
前言
这两天看了百度的张俊在研究基于metric的监控系统,很是感兴趣,也打算在爬虫系统里面组织一套。 那么以前metric的收集用过graphite,看到他有推荐Influxdb数据库,不能简单的说它是数据库,他集成了各种的api和web,还有个很强大的web展现 grafana平台。
那么咱们开发之前,需要对新事物调研一下。前天抽个时间写了个测试程序,是用python写的,启动的时候开启了100个线程。每隔5s中进行插入数据,并读数据。

读数据设计到的SQL语句是group by 聚合,where time > now()-1h 时间间隔的查询,limit 1000的查询。
当然我服务器的性能不行也有关系,没有多余的服务器让我做测试,我找了个openstack的vm主机,4核心,ssd硬盘。 如果单纯的写入,InfluxDB是毫无压力的,不管是cpu好是io,看了文档据说有用 mmap + b tree 。 关于读就有些恶心了,当然也有可能是我读的太过频繁。
5 秒钟做100次的高压力计算的聚合的计算。 官方说 可以用集群的方案来扩展InfluxDB的性能。
数据量其实也就两天的数据,不知道随着天数的增长,速度会不会有所下降。 我昨天测试的时候,查询消耗的时间还在1.5s左右, 现在基本是10s以上。
根据这两天的测试,InfluDB在应用上还比较的合理,API也好用,服务端是采用的GOlang开发的,可以说不会太慢。 但是毕竟Influxdb是一个独立的数据库和服务端的接口,这就意味着 你要单独的维护这些东西。 看需求了,你觉得好就可以了。 我个人还是很推荐使用的。
在并发的情况,开一个终端,去用curl来调用Influxdb的http api,进行针对时间的查询。
[xiaorui@devops ~ ]echo "http://xiaorui.cc"
[xiaorui@devops ~ ] time curl 'http://192.168.3.218:8086/db/example/series?u=root&p=root&q=select%20column_one%20from%20foo%20where%20time%20%3E%272014-12-11%2023%3A10%3A01.232%27%20limit%20100%3B' -H 'Origin: http://192.168.3.218:8083' -H 'Accept-Encoding: gzip, deflate, sdch' -H 'Accept-Language: en-US,en;q=0.8' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36' -H 'Content-Type: application/x-www-form-urlencoded' -H 'Accept: application/json, text/javascript' -H 'Referer: http://192.168.3.218:8083/' -H 'Connection: keep-alive' --compressed
[{"name":"foo","columns":["time","sequence_number","column_one"],"points":[[1418353465140,17675480001,28],[1418353465140,17675470001,82],[1418353441389,17671520001,78],[1418353441389,17671510001,12],[1418353411306,17666600001,90],[1418353411306,17666590001,42],[1418353381446,17661580001,50],[1418353381446,17661570001,12],[1418353359895,17658180001,58],[1418353359895,17658170001,40],[1418353333659,17653780001,44],[1418353333659,17653770001,42],[1418353298292,17648480001,6],[1418353298292,17648470001,74],[1418353270530,17643960001,46],[1418353270530,17643950001,50],[1418353244509,17639560001,78],[1418353244509,17639550001,44],[1418353222806,17636080001,74],[1418353222806,17636070001,20],[1418353194292,17631340001,34],[1418353194292,17631330001,60],[1418353167899,17627120001,86],[1418353167899,17627110001,86],[1418353143736,17622920001,98],[1418353143736,17622910001,0],[1418353121402,17619180001,26],[1418353121402,17619170001,20],[1418353099332,17615680001,40],[1418353099332,17615670001,46],[1418353074248,17611500001,14],[1418353074248,17611490001,76],[1418353051484,17607840001,52],[1418353051484,17607830001,76],[1418353027173,17603780001,10],[1418353027173,17603770001,56],[1418352998881,17599040001,18],[1418352998881,17599030001,88],[1418352975243,17595240001,52],[1418352975243,17595230001,40],[1418352950189,17591060001,54],[1418352950189,17591050001,54],[1418352925905,17586920001,90],[1418352925905,17586910001,12],[1418352900313,17582840001,26],[1418352900313,17582830001,58],[1418352877213,17579040001,78],[1418352877213,17579030001,54],[1418352852173,17574980001,10],[1418352852173,17574970001,32],[1418