
这篇文章主要是闲扯跨机房日志收集的一些事,后面会很疑惑的分析魅族跨机房\集群的日志是怎么收集存储的? 使用Elasticsearch Tribe Node做es集群的代理? 但这也是个好问题.
对于全网的应用日志收集,我想做过运维的朋友都了解的. 不外乎就那么几种方案,ELK, Flume, Scribe ,flutend, 自主开发的。 但不管怎么说对于跨IDC的日志收集还是个大事,单纯从日志收集来来上其实没啥难度,但外网带宽成本实在是不便宜, 不会让你像内网日志收集那样,随意收集,肯定是需要做日志优化的.
文章写的不是很严谨,欢迎来喷,另外该文后续有更新的,请到原文地址查看更新。
我说下我上家公司的日志是怎么收集的,一般把各个应用会把日志写到本地,当然写之前要对日志进行修剪,在每个数据中心都会有一个日志处理节点,名为log proxy这类的玩意, proxy会把一些相关的日志转成metric记录,然后传送到总的日志中心.
但什么事都要看场景,这边实时的数据会用flume进行定时传输,由flume server直接写入到hadoop集群里,但这没涉及到跨机房… 我这边的建议是,对于有需求的重要日志是可以实时跨机房传输的,每个机房,数据中心都配一组kafka, 每个机器都配一个agent,这个agent有两大功能,一是开始TCP Server模式用来接收日志,另一个是读取本地日志并记录offset。这些开源的logstash、flume都实现了. 日志要分实时日志及离线日志,上面说的是实时日志,关于离线数据就没那么讲究了.
废话说这么多,总的意思就是说跨idc传输日志是个很蛋疼的事情. 受限方面于日志的传输、带宽成本.
前几天看到魅族的分布式日志收集,他们用的elk解决方案,那么他们是怎么解决跨机房日志收集存储问题的?
魅族是使用Elasticserach Tribe来做各个idc elasticsearch集群的代理层. kibana4 只需要把Elasticsearch地址改成tribe就可以了. 有些朋友觉得Nginx location也是可以实现的。 但是Nginx根据Location只能针对index层面进行负载均衡. 另外我发现论坛上不少老外对于Elasticsearch Tribe的性能及功能持否定态度的,貌似Elasticsearch tribe的bug伤了他们.
官方的Elasticsearch tribe node介绍页面有这么一句话,让我很是心凉呀… 这直接否定了前面的Nginx vs Elasticsearch Tribe的看法…
However, there are a few exceptions:
The merged view cannot handle indices with the same name in multiple clusters. By default it will pick one of them, see later for on_conflict options.
Master level read operations (eg Cluster State, Cluster Health) will automatically execute with a local flag set to true since there is no master.
Master level write operations (eg Create Index) are not allowed. These should be performed on a single cluster.
其意思就是说,多个集群下如果有相同索引index的话,他会在多集群中选择一个,貌似又提到 on_conflict这个选项可以解决这类冲突问题. 但问题是 on_conflict在文档在哪里? 在github中已经提交了issuse等待回复.
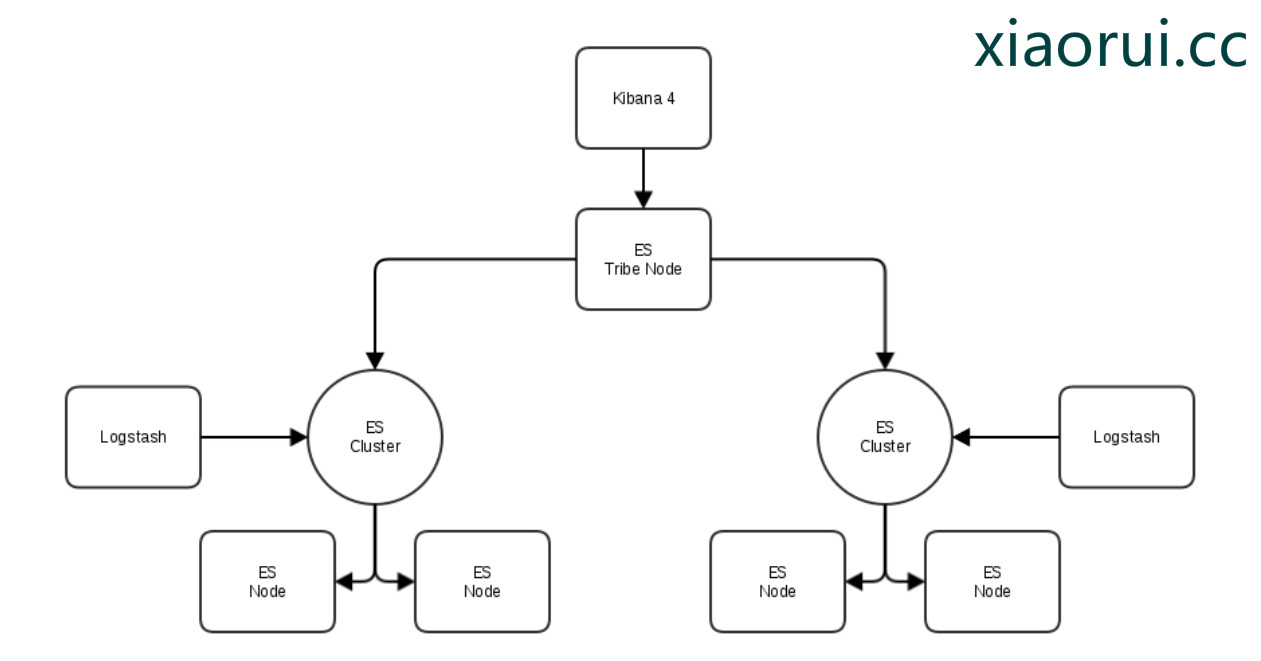
虽然对Elasticsearch的tribe的种种不满,但还是照例说下他的配置.. 这是我google出的一个Elasticsearch Tribe架构图, 看到kibana4是跟Tribe Node相连的.
#blog: xiaorui.cc
tribe:
es1:
cluster.name: cluster1
discovery:
zen:
ping:
multicast:
enabled: false
unicast:
hosts:
- 192.168.111.228:9300
es2:
cluster.name: cluster2
discovery:
zen:
ping:
multicast:
enabled: false
unicast:
hosts:
- 192.168.222.229:9300
总结,
第一 ,我个人认为Elasticsearch更适合那种metric形式的日志。
第二 ,对于tribe node我也是怀疑态度的… tribe 其本身只是做了个结果的merge,官方的文档特别的少,就一个介绍页… 还不如自己用nginx lua来实现数据的merge. 个人看法,勿喷…
END…


说了跟没有一样。。。
对
字符串过滤做的真好… a 标签
上一条的标签被吃了…
加个break-word样式? 跑到旁边去了..
style=”word-wrap:break-word”