
前言:
前段时间跟一个滴滴的小哥聊了关于golang饥饿调度的话题,似乎大家觉得golang不会出现太长时间饥饿。 虽然大家看过golang sysmon抢占的源码实现,但不确定实际运行的结果是否跟预想的一致。 什么是饥饿调度,就是长时间得不到调度器来调度运行, 长时间算多长?这个时间是个相对值。 这里主要测试go在 cpu密集 和 非cpu密集 下的调度器表现。 当然,go里面做cpu密集计算是有些反社会的,go社区里也不推荐这么使用go,应该没人这么干吧 ?
该文章后续仍在不断的更新修改中, 请移步到原文地址 http://xiaorui.cc/?p=5251
我们知道golang是善于做的是服务端开发,大家写的服务端程序或多或少会有这些 network io, channel, disk io, sleep 调用什么的。这些的操作都会导致M跟G的解绑,并且M重新的获取可用G的调度。golang很多的syscall调用之前也会做一些解绑操作。也就是说,golang在正常的场景下似乎很难出现 同一组 MPG 长时间绑定的情况。另外,就算出现mpg长时间绑定运行,sysmon也会帮你做抢占,不管你是Psyscall, 还是Prunning状态。
sysmon retake() 是怎么抢占的?
起初runtime.main会创建一个额外的M运行sysmon函数, 抢占就是在sysmon中实现的. sysmon会进入一个无限循环, 第一轮回休眠20us, 之后每次休眠时间倍增, 最大不会超过10ms. sysmon中有netpool(获取fd事件), retake(抢占), forcegc(按时间强制执行gc), scavenge heap等处理. 这里只说 retake 抢占。
Sysmon会调用retake()函数,retake()函数会遍历所有的P,如果一个P处于Psyscall状态,会被调用handoffp来解绑MP关系。 如果处于Prunning执行状态,一直执行某个G且已经连续执行了 > 10ms的时间,就会被抢占。retake()调用preemptone()将P的stackguard0设为stackPreempt,这将导致该P中正在执行的G进行下一次函数调用时, 导致栈空间检查失败。进而触发morestack()然后进行一连串的函数调用,主要的调用过程如下:
# xiaorui.cc morestack()(汇编代码)-> newstack() -> gopreempt_m() -> goschedImpl() -> schedule()
golang的PMG怎么可能会一直处于Prunning状态,一般来说只有cpu密集场景才会吧…. (废话)
测试一把cpu密集场景
我先写了一个看起来是协程调度饥饿的例子。 为了高度模拟cpu密集的场景,脚本的逻辑很简单,spawn了10w个协程,每个协程不断的在循环计数, 协程初次和结束都会做一个atomic计数,好让监控协程支持大家都有被调度到。 当监控协程检测到大家都有被触发时, 退出.
另外,runtime.GOMAXPROCS为什么设置为 3 ? 运行的阿里云机器是 4core, procs设为3,在cpu密集场景下应该是cpu 300%. sysmon是在一个独立出一个M也就是线程去执行,这样避免了4个core下cpu 400%的情况下,在满荷载下ssh登陆都是个问题,导致无法进行其他操作。
# xiaorui.cc
package main
import (
"fmt"
// "net/http"
"os"
"runtime"
"sync"
"sync/atomic"
"time"
)
var (
startIncr int32
endIncr int32
)