352825113,17570320001,52],[1418352825113,17570310001,82],[1418352800955,17566320001,58],[1418352800955,17566310001,72],[1418352777718,17562380001,68],[1418352777718,17562370001,16],[1418352754418,17558440001,36],[1418352754418,17558430001,72],[1418352732178,17554820001,18],[1418352732178,17554810001,28],[1418352703294,17550300001,2],[1418352703294,17550290001,46],[1418352674606,17545400001,28],[1418352674606,17545390001,98],[1418352654236,17542120001,82],[1418352654236,17542110001,12],[1418352629530,17537920001,84],[1418352629530,17537910001,0],[1418352602088,17533440001,98],[1418352602088,17533430001,92],[1418352576188,17529040001,94],[1418352576188,17529030001,14],[1418352553324,17525220001,18],[1418352553324,17525210001,78],[1418352522559,17520400001,42],[1418352522559,17520390001,64],[1418352498487,17516380001,58],[1418352498487,17516370001,54],[1418352473669,17512320001,30],[1418352473669,17512310001,66],[1418352450175,17508480001,60],[1418352450175,17508470001,6],[1418352424819,17504380001,14],[1418352424819,17504370001,4],[1418352399424,17500240001,74],[1418352399424,17500230001,70],[1418352371680,17495800001,54],[1418352371680,17495790001,32],[1418352346846,17491620001,38],[1418352346846,17491610001,100],[1418352318730,17486940001,70],[1418352318730,17486930001,50],[1418352295495,17483180001,6],[1418352295495,17483170001,54],[1418352271994,17479220001,64],[1418352271994,17479210001,72],[1418352246613,17474960001,90],[1418352246613,17474950001,42],[1418352224412,17471520001,54],[1418352224412,17471510001,56]]}]curl -H 'Origin: http://192.168.x.x:8083' -H -H -H -H -H -H -H 0.00s user 0.00s system 0% cpu 0.987 total
[xiaorui@devops ~ ]$
这次是针对时间聚合,每10分钟进行一次聚合。
[xiaorui@devops ~ ][xiaorui@devops ~ ] time curl 'http://192.168.3.218:8086/db/example/series?u=root&p=root&q=select%20*%20from%20foo%20group%20by%20time(10m)%20limit%20100%3B' -H 'Origin: http://192.168.3.218:8083' -H 'Accept-Encoding: gzip, deflate, sdch' -H 'Accept-Language: en-US,en;q=0.8' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36' -H 'Content-Type: application/x-www-form-urlencoded' -H 'Accept: application/json, text/javascript' -H 'Referer: http://192.168.3.218:8083/' -H 'Connection: keep-alive' --compressed
[{"name":"foo","columns":["time","sequence_number","column_one","column_two","column_three"],"points":[[1418354492646,17844080001,40,22,82],[1418354492646,17844070001,24,26,30],[1418354467572,17840160001,78,60,66],[1418354467572,17840150001,16,70,22],[1418354438426,17835180001,98,48,36],[1418354438426,17835170001,68,52,4],[1418354413204,17831240001,32,22,0],[1418354413204,17831230001,42,0,50],[1418354390636,17827520001,2,44,56],[1418354390636,17827510001,44,8,14],[1418354368529,17823920001,2,18,100],[1418354368529,17823910001,18,64,12],[1418354342423,17819500001,46,24,8],[1418354342423,17819490001,38,2,54],[1418354321299,17816040001,12,62,0],[1418354321299,17816030001,24,48,46],[1418354295431,17811680001,80,52,86],[1418354295431,17811670001