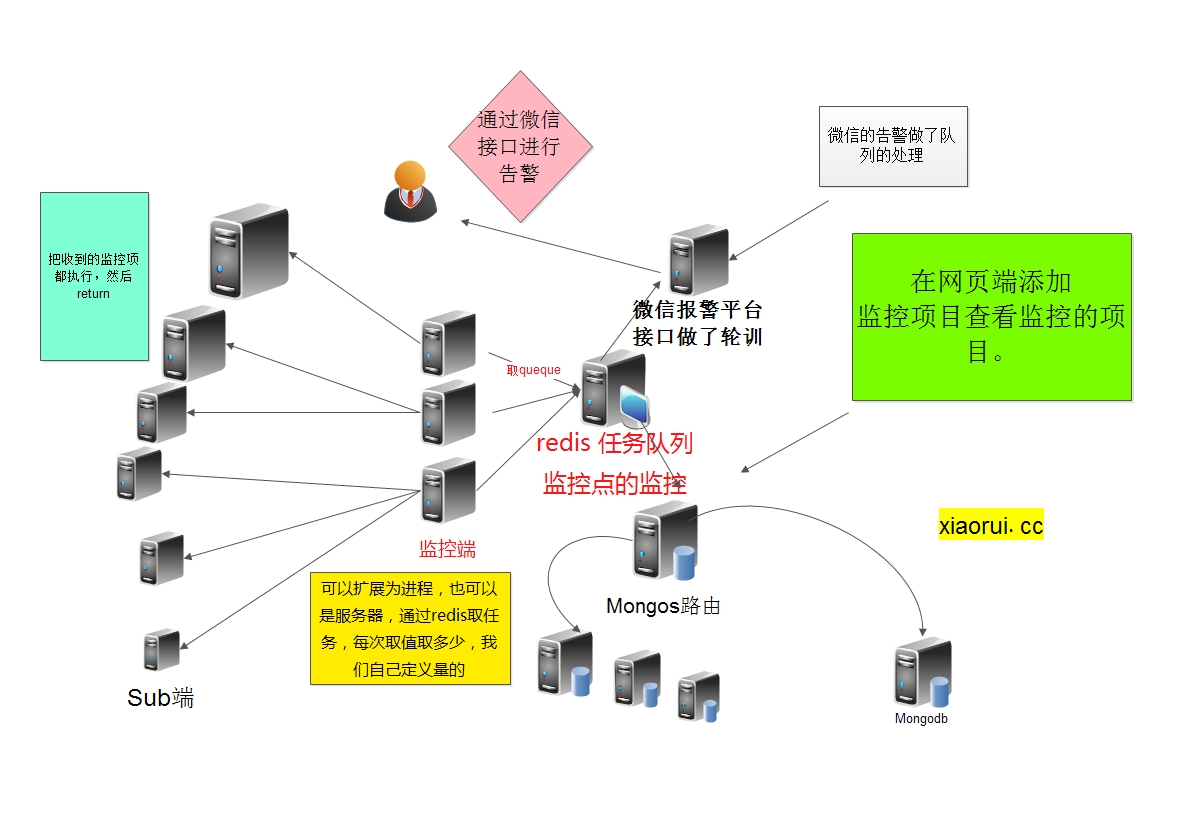
首先把监控任务的大队列的分离,不做进程间的queue通信了。现把redis独立做队列,并做了监控点的健康状态,分布式的监控点也多了几个,可以写成多进程,也可以是部署到服务器上。
微信的接口时常的出问题和发信的次数,所以用了多个接口进行轮训并状态检测。。。
有一部分的业务接入了实时监控,用的是websocket。 这里是客户端主动上报给监控端的。
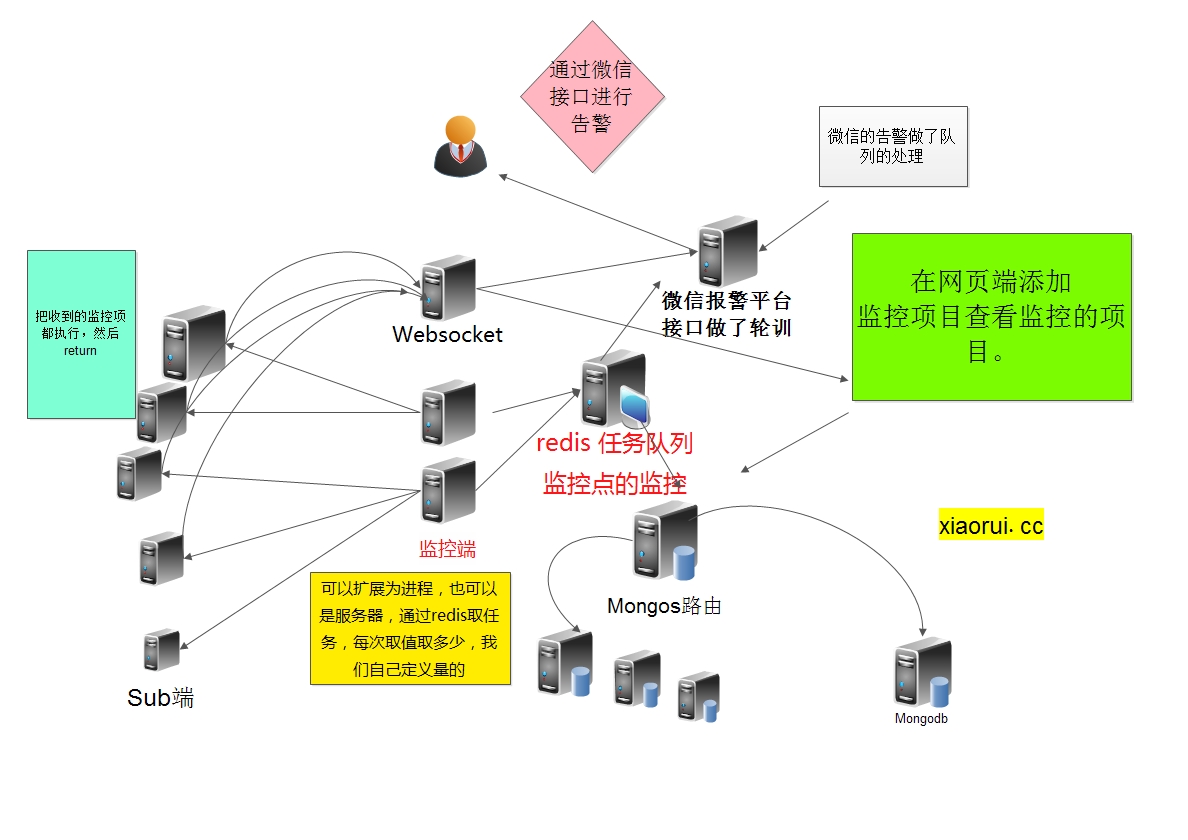
虽然通过redis扩展了几个伪分布式proxy节点,但是量大了后,还是会有性能瓶颈。大家知道为什么cacti的性能为啥这么低么? 就算用spine这个c扩展代替cmd.php还是地下,原因其实在于主动抓取的性能消耗上。
现在高性能的监控系统,都是支持主动发送数据的,比如 ganglia、graphite。完整的监控系统可以做到主动和被动两个方式并存,被动是探测监控客户端进程及状态的存活,主动是收集好的数据,发送给主监控端或者是proxy 。
