
吐槽
内存泄露 ? 内存暴涨 ? OOM ?
首先提一下我自己曾经历过多次内存泄露,到底有几次? 我自己心里悲伤的回想了下,造成线上影响的内存泄露事件有将近5次了,没上线就查出内存暴涨次数可能更多。这次不是最惨,相信也不会是最后的内存的泄露。
以前写过一篇关于内存泄露的问题,有兴趣可以瞅瞅,http://xiaorui.cc/?p=3315
有人说,内存泄露对于程序员来说,是个好事,也是个坏事。 怎么说? 好事在于,技术又有所长进,经验有所心得…. 毕竟不是所有程序员都写过OOM的服务…. 坏事当然就是被人吐槽了…. 回想了下被OOM的服务,并发和数据量级都相对大,也就是说,并发量大的服务容易出现OOM…
说的自己都乐了,为毛每次写服务端和客户端的时候,我很大几率会出现内存泄露呢…. 一路走来发现内存暴涨的原因,一般是数据的边界条件处理不合理导致的,而单纯因为某个模块及框架bug代码导致的内存泄露相对少。
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新。 http://xiaorui.cc/?p=4767
废话不多说,简单说下这次的处理过程.
ops的同事给我打电话,说我的服务挂了… 作为肇事者的我说,不应该呀,你再启动下呀? 那哥们说,启动了,一会又死了… 我说,再启动下呀? 一会ops回复说, 又死了… 卧槽呀,这不是个好现象呀….
没办法,哥只能亲自上了…. 首先确认下是什么原因导致的程序总是挂掉, 因为我的服务端是Master Worker设计模式,在顶级的函数入口做了try catch,协程入口也做了try catch,所以程序的逻辑异常肯定不会导致这个进程崩溃的。进程的日志没有特别明显的异常信息…
怀疑是被oom了,dmesg看到的信息果然是被oom了… 那么这里有几个问题:
1- 为什么会被oom
2- 什么时候被oom的,内存持续了多久?
3- oom应该干掉泄露内存的worker进程,为什么把 worker 和 feeds进程都干掉了…
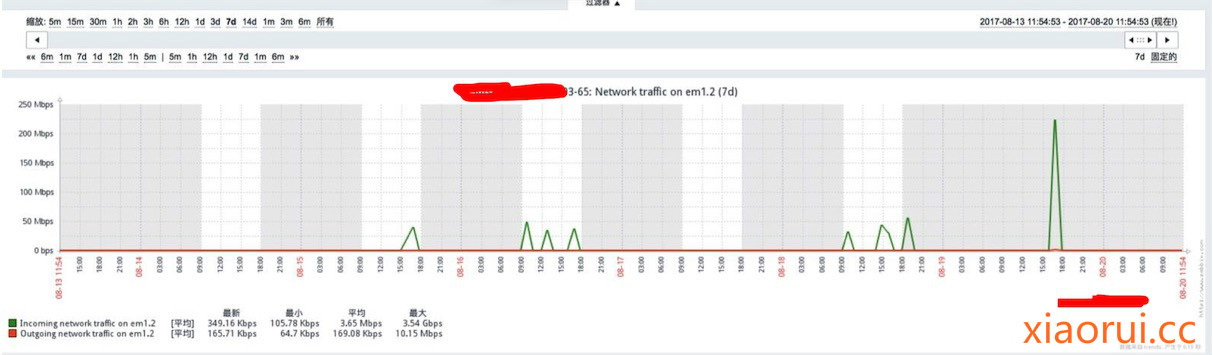
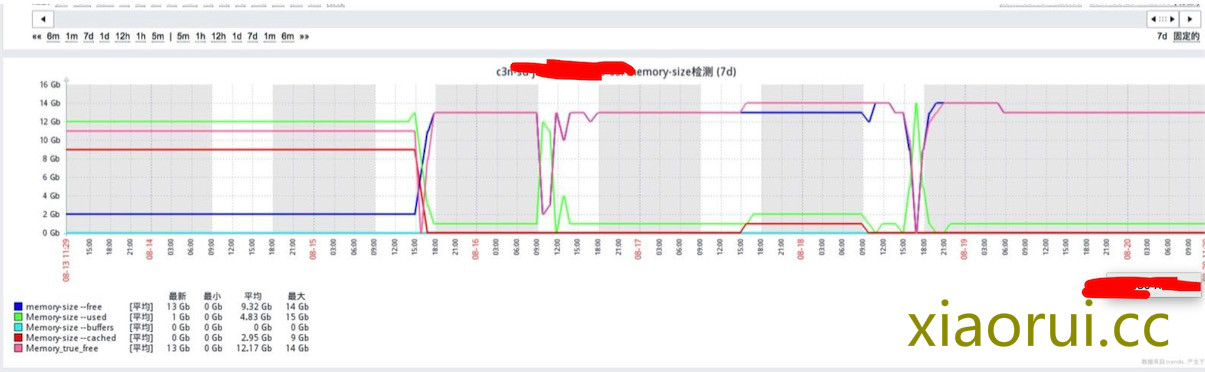
然后我们开始确认下内存的增长趋势,及相关的监控图表。 通过监控服务器的内存图表,我们得知,内存的增长是爆发性的,后期根据我自己的内存监控脚本显示,从500m内存 干到 16G,再到被内核OOM,最快时候一分钟完事。
另外通过流量图表,我们可以找到其影响关系,没次内存暴涨的时候,流量也很高…. 但根据我程序的计算显示qps并不高,但是内存暴增的厉害,流量图徒增的也很厉害… 我这个服务是做全网cdn刷新预缓存的业务,操作cdn只是触发header请求而已,按照道理不会有太大的流量。
这内存暴增的问题不是时常出现的,有可能几天才出现一次。 在内存暴增之后,追问题其实相对麻烦的,只能看日志。 最简单直接的方法是,事故发生时,在线调….. (这需要我时刻关注监控服务情况,第一时间做在线追问题)….