,32,96,96],[1418354270842,17807780001,98,88,74],[1418354270842,17807770001,78,56,58],[1418354245061,17803720001,92,80,4],[1418354245061,17803710001,68,32,78],[1418354219608,17799560001,90,26,54],[1418354219608,17799550001,56,24,14],[1418354192474,17795260001,90,40,34],[1418354192474,17795250001,36,78,60],[1418354163285,17790240001,32,36,14],[1418354163285,17790230001,36,98,86],[1418354134529,17785500001,68,18,90],[1418354134529,17785490001,94,96,8],[1418354106300,17780860001,26,28,20],[1418354106300,17780850001,74,56,94],[1418354076848,17776040001,74,36,6],[1418354076848,17776030001,18,88,30],[1418354052079,17772020001,24,84,96],[1418354052079,17772010001,10,8,8],[1418354022699,17767460001,54,36,42],[1418354022699,17767450001,42,62,26],[1418353993854,17762460001,86,42,36],[1418353993854,17762450001,24,86,74],[1418353971006,17758740001,38,60,46],[1418353971006,17758730001,80,52,12],[1418353943154,17754200001,84,62,74],[1418353943154,17754190001,90,54,4],[1418353916898,17749960001,58,50,38],[1418353916898,17749950001,32,56,84],[1418353892118,17745700001,62,38,38],[1418353892118,17745690001,34,6,28],[1418353869121,17741920001,34,64,18],[1418353869121,17741910001,98,4,42],[1418353847301,17738440001,88,20,48],[1418353847301,17738430001,46,64,70],[1418353819216,17733780001,50,96,10],[1418353819216,17733770001,10,88,52],[1418353792068,17729340001,46,82,48],[1418353792068,17729330001,4,4,100],[1418353769232,17725600001,4,72,58],[1418353769232,17725590001,74,82,32],[1418353746455,17721860001,60,34,38],[1418353746455,17721850001,32,78,6],[1418353722228,17717860001,98,52,28],[1418353722228,17717850001,70,90,28],[1418353700517,17714180001,16,12,34],[1418353700517,17714170001,30,18,28],[1418353673935,17709860001,80,46,90],[1418353673935,17709850001,16,86,56],[1418353651394,17706080001,86,56,34],[1418353651394,17706070001,46,78,90],[1418353620128,17701160001,30,78,6],[1418353620128,17701150001,32,54,10],[1418353593456,17696700001,2,96,44],[1418353593456,17696690001,42,50,84],[1418353565922,17692160001,12,62,24],[1418353565922,17692150001,70,56,24],[1418353542552,17688260001,66,88,6],[1418353542552,17688250001,12,38,70],[1418353520729,17684700001,84,16,12],[1418353520729,17684690001,4,44,72],[1418353492975,17680140001,76,90,56],[1418353492975,17680130001,54,30,86],[1418353465140,17675480001,28,70,24],[1418353465140,17675470001,82,46,8],[1418353441389,17671520001,78,48,32],[1418353441389,17671510001,12,74,28],[1418353411306,17666600001,90,58,96],[1418353411306,17666590001,42,38,84],[1418353381446,17661580001,50,14,30],[1418353381446,17661570001,12,18,22],[1418353359895,17658180001,58,68,72],[1418353359895,17658170001,40,86,8],[1418353333659,17653780001,44,86,42],[1418353333659,17653770001,42,58,84],[1418353298292,17648480001,6,52,86],[1418353298292,17648470001,74,58,80],[1418353270530,17643960001,46,94,56],[1418353270530,17643950001,50,88,46],[1418353244509,17639560001,78,46,38],[1418353244509,17639550001,44,94,28],[1418353222806,17636080001,74,8,60],[1418353222806,17636070001,20,98,22]]}]curl -H 'Origin: http://192.168.3.218:8083' -H -H -H -H -H -H -H 0.00s user 0.00s system 0% cpu 2.172 total