const goCount = 100000
const plusCount = 10000
const callCount = 1000
func IncrCounter(num *int32) {
atomic.AddInt32(num, 1)
}
func LoadCounter(num *int32) int32 {
return atomic.LoadInt32(num)
}
func DecrCounter(num *int32) {
atomic.AddInt32(num, -1)
}
func main() {
runtime.GOMAXPROCS(3)
var wg sync.WaitGroup
startT := time.Now()
go detect(&wg)
for i := 0; i < goCount; i++ {
wg.Add(1)
go work(i, &wg)
}
wg.Wait()
elapsed := time.Since(startT)
fmt.Println("all exit, time cost: ", elapsed)
}
func detect(wg *sync.WaitGroup) {
defer wg.Done()
runtime.LockOSThread()
defer runtime.UnlockOSThread()
startT := time.Now()
for {
fmt.Println("time since: ", time.Since(startT))
fmt.Println("start incr: ", LoadCounter(&startIncr))
fmt.Println("end incr: ", LoadCounter(&endIncr))
fmt.Println()
if LoadCounter(&startIncr) == goCount && LoadCounter(&endIncr) == goCount {
fmt.Println("finish detect")
os.Exit(0)
break
}
time.Sleep(1 * time.Millisecond)
}
}
func work(gid int, wg *sync.WaitGroup) {
defer wg.Done()
var first = true
var localCounter = 0
for {
if first == true {
IncrCounter(&startIncr)
// fmt.Printf("gid:%d#\n", gid)
}
for i := 0; i < plusCount; i++ {
localCounter += 1
}
if first == true {
IncrCounter(&endIncr)
// fmt.Printf("gid:%d#\n", gid)
first = false
}
}
}
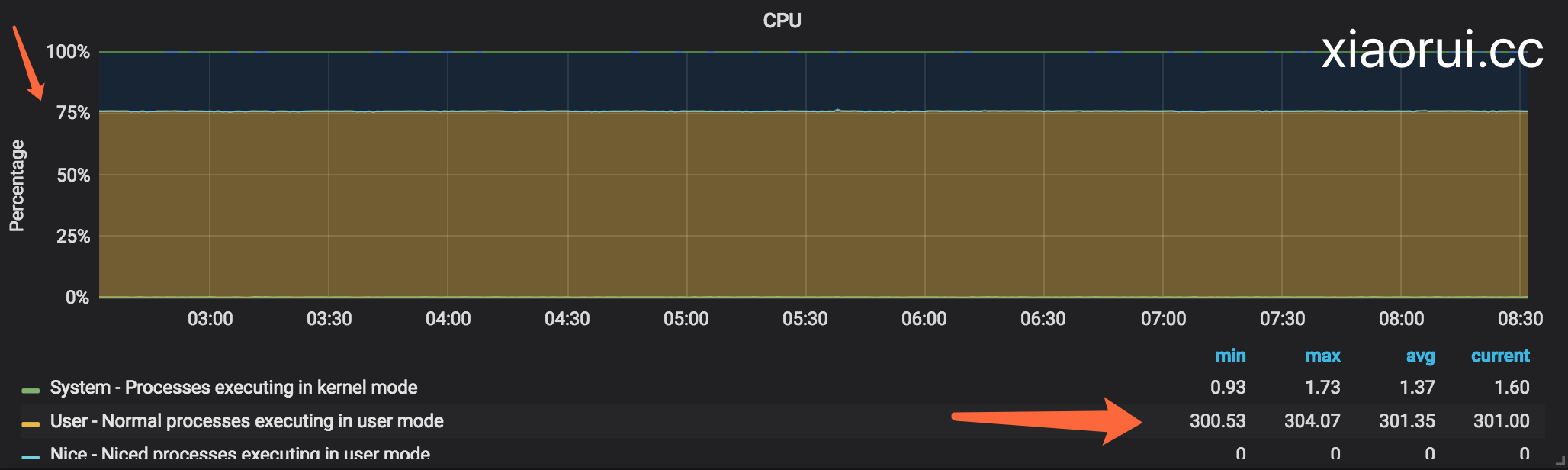
我们先看下CPU使用情况,跟我们想象中的结果是一样的几乎到了cpu 300%

程序一直扔在tmux后台跑, 在等了两天之后,发现10w个协程中还有一些goroutine没有被调度到, 也就是说 程序一直还在运行着。 下面的截图是6个小时的cpu运行状态,因为监控系统存储误操作,清理了数据, 丢失了2天的图表。
为什么没有触发抢占?
为什么没有被触发? golang runtime sysmon代码看起来是10ms会发生触发一次抢占请求, 当然,当M处于处于正在分配内存或者非抢占模式下或其他原因,可能会跳过这次抢占。 但,6个小时过去了,依然有一些协程没有被调度到,这是什么原因?
