
承接上个话题 … … 本想是切分成上中下章节的,但实在不想过于的拖拉,索性利索点的完成该话题。 mysql分库分表话题整理的有点乱套 ,我那懒散的性格导致这文章居然没有连续性… 大家就这么将就一下吧,辛苦 !
该文章写的有些乱,欢迎来喷 ! 另外文章后续不断更新中,请到原文地址查看更新. http://xiaorui.cc/?p=3923
如何开始在线迁移操作分库分表 ?
这是一个很有意思的话,很多开发,尤其是资深点的开发总是想办法搞成那种 类似 “在线不停服务迁移,动态分库分表” !!! 其实好多朋友,包括我自己经常看一些高质量的技术分享,类似架构公众号那种…. 时不时会提到动态分库分表啥的… 其实真正跟DBA接触了后,才知道停服操作才是最简单粗暴,也是架构师和dba们的最爱… 咱们经常玩的一些应用,时不时也会有维护时间…. 那么他们在维护什么呢 ? 什么样的场景会迫使他们停服来维护升级呢 ?
我想,如果停服进行迁移分库分表,大家都这么怎么做的? 不外乎就是写一个相当健全的导数程序来进行灌数据 … …
那么不停服场景下,如何在线分库分表 ?
同机器:
可以采用十分笨拙的 触发器 + 存储过程(hash) + insert low priority ignore的方式. 原理很简单,我们首先要有个导数的脚本,把数据安卓算法copy过去. 那么问题来了? 更新的咋办? 我们可以用触发器加存储过程的方法.. 触发器只能单纯的监听SQL DML语句,并不能再做复杂的实现,所以可以再套用 存储过程来实现分表的抉择。
上面的方法听起来很是可靠,但我自己没用过该方案,只是听一些社区分享中提过该方案。
跨机器:
如果库表在其他host上 ? 首先确保导数脚本一直在导数,从以前的大表导到分表里。 导数要一直分片导数,不要一下子导太多的数据,另外可以加 insert low priority ignore参数, 好处在于不影响其他客户端的请求.
然后再开发一个扫描更新binlog日志的脚本,也可以逻辑日志。 这样我们可以确保更新的数据也能应用到分表中. 到此为止就是追赶数据一致性的过程.
那么还需要停服么? 一个流在持续不断的写源表,另一个在通过读取binlog不停地导数 ,这时间差会造成数据的不一致性 … 这样到底需不需要停服的问题已经很明确了. 我也只能理解到这程度了… lock tables 锁表命令也是停服的一种 .
在业务层面采取分库分表的手段?
常见的几类分库分表的业务场景. 我这里先提下,虽然业务上可以规避下面的场景,但这次重点是在于 分表的策略… 这里特别感觉 sohu dba 徐长华兄和 58架构师沈剑大神 那学到了不少东西.
第一种:
比如我们拿着用户登陆为例,1 %的需求是通过 where username = xxx and password = xxx ,99 %的请求是通过id 查询账户的相关信息…
这时候如何分表呢 ? 可以按照 id 的方式分表,那么1 %的请求咋办? 跨表查询呗…. 另外加个硬缓存… 当触发用户信息更新时再刷新缓存 。
第二种:
文章帖子 , 他的表结构是这样 article_id , uid , topic , created_on , content, title ,updated_on … 我们的查询主要分两类,一个是根据article_id查询文章, 一个是查询uid下的article_id .
他们之间的比率是 80% vs 20% , 对于这类的场景那么我们需要怎么做? 我们可以从文章id下手, 当数据入库的时候我们根据uid信息来创建article_id , 那么解决了查询用户的所有文章的问题. 那么我怎么定位article_id ? 解决方法是,你创建的文章article_id时,要携带uid信息… 这样你查询article_id时,可以捞出uid所在的库表,然后把article_id相关的其他字段拿出来.
总结一句话,按照用户id来分表,然后文章id携带用户id的信息.
第三种:
好友表, 业务需求是我想知道我的好友? 别人也想知道他的好友? 表设计师这样的, 如 friend(uid, friend_uid, nick )
这样的查询量是 50% 分半的。对于分半查询量的需求,处理起来就容易多了. 可以按照uid和friend_id分别分表,也就是冗余入两份数据,只是索引的范围不一样。 这是典型的空间换时间的处理方法。
第四种:
这次需求是扩展版第二种的需求,不仅仅给是通过文章 id 和 用户uid 查询数据,而且会通过topic类别来查询. 那么现在文章表 article_id , uid , topic , created_on , content, title ,updated_on 产生了三个查询需求。
肿么办 ? article_id 和 uid 可以使用第二种方法来实现 ,那么topic话题查询怎么办? 可以使用第三种方法 再建一批topic维度的索引表 !!!