agent启动的时候,会分离出两个进程,一个进程是每三分钟去监控接口获取最新的任务。还有一个进程把已知道的任务,一般是保存在yaml里面,取出来,一个任务一个线程的方式运行。当有检测到有新任务或者是改变了每个监控的间隔时间,这个时候注销或者增加一个任务线程。
服务端是接收信息并报警,如果有一个报警触发,但是这个任务是尝试三次之后,才触发的。这个时候系统会先遍历redis,如果redis没有才会,从数据库里面查询。
他还会遍历监控被动监控的任务。在监控条件里面可以指定谁去监控谁。
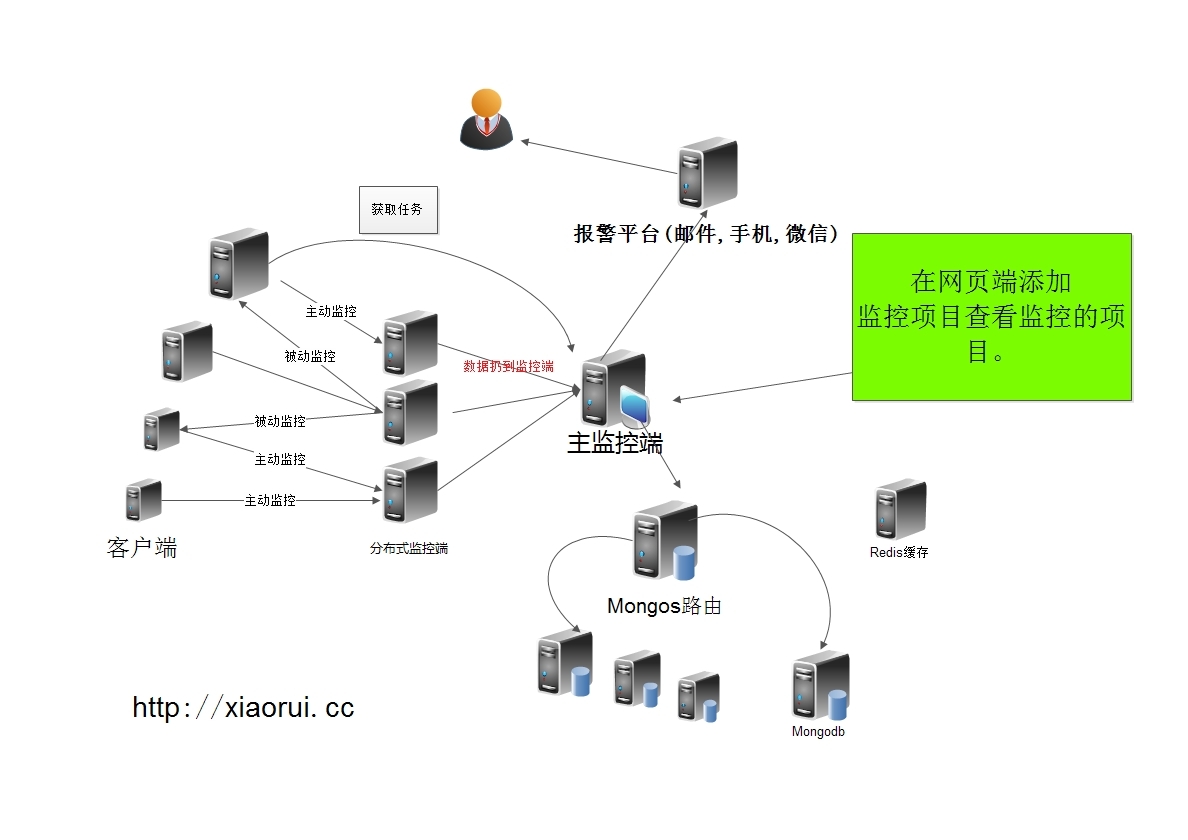
这里是学习zabbix的监控模型,定期去取任务列表,然后搞起。
sorry,这里标注下,原文地址: http://blog.xiaorui.cc
小总结:
监控是个大项目,这谁都知道。慢慢来,总能搞定的!咱们一步步的搞定它。 首先要确认监控的需求,实现页面管理及监控数据的展现,尤其是图表的展现。 先把简单的搞定了,再搞复杂的。后期要从各方面改进性能!
比如分布式集群的方式 有两种:
1 监控点去 ‘被监控点’ 取数据,在大量主机的情况下可能会慢,可以用队列来解决,也可以用gearman这样的任务派发系统来解决…
2 被监控点把数据主动给监控点。这个方法够简单,对于master来说压力也很小,但是对于开发人员来说缺点是告警的逻辑方面有点复杂。。。
尽量选用自己熟悉的框架,别一味着想用那些貌似很好用的框架,熟悉和评估后。在选用该框架,这算是我最大的感触了,每次做什么东西,都想用一些高大上的东西来包装下,最后受伤的是自己。
文章写的有些乱,请大家见谅! 有不对之处,请随意拍砖 !


牛逼,学习
我昨天晚上zabbix又出现了死锁,使用ids这个导致,妹的一直update,虽然有人说新版本升级解决了,但没有人准确的检测过,并且不到一定监控数据级,根本看不到很多问题。另外zabbix的监控方式,我一直使用proxy被动监控agent,然后proxy主动发数据给server,前者是为了监控主机后面有绿色灯显示帮忙看问题,另外使用zabbix_get来获取数据测试,后者是为了性能了。
好牛逼呀的样子!
架构哥