然后再来一个一定时间段的平均时间计算。 在InfluxDB里面叫做mean计算。 这里也是在100个线程的影响力下,测试的结果。
[xiaorui@devops ~ ]time curl 'http://192.168.3.218:8086/db/example/series?u=root&p=root&q=select%20mean(column_one)%20from%20foo%20group%20by%20time(10m)%20limit%20100%3B' -H 'Accept: application/json, text/javascript' -H 'Referer: http://192.168.3.218:8083/' -H 'Origin: http://192.168.3.218:8083' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36' -H 'Content-Type: application/x-www-form-urlencoded' --compressed
[{"name":"foo","columns":["time","mean"],"points":[[1418354400000,53.26315789473684],[1418353800000,51.56521739130433],[1418353200000,46.00000000000001],[1418352600000,49.800000000000004],[1418352000000,53.304347826086946],[1418351400000,49.86666666666666],[1418350200000,48.78571428571427],[1418349600000,48.03571428571428],[1418349000000,44.07142857142857],[1418348400000,48.00000000000001],[1418347800000,50.714285714285715],[1418347200000,48.00000000000001],[1418346600000,49.39285714285713],[1418346000000,46.89285714285713],[1418345400000,57.357142857142875],[1418344800000,56.26666666666667],[1418344200000,50.89655172413791],[1418343600000,52.3448275862069],[1418343000000,47.66666666666666],[1418342400000,49.300000000000026],[1418341800000,50.064516129032256],[1418341200000,49.766666666666666],[1418340600000,49.39999999999999],[1418340000000,43.83333333333336],[1418339400000,51.61290322580646],[1418338800000,48.36666666666668],[1418338200000,47.448275862068975],[1418337600000,46.16666666666665],[1418337000000,46.79999999999998],[1418336400000,46.16666666666668],[1418335800000,50.90322580645161],[1418335200000,51.53333333333333],[1418334600000,51.29032258064516],[1418334000000,46.90322580645163],[1418333400000,46.096774193548406],[1418332800000,49.19354838709677],[1418332200000,47.06451612903229],[1418331600000,46.935483870967744],[1418331000000,54.58064516129032],[1418330400000,47.36363636363638],[1418329800000,53.258064516129046],[1418329200000,47.03030303030301],[1418328600000,50.096774193548384],[1418328000000,45.54545454545453],[1418327400000,55.40624999999999],[1418326800000,52.12500000000001],[1418326200000,47.250000000000014],[1418325600000,47.656249999999986],[1418325000000,44.63636363636363],[1418324400000,53.84848484848485],[1418323800000,46.264705882352935],[1418323200000,52.882352941176464],[1418322600000,52.84848484848485],[1418322000000,48.23529411764705],[1418321400000,57.794117647058805],[1418320800000,55.41176470588237],[1418320200000,49.74285714285713],[1418319600000,52.20588235294115],[1418319000000,43.25714285714284],[1418318400000,53.571428571428555],[1418317800000,51.243243243243235],[1418317200000,46.31428571428571],[1418316600000,53.783783783783804],[1418316000000,43.527777777777764],[1418315400000,47.027027027027],[1418314800000,49.56756756756754],[1418314200000,50