服务上线之前,我们肯定经过疯狂的压力和稳定性测试,但是从来没有出现过内存泄露问题,很是疑惑的…
当遇到问题时,我先通过strace看看有什么不良的系统调用,发现有大量的recvfrom… recvfrom系统调用是用来从socket读取数据的… 为什么会有大量的数据recv呢 ? tcpdump抓包分析出有大量的数据是二进制的…. 但我的服务只是发送http header请求呀…. 通过不断的抓包和iftop流量分析,得出 http get 请求大文件导致的内存暴增问题…
# xiaorui.cc % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 99.56 1.158373 6 189545 recvfrom 0.44 0.005162 0 18301 brk 0.00 0.000000 0 23 read 0.00 0.000000 0 21 write 0.00 0.000000 0 6 open 0.00 0.000000 0 8 close 0.00 0.000000 0 6 fstat 0.00 0.000000 0 10 3 mmap
分析数据得知,明显是二进制…. 正常接口不会出现二进制的数据流…
# xiaorui.cc recvfrom(3, "\207\343c\320fD\0\2014\264\363\rE^\34\350a;\177\322\222[H`n\364\302\315!=\247 "..., 10240, 0, NULL, NULL) = 3358 recvfrom(3, "R,C4\5c\23M\305\225\31&\3\271\364\244\225\36\204\302\304D\237\240\367\315`\331]e\234\345"..., 6882, 0, NULL, NULL) = 6882 recvfrom(3, "\207S\3\312\25\224\3649\202\326[ \375\362\"N\301\334\20F\332f\234\"\2706\321q\361\207w\v"..., 10240, 0, NULL, NULL) = 10240 recvfrom(3, "\214H\303A*\377I,\256\221\316gF4\244\274\234\t\260\265\217\317<\r\307<G=\255A\30\246"..., 10240, 0, NULL, NULL) = 10240 recvfrom(3, "zT\31\2353\177\22*q\26\326\tq\341\274\236\323<Cb\345\10\341NA}7\252\222c\203%"..., 10240, 0, NULL, NULL) = 6218 recvfrom(3, "\224\25\241W$F\233\317\350L\347\244\361[\271\262[^\347\274\333\221\ng\36s\266\324\313Ug\275"..., 4022, 0, NULL, NULL) = 4022 recvfrom(3, "U\341\310\210]w\250C%\2330\375\364R\274\372Z7\263\340\26\331\325\302\224\376\300\260zPy\271"..., 10240, 0, NULL, NULL) = 10240
我们知道大多数cdn厂商给我们开放了不同的http method方法,每个方法有不同的意思…. 除了get请求外,大多请求都是异步的…. 但是get是同步的, 既然是同步的,那么你直接用python requests访问一个大文件,必然是需要把数据载入到内存中…. 对的,内存中…. 就算你只是想看看response的http code,但对于一些http client module来说,还是需要加载完所有buffer才会解析成header….
那么怎么解决? requests 针对一些大文件的get请求 改成 写文件的方式请求… 这样就避免了,你请求了 1G 大小的文件,必须拿到所有数据后,才可以return的逻辑… 你把实时recv到内存,改成append到文件里…. 但这样就好了么? 不,还是会有内存的问题… 当然相比直接gevent requests get 好不少….. 另外,我最后加了手动触发gc,这样内存能得到及时释放,我们知道python gc 是有thold刷新策略的。
我最后的解决方式是什么? 我是采用gevent subprocess调用curl来处理大文件…. 为什么用这么粗暴的方式来系统调用curl来处理…
curl是 c 写的,性能极棒 !!! 针对大文件请求,cpu消耗同比python requests少的多… 有些人说了,处理大文件的请求明显是 io bound,怎么可能浪费cpu呢,这也没有啥cpu bound密集活动呀…. 我们多进程加多协程的框架,协程之间的调度需要资源,http parser需要资源…. requests库纯py写的http parser…. 你访问一两个文件肯定没问题了,但是你高并发去处理这类请求,你python requests总是占用cpu时间,那自然就cpu占用率高了,你高了,自然别人就拿不到时间片调度了,只能等了….. 大家可以做一些量级的测试对比….
为什么某个子进程被oom了,父进程也跟着退出,而且其他进程是友好退出…. 所谓的友好的退出意思是,每个进程也都有任务队列缓冲,当得知要退出时,他会把队列中的数据退还给redis,并且等待正在执行的任务完成后才退出….
问题在于我在父进程做了很多信号的处理,子进程当然继承了父进程的信号处理,当获取不到内存时,会触发SIGINT信号,对的…. 首先是SIGINT,然后才有SIGKILL ( -9 ). 当我收到sigint时,会给一个共享变量配置一个标记,所以其他进程会出现安全退出的情况….
rt_sigaction(SIGINT, {SIG_DFL, [], SA_RESTORER, 0x33efc0f7e0}, {0x4e7de0, [], SA_RESTORER, 0x33efc0f7e0}, 8) = 0
+++ exited with 1 +++
但可能当我自己还没认识到内存不够用,有人向内核申请内存,内核说没有,但是我可以干掉分值最低,占内存最大的进程…. 这就造成了OOM….. sigkill是无法捕获的….
针对子进程由于copy on write继承父进程的信号配置,我们可以在子进程fork之后,再重新初始化信号配置… 这样子进程不管什么原因退出,都不管影响到master主进程, 主进程会定时做子进程轮询,如果某子进程挂了,他会重置一个新内存放在进程池里面…. 这方面借鉴了uwsgi的设计…
END…