靠谱点的mysql高可用方案:
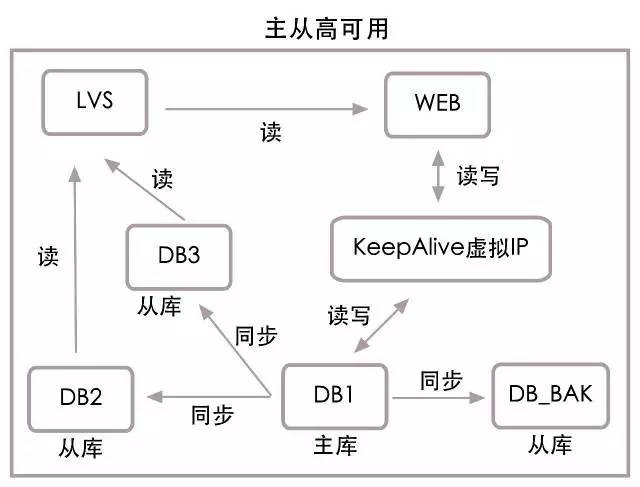
我不再阐述myql各种高可用方案的优缺点了, 我就一句话,别用drbd这类共享存储方案,重要的业务不要采用mysql master双写的设计 . 单纯双向复制是靠谱,配置的时候注意步长,不要同时在两个master进行写入数据。
各大公司的mysql高可用都是采用 mysql 主从对换的方法来实现的。 也就是说,同一时间,只有一个主机是支持写入的,当支持写入的master出问题时候,会选出一个跟keepalived关联的slave mysql提升为master. 如果有多个slave mysql,那么不受影响的。 因为对于用户和其他slave来说,对业务和同步slave mysql来说vip就那么一个…
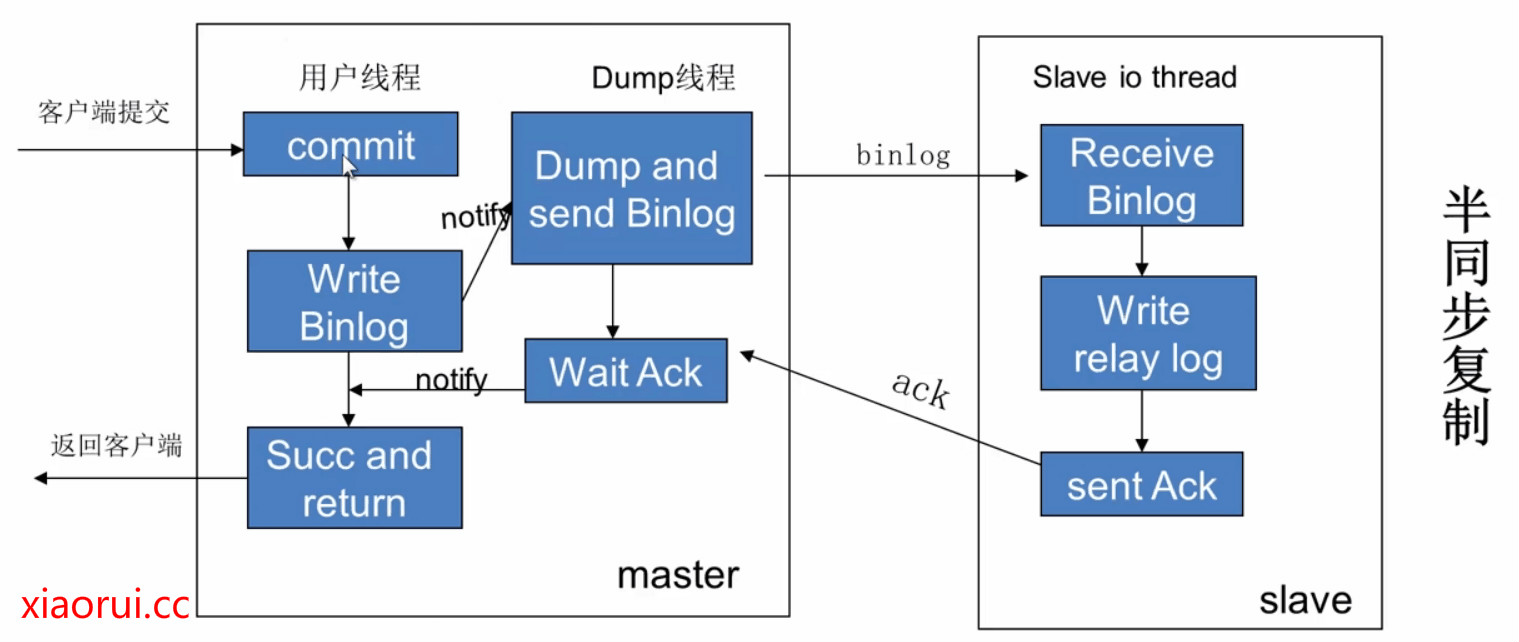
Mysql mha方案原理如此操作的…. 另外如果要保证主备( master \ standby)的角色数据一致性,那么可以根据业务的重要性选择半同步模式….
多个数据中心,也就是所谓的异地多活.
第一 一般来说, 只有一个中心可写, 其余可以同步做备机。
第二 同步的方法可以是主从,或者更主流的通过消息异步写入
我想你肯定会很期待真正的异地多活,也就是多写的方案,如果是这样的架构设计,首先业务层就要做地域的区间,比如类似58同城的地方房屋, 山东青岛那边的人,肯定不会关注东北那边的社区服务。。。 理论是美好的,也是可以执行的,但58的沈剑曾经说过,他们当时是有这么设计架构,后来没有执行的原因是 国内的速度够快了。。。 又你妈不是google那种广度全球的幅度。。。
对于金融支付方面的异地多活,你就别太奢求了. 阿里支付宝天天扯淡最后也抵不过蓝翔技校的挖掘机。。。 支付宝肯定是有多地狱冗余备份的,但为什么没有有效激活异地多活 ? 自己想去吧 .
没写完, 没写完 !!!
END… …


数据库服务我一直推崇的是简单可靠,复杂逻辑不应该在数据库层去实现。
是呀,各大公司的标准也是这样…. 触发器只有dba才能用的,存储过程看情况.
当年,我搞的时候,数据库迁移,主从切换,升级,完全就是停机。我一直觉得数据的一致性最重要,其实,真的没有完全不能停机的服务。
是呀,国内外停服处理还是很正常的. 毕竟数据的一致性太要命了. 我当时写的binlog追数据的服务差点出大事… 不说了,都是泪.
求分享
同求呀