.18918918918921],[1418313600000,45.702702702702695],[1418313000000,51.5897435897436],[1418312400000,50.000000000000014],[1418311800000,47.56410256410258],[1418311200000,45.23076923076922],[1418310600000,47.1],[1418310000000,46.871794871794854],[1418309400000,50.79487179487176],[1418308800000,48.68292682926831],[1418308200000,47.82499999999999],[1418307600000,53.42857142857143],[1418307000000,45.19047619047616],[1418306400000,55.02439024390245],[1418305800000,54.619047619047606],[1418305200000,45.76744186046509],[1418304600000,43.48837209302328],[1418304000000,51.0232558139535],[1418303400000,53.68888888888887],[1418302800000,47.177777777777756],[1418302200000,55.326086956521735],[1418301600000,45.41304347826086],[1418301000000,48.38297872340425],[1418300400000,52.531914893617035],[1418299800000,48.458333333333286],[1418299200000,49.957446808510625],[1418298600000,48.65306122448981],[1418298000000,46.2],[1418297400000,49.21568627450983],[1418296800000,48.94117647058825],[1418296200000,52],[1418295600000,48.39999999999999],[1418295000000,45.98039215686272],[1418294400000,50.14545454545451]]}]curl -H 'Accept: application/json, text/javascript' -H -H -H -H 0.00s user 0.01s system 0% cpu 26.431 total
[xiaorui@devops ~ ]
那么我们已经得知了,其实最消耗时间的是 做Aggregate 和 group by time(num m)相关的统计 ,那我们把测试的背景换一下,不用100个线程了,改成20个线程在每隔5秒卡卡嘚读写一次。
结果出来了,0.2s就出来了。有人说INfluxDB在集群的情况下能更好的运算,但是我看到github有人说,他已经把集群的数量加到了5台(我想说,尼玛,来真的呀) ,但是单个任务的速度没有提升,也就是说,他的分布式任务类型 不像hadoop mapreduce那样,会在集群中每个节点设立map池和reduce池,进行同时运算。 InfluxDB更像是mongodb的副本集,在程序逻辑里面做运算 。 详细的集群性能,我还没有时间测试,我估计老外说的 是这么回事。 毕竟像任务分解一致化不好做的,因为InfluxDB还年轻。
[xiaorui@devops ~ ]time curl 'http://192.168.3.218:8086/db/example/series?u=root&p=root&q=select%20mean(column_one)%20from%20foo%20group%20by%20time(10m)%20limit%20100%3B' -H 'Accept: application/json, text/javascript' -H 'Referer: http://192.168.3.218:8083/' -H 'Origin: http://192.168.3.218:8083' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36' -H 'Content-Type: application/x-www-form-urlencoded' --compressed
[{"name":"foo","columns":["time","mean"],"points":[[1418354400000,54.63636363636363],[1418353800000,51.56521739130433],[1418353200000,46.00000000000001],[1418352600000,49.800000000000004],[1418352000000,53.304347826086946],[1418351400000,49.86666666666666],[1418350200000,48.78571428571427],[1418349600000,48.03571428571428],[1418349000000,44.07142857142857],[1418348400000,48.00000000000001],[1418347800000,50.714285714285715],[1418347200000,48.00000000000001],[1418346600000,49.39285714285713],[1418346000000,46.89285714285713],[1418345400000,57.357142857142875],[1418344800000,56.26666666666667],[1418344200000,50.89655172413791],[1418343600000,52.3448275862069],[1418343000000,47.66666666666666],[1418342400000,49.300000000000026],[1418341800000,50.064516129032256],[1418341200000,49.766666666666666],[1418340600000,49.39999999999999],[1418340000000,43.83333333333336],[1418339400000,51.61290322580646],[1418338800000,48.36666666666668],[1418338200