上面sysmon原理的时候有提过,retake会触发 morestack, 然后调用 newstack, 然后gopreempt_m会重置g的状态,扔到runq并且重新调度. 关键点是 morestack ? goroutine stack默认是2kb, 而然我们的goroutine被spawn之后,基本是自己玩自己的,没有调用其他的function, 那自然stack没啥变化了,所以说,没有发生抢占. runtime代码有说,morestack — > newstack才会真的触发抢占,我们加上一些有层次的函数调用, 让stack扩充不就行了。
使用了递归调用栈来迅速扩充stack大小。经过测试,下面的代码 在 2分钟 内 1w个协程都会被调度到的。
time since: 2m11.493924996s finish detect
刚才不是10w个协程么,怎么又缩减1w了… 因为10w协程长时间没动静….. 可以说,go在cpu密集场景下,会产生协程饥饿调度的问题,单看我们的测试结果,所谓的饥饿调度还是有的。在几k的协程下没有看到饥饿调度现象, 几w的协程还有可以看出一定程度的饥饿。
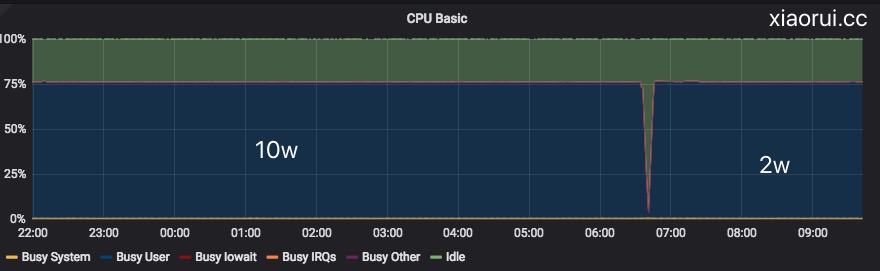
另外, 在CPU密集场景下,你调度器去均衡调度、抢占有个屁用呀,来回切换也有调度器自身产生的cpu消耗,还不如老老实实的处理完。要么加机器,要么优化算法。
# xiaorui.cc
func work(gid int, wg *sync.WaitGroup) {
defer wg.Done()
var first = true
var localCounter = 0
for {
if first == true {
IncrCounter(&startIncr)
// fmt.Printf("gid:%d#\n", gid)
}
for i := 0; i < plusCount; i++ {
localCounter += 1
}
if first == true {
IncrCounter(&endIncr)
// fmt.Printf("gid:%d#\n", gid)
first = false
// sysmon配合扩大函数调用栈来调度g.
curCount := 0
call1(&curCount)
}
}
}
func call1(cur *int) {
if *cur > callCount {
return
}
*cur += 1
call2(cur)
}
func call2(cur *int) {
if *cur > callCount {
return
}
*cur += 1
call3(cur)
}
func call3(cur *int) {
if *cur > callCount {
return
}
*cur += 1
call1(cur)
}
讲道理,讲调度
先简单的描述下调度流程,首先空闲的M跟可用空闲的P绑定,然后从P的runq里获取可用的G, 当G长时间执行的时候,会被sysmon做retake()抢占,被中断的G会放到全局队列的尾部. P的runq和全局的runq应该存有fifo的特性,按道理来说,应该都会被调度到呀, 只是时间长短而已… 我这里多次尝试过使用go tool pprof 或者 go tool trace 来追踪来分析原因,但又因为测试模拟了cpu密集,导致cpu打满的,所以 pprof和trace根本就调度不出来。。。
正常场景下, 10w个协程的调度情况
文章开头时,有说过 ! 正常场景很难出现MPG长时间绑定的情况,那么我们再来模拟测试下golang在正常场景下的调度表现 ?
方法1, 在cpu密集里加入一个time.Sleep(), 后台会调用gopark.
time since: 1.2353259s start incr: 100000 end incr: 100000 finish detect
第二个, 在每组计算完成后主动触发goshed
time since: 1.369199087s start incr: 100000 end incr: 100000 finish detect
第三个, 触发一个网络io操作.
time since: 5.389349861s start incr: 100000 end incr: 100000 finish detect
这三种方法在在一个合理的时间里, 10w个协程都被触发调度了. 具体的耗时时间大家可以自己测一把, 这跟机器的cpu hz是有直接关系的.
# xiaorui.cc
func work(gid int, wg *sync.WaitGroup) {
defer wg.Done()
var first = true
var localCounter = 0
for {
if first == true {
IncrCounter(&startIncr)
// fmt.Printf("gid:%d#\n", gid)
}
for i := 0; i < plusCount; i++ {
localCounter += 1
}
if first == true {
IncrCounter(&endIncr)
// fmt.Printf("gid:%d#\n", gid)
first = false
}
// 第一种方法
// time.Sleep 会产生调度,被goPark.
// 1s
// time.Sleep(1 * time.Millisecond)
// 第二种方法
// 使用GoSched切换调度
// 1s
// runtime.Gosched()
// 第三种方法
// 我们常见的有网络io的场景.
// 5s
// http.Get("http://127.0.0.2/test")
}
}
总结
这个所谓饥饿调度测试我承认有些无聊呀,也显得工作不饱和。实际工作中似乎除了机器学习,模型计算之外,似乎少有这样长时间cpu密集纯计算的场景了。但通过实验我们最少可以证明,golang retake抢占在 cpu密集场景下,上w 协程貌似不怎么管用 !
那么,在golang到底存不存在饥饿调度的问题? 正常使用golang的场景下,不会出现协程饥饿调度的问题。 但cpu bound场景下,饥饿调度现象还是有的。当然这里的测试方法还有待商榷,也不算严谨。
END.