000,47.448275862068975],[1418337600000,46.16666666666665],[1418337000000,46.79999999999998],[1418336400000,46.16666666666668],[1418335800000,50.90322580645161],[1418335200000,51.53333333333333],[1418334600000,51.29032258064516],[1418334000000,46.90322580645163],[1418333400000,46.096774193548406],[1418332800000,49.19354838709677],[1418332200000,47.06451612903229],[1418331600000,46.935483870967744],[1418331000000,54.58064516129032],[1418330400000,47.36363636363638],[1418329800000,53.258064516129046],[1418329200000,47.03030303030301],[1418328600000,50.096774193548384],[1418328000000,45.54545454545453],[1418327400000,55.40624999999999],[1418326800000,52.12500000000001],[1418326200000,47.250000000000014],[1418325600000,47.656249999999986],[1418325000000,44.63636363636363],[1418324400000,53.84848484848485],[1418323800000,46.264705882352935],[1418323200000,52.882352941176464],[1418322600000,52.84848484848485],[1418322000000,48.23529411764705],[1418321400000,57.794117647058805],[1418320800000,55.41176470588237],[1418320200000,49.74285714285713],[1418319600000,52.20588235294115],[1418319000000,43.25714285714284],[1418318400000,53.571428571428555],[1418317800000,51.243243243243235],[1418317200000,46.31428571428571],[1418316600000,53.783783783783804],[1418316000000,43.527777777777764],[1418315400000,47.027027027027],[1418314800000,49.56756756756754],[1418314200000,50.18918918918921],[1418313600000,45.702702702702695],[1418313000000,51.5897435897436],[1418312400000,50.000000000000014],[1418311800000,47.56410256410258],[1418311200000,45.23076923076922],[1418310600000,47.1],[1418310000000,46.871794871794854],[1418309400000,50.79487179487176],[1418308800000,48.68292682926831],[1418308200000,47.82499999999999],[1418307600000,53.42857142857143],[1418307000000,45.19047619047616],[1418306400000,55.02439024390245],[1418305800000,54.619047619047606],[1418305200000,45.76744186046509],[1418304600000,43.48837209302328],[1418304000000,51.0232558139535],[1418303400000,53.68888888888887],[1418302800000,47.177777777777756],[1418302200000,55.326086956521735],[1418301600000,45.41304347826086],[1418301000000,48.38297872340425],[1418300400000,52.531914893617035],[1418299800000,48.458333333333286],[1418299200000,49.957446808510625],[1418298600000,48.65306122448981],[1418298000000,46.2],[1418297400000,49.21568627450983],[1418296800000,48.94117647058825],[1418296200000,52],[1418295600000,48.39999999999999],[1418295000000,45.98039215686272],[1418294400000,50.14545454545451]]}]curl -H 'Accept: application/json, text/javascript' -H -H -H -H 0.00s user 0.00s system 4% cpu 0.209 total
[xiaorui@devops ~ ]
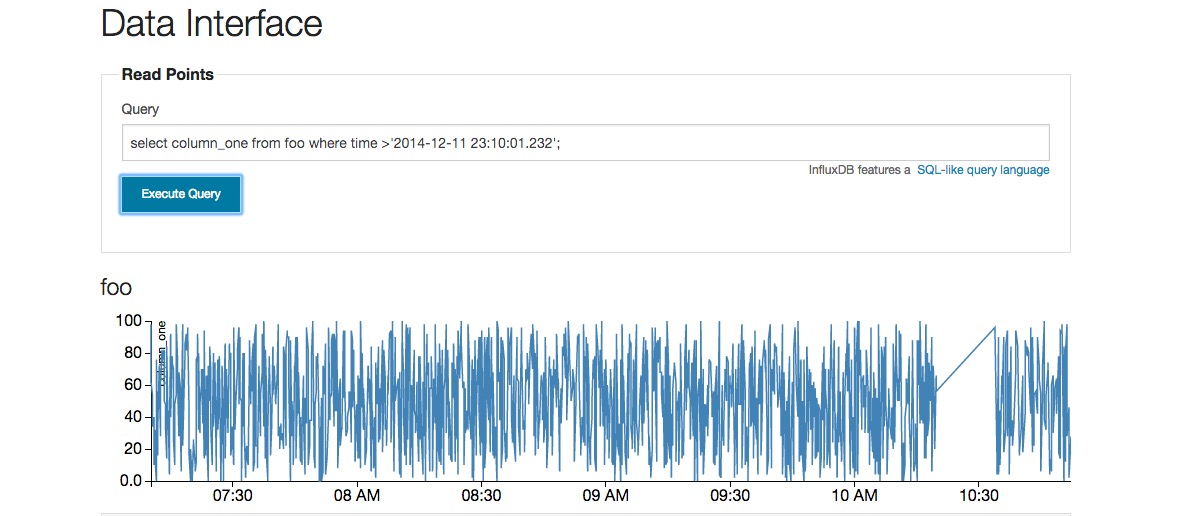
为了怕被别人勿喷,我这里申明下,下面图的结果是 比较大的压力下造成的,换个说法 适合像graphite那样的小型metrics手机场景,再大的场景就有些欠妥了。 我已经把结果发给了官方,让他们给出更好的优化的方法。 看官方的一些说明,貌似就只能是集群了。

这个是批量写入的速度,大家会看到写入还是很理想的。


请教楼主,知道怎么从influxdb中删除某些记录吗,我开始测试的时候用collectd插入了大量value为0的记录,现在想把他们都删掉
可以呀 influxdb不是有文档么DELETE FROM foo WHERE time > ‘2014-06-30’ and time < ‘2014-06-30 15:16:01’
